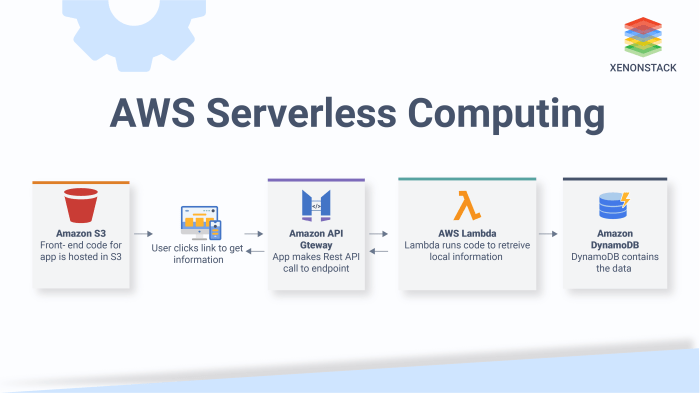
As the realm of serverless computing continues to evolve, the strategic orchestration of APIs becomes increasingly critical. This examination delves into the fundamental role of API composition within serverless architectures, offering a comprehensive understanding of its principles and implications. API composition, at its core, is the art of assembling individual serverless functions to create more complex and functional APIs, thereby unlocking significant benefits in terms of scalability, cost efficiency, and overall system resilience.
This approach contrasts sharply with monolithic applications, paving the way for more flexible and adaptable systems.
This exploration navigates through the core concepts of API composition, examining its role in facilitating microservices architectures and the tools that enable this orchestration. We’ll analyze how API gateways and data transformation techniques contribute to the effective construction of composite APIs. Furthermore, we will discuss crucial considerations such as security, error handling, monitoring, versioning, and cost optimization, ensuring a holistic perspective on the practical implementation of API composition in real-world scenarios.
Finally, we’ll showcase compelling real-world use cases demonstrating the transformative power of API composition.
Introduction to API Composition in Serverless
API composition in serverless architectures presents a powerful paradigm for building and deploying applications. This approach focuses on orchestrating multiple, independently deployable serverless functions (often APIs) to achieve a more complex business outcome. It leverages the inherent scalability and cost-effectiveness of serverless computing while addressing the need for sophisticated application functionality.API composition allows developers to assemble larger applications from smaller, more manageable serverless components.
This modularity promotes code reuse, simplifies maintenance, and accelerates development cycles.
Core Concept of API Composition
API composition, in the serverless context, involves creating new APIs by combining the functionality of existing APIs. These existing APIs, typically implemented as serverless functions, each perform a specific task. The composition layer acts as an orchestrator, coordinating the execution of these functions, transforming data between them, and returning a unified response to the client. This approach allows for the creation of more complex and feature-rich applications without requiring a monolithic architecture.
The composition layer itself can be a serverless function, a service like AWS API Gateway or Azure API Management, or a dedicated orchestration tool.
Definition of API Composition and its Benefits
API composition is the process of combining multiple existing APIs to create a new, more comprehensive API. This new API provides a higher-level abstraction, simplifying the client’s interaction with the underlying services.The key benefits of API composition include:
- Increased Agility: Developers can rapidly build new features by reusing and composing existing API functionalities, reducing development time and accelerating time-to-market.
- Improved Modularity: Applications are broken down into smaller, independent components, making them easier to understand, maintain, and update. This modularity facilitates independent scaling and deployment of individual components.
- Enhanced Reusability: Existing APIs can be reused across multiple applications, reducing code duplication and promoting consistency. This reuse fosters efficiency and reduces the overall development effort.
- Simplified Integration: API composition provides a centralized point of integration, simplifying the interaction with various backend services and reducing the complexity of client applications.
- Abstraction of Complexity: The composition layer abstracts the underlying complexities of multiple APIs, providing a simplified interface for clients.
Advantages of API Composition in Serverless Environments
Serverless environments are particularly well-suited for API composition due to their inherent scalability and cost-effectiveness. API composition leverages these advantages to build applications that are both highly scalable and economically efficient.The advantages include:
- Scalability: Serverless functions automatically scale based on demand. API composition allows each composed API to scale independently, ensuring optimal resource utilization and performance. As the number of requests increases, the underlying serverless functions are automatically scaled to handle the load, ensuring high availability and responsiveness.
- Cost-Effectiveness: Serverless platforms offer a pay-per-use pricing model. With API composition, you only pay for the compute time consumed by each serverless function during the execution of the composed API. This can result in significant cost savings compared to traditional server-based architectures, especially during periods of low traffic.
- Reduced Operational Overhead: Serverless platforms manage the underlying infrastructure, reducing the operational burden on developers. This allows developers to focus on building and deploying application logic rather than managing servers and infrastructure.
- Faster Time-to-Market: The combination of serverless and API composition accelerates development cycles. Developers can quickly assemble new APIs from existing components, enabling faster iteration and quicker deployment of new features.
- Improved Fault Isolation: Because serverless functions are independent, a failure in one function is less likely to impact the entire application. API composition allows for the creation of resilient applications where failures are contained and can be handled gracefully.
Decomposition and Microservices
API composition plays a pivotal role in enabling the transition from monolithic applications to a microservices architecture. This transformation is particularly beneficial within a serverless environment, where the inherent characteristics of serverless computing, such as scalability and pay-per-use pricing, align well with the microservices approach. By breaking down large, complex applications into smaller, independent, and deployable units, API composition simplifies development, deployment, and maintenance.
Facilitating Decomposition
The core function of API composition in decomposing monolithic applications involves identifying distinct functionalities and encapsulating them as independent microservices. These microservices expose APIs that can be orchestrated and combined to deliver the functionality of the original monolithic application. This approach promotes modularity, allowing teams to work independently on different services, leading to faster development cycles and reduced risk of impacting other parts of the system during updates or failures.
- Identifying Service Boundaries: The first step involves analyzing the monolithic application to identify logical service boundaries. This can be based on business capabilities, data domains, or other relevant criteria.
- API Definition and Design: Once service boundaries are defined, APIs for each microservice are designed. These APIs should be well-defined, consistent, and adhere to principles of RESTful design or other suitable architectural styles.
- Implementation and Deployment: Each microservice is implemented and deployed independently. Serverless functions, such as AWS Lambda, Google Cloud Functions, or Azure Functions, are often used to implement the logic behind each API endpoint.
- Orchestration and Composition: API composition tools, such as API gateways or serverless orchestration services (e.g., AWS Step Functions, Azure Durable Functions), are used to orchestrate the execution of multiple microservices and combine their responses.
Orchestrating Serverless Functions
Serverless functions, when combined with API composition techniques, provide a powerful mechanism for creating composite APIs. These composite APIs aggregate data and functionality from multiple underlying microservices, presenting a unified interface to the client. This orchestration can involve sequential execution, parallel processing, or conditional branching, depending on the requirements of the application.
Consider a scenario where a retail application needs to retrieve product details, inventory levels, and customer reviews. Instead of a single monolithic function handling all these tasks, a serverless architecture might employ the following:
- Product Details Service: A serverless function retrieves product details from a product database.
- Inventory Service: A serverless function checks inventory levels from an inventory management system.
- Review Service: A serverless function fetches customer reviews from a review database.
- API Gateway: An API gateway, such as AWS API Gateway, orchestrates these functions. When a client requests product information, the gateway invokes the Product Details Service, the Inventory Service, and the Review Service concurrently. The gateway then aggregates the responses from each service and returns a combined response to the client.
This approach allows for independent scaling of each service. For example, if the Review Service experiences high traffic, it can be scaled independently without affecting the Product Details or Inventory services.
Managing Dependencies Between Microservices
Managing dependencies between microservices in a serverless environment presents unique challenges. Because microservices are designed to be independent, they communicate with each other through APIs. This inter-service communication introduces potential points of failure and requires careful consideration of factors such as network latency, error handling, and data consistency.
Addressing these challenges often involves the following strategies:
- Service Discovery: Mechanisms for service discovery are crucial. Services need to be able to locate and communicate with each other, especially in dynamic environments where service instances may be scaled up or down. Serverless environments often provide built-in service discovery features, or external service discovery solutions can be employed.
- API Versioning: API versioning is essential to manage changes to service interfaces without breaking existing integrations. Proper versioning allows for backward compatibility and graceful transitions between different versions of a service.
- Idempotency: Designing APIs to be idempotent (i.e., executing the same operation multiple times has the same effect as executing it once) is critical for handling retries and ensuring data consistency in the face of network failures.
- Circuit Breakers and Timeouts: Implementing circuit breakers and timeouts helps prevent cascading failures. If a service becomes unavailable, the circuit breaker can automatically stop calling the service for a period, preventing other services from being overwhelmed. Timeouts prevent indefinite waiting for unresponsive services.
- Distributed Tracing: Distributed tracing tools provide visibility into the flow of requests across multiple microservices. This allows for easier debugging and performance monitoring. Tools like AWS X-Ray, Google Cloud Trace, and Jaeger can be integrated into serverless applications to track requests and identify performance bottlenecks.
Orchestration Tools and Technologies
Serverless architecture, while offering scalability and cost-efficiency, often necessitates coordinating multiple functions to fulfill a single business requirement. Orchestration tools address this need by providing a framework to define, manage, and execute complex workflows comprised of serverless functions. These tools offer features like state management, error handling, and conditional branching, crucial for building resilient and reliable serverless applications.
Popular Serverless Orchestration Tools
Several platforms offer robust orchestration capabilities tailored for serverless environments. These tools streamline the development and deployment of orchestrated workflows.
- AWS Step Functions: A fully managed, serverless orchestration service provided by Amazon Web Services (AWS). Step Functions allows developers to coordinate multiple AWS Lambda functions and other AWS services into workflows. It provides visual workflows, state management, error handling, and built-in integrations with various AWS services. Step Functions supports two types of state machines: Standard and Express. Standard state machines are designed for long-running, durable workflows, while Express state machines are optimized for high-volume, short-duration tasks.
- Azure Logic Apps: A cloud service from Microsoft Azure designed for building and running automated workflows that integrate applications, data, services, and systems. Logic Apps provides a visual designer and a library of pre-built connectors to popular services, allowing users to quickly create integrations without writing code. It supports a wide range of triggers, actions, and connectors, enabling the creation of complex workflows that span multiple services.
- Google Cloud Workflows: A fully managed orchestration service on Google Cloud Platform (GCP) that enables users to automate and orchestrate Google Cloud services and HTTP-based APIs. Google Cloud Workflows allows for the creation of serverless workflows using a visual or code-based approach, supporting features like state management, error handling, and built-in integrations with various Google Cloud services. Workflows can be triggered by various events and can orchestrate multiple tasks, including calling serverless functions, interacting with databases, and integrating with third-party services.
Orchestrating APIs from Serverless Functions
Orchestration tools play a crucial role in composing APIs from serverless functions. They act as the central coordinator, defining the sequence of function invocations, handling data transformations, and managing the overall workflow execution. This approach allows developers to build sophisticated APIs by combining the functionality of individual serverless functions.
- Workflow Definition: Orchestration tools use a declarative approach to define workflows. Developers specify the steps involved, the order of execution, and the data flow between functions. This definition can be expressed visually, using a drag-and-drop interface, or through code, such as YAML or JSON.
- Function Invocation: Orchestration tools provide mechanisms to invoke serverless functions. They handle the invocation of functions, passing input data and receiving output data. This includes features like asynchronous invocation, retry mechanisms, and error handling.
- Data Transformation: Orchestration tools often include capabilities for data transformation. They allow developers to transform data between functions, such as mapping data formats, aggregating results, or filtering information.
- Error Handling: Robust error handling is a key feature of orchestration tools. They provide mechanisms to handle errors that may occur during function execution. This includes retry logic, error notifications, and the ability to gracefully recover from failures.
- State Management: Orchestration tools maintain the state of the workflow during execution. This allows them to track the progress of each step, manage variables, and ensure that the workflow can be resumed if interrupted.
Example Workflow: Order Processing with AWS Step Functions
This example illustrates a simplified order processing workflow using AWS Step Functions. The workflow coordinates multiple Lambda functions to handle order placement, payment processing, and inventory updates.
- Trigger: The workflow is triggered by an API Gateway request, which receives the order details.
- Step 1: Validate Order (Lambda Function): This function validates the order details, checking for valid items, quantities, and customer information. If the order is invalid, the workflow terminates with an error.
- Step 2: Process Payment (Lambda Function): This function calls a payment gateway API to process the payment. If the payment fails, the workflow retries the payment process a specified number of times.
- Step 3: Update Inventory (Lambda Function): This function updates the inventory database, reducing the stock levels for the ordered items.
- Step 4: Send Confirmation (Lambda Function): This function sends a confirmation email to the customer.
- Step 5: Complete Workflow: The workflow completes successfully.
The above workflow uses several Lambda functions to implement business logic, which are coordinated by Step Functions. Step Functions handles the state management, error handling, and data flow between the functions. This modular approach allows for easier development, maintenance, and scalability of the API. If the payment processing fails repeatedly, Step Functions can trigger a notification to the operations team.
The visual workflow representation in Step Functions provides a clear understanding of the process and facilitates debugging.
API Gateways and API Composition
API gateways are crucial components in serverless architectures, serving as the entry point for all client requests. They act as a central point of control, managing and routing API calls to various backend services, including serverless functions. This centralized control allows for effective API composition by providing the necessary tools to aggregate, transform, and secure API interactions.
Role of API Gateways in API Composition
API gateways play a pivotal role in enabling API composition within serverless environments. Their primary function is to manage the complexities of interacting with multiple backend services, allowing developers to build more complex and feature-rich applications.API gateways offer several key functionalities that directly support API composition:
- Routing: API gateways route incoming requests to the appropriate backend services based on the request’s path, method, and other criteria. This allows developers to define different routes for different serverless functions or microservices.
- Aggregation: Gateways can aggregate responses from multiple backend services into a single response. This is particularly useful when a client needs data from several sources to fulfill a request, reducing the number of client-server interactions.
- Transformation: API gateways can transform requests and responses to align with the needs of the client or the backend services. This includes data format conversion (e.g., JSON to XML), header manipulation, and request parameter mapping.
- Security: Gateways handle authentication, authorization, and rate limiting to protect backend services from unauthorized access and abuse. This ensures that only authorized clients can access specific APIs and that the system is protected from denial-of-service attacks.
- Monitoring and Logging: API gateways provide monitoring and logging capabilities, allowing developers to track API usage, identify performance bottlenecks, and troubleshoot issues. This is critical for understanding how APIs are being used and for optimizing performance.
API Gateway Features Supporting API Composition
API gateways offer a range of features that directly support API composition, allowing developers to build and manage complex APIs effectively. These features enhance the ability to orchestrate multiple backend services and provide a seamless experience for clients.
- Request Routing and Forwarding: This feature allows the gateway to direct incoming requests to the appropriate backend services based on the request’s path, method, or other criteria. For example, a request to `/products` might be routed to a serverless function that retrieves product details from a database, while a request to `/orders` could be routed to a function that handles order processing.
- Request Transformation: This feature enables the gateway to modify the incoming request before it reaches the backend service. This can involve changing the request’s format, adding or removing headers, or modifying request parameters. For instance, the gateway might transform a request from XML to JSON before forwarding it to a serverless function.
- Response Transformation: This feature allows the gateway to modify the response from the backend service before it is sent back to the client. This can involve changing the response’s format, adding or removing headers, or aggregating data from multiple responses. For example, the gateway might combine data from several serverless functions to provide a consolidated response to the client.
- API Composition with Lambda Authorizers: Serverless API gateways, such as AWS API Gateway, enable custom authorization using Lambda authorizers. This allows for the integration of custom logic to determine if a request should be authorized. This feature is crucial in API composition as it allows to implement complex authorization schemes, such as role-based access control or OAuth 2.0, across multiple backend services.
- API Versioning and Management: API gateways often provide features for managing different versions of an API. This allows developers to make changes to their APIs without breaking existing clients. The gateway can route requests to the appropriate version of the API based on the client’s request.
- Integration with Backend Services: API gateways provide various integration options with different backend services, including serverless functions, HTTP endpoints, and other APIs. This allows developers to easily connect their APIs to the backend services that provide the functionality.
Comparison of API Gateway Options
Different API gateway options offer a variety of features and capabilities, and the best choice depends on the specific needs of the project. The following comparison highlights some of the key differences between three popular API gateway options: AWS API Gateway, Azure API Management, and Google Cloud API Gateway.
| Feature | AWS API Gateway | Azure API Management | Google Cloud API Gateway |
|---|---|---|---|
| Platform Integration | Deeply integrated with AWS services (e.g., Lambda, DynamoDB). | Seamlessly integrates with Azure services (e.g., Azure Functions, Cosmos DB). | Fully integrated with Google Cloud services (e.g., Cloud Functions, Cloud Storage). |
| API Composition Capabilities | Supports routing, transformation, aggregation, and custom authorizers. | Offers policy-based transformation, routing, and API aggregation. | Provides routing, transformation, and integration with other Google Cloud services. |
| Developer Experience | Provides a user-friendly console for creating and managing APIs. Supports Infrastructure as Code (IaC) with tools like AWS CloudFormation and Terraform. | Offers a developer portal for API documentation, testing, and monitoring. Supports IaC with Azure Resource Manager templates. | Provides a console and supports IaC with tools like Terraform and Google Cloud Deployment Manager. Offers OpenAPI specification support. |
| Security Features | Supports authentication, authorization, rate limiting, and protection against common attacks. | Offers robust security features, including authentication, authorization, and threat protection. | Provides authentication, authorization, and integration with Google Cloud’s security services. |
| Pricing Model | Pay-per-use pricing based on the number of API calls and data transfer. | Consumption-based pricing and fixed pricing tiers based on features and capacity. | Pay-per-use pricing based on the number of API calls and data transfer. |
| Use Cases | Ideal for building serverless APIs, microservices, and web applications on AWS. | Suitable for managing APIs across different services and organizations on Azure. | Best for building APIs for cloud-native applications and microservices on Google Cloud. |
For example, consider an e-commerce platform. Using AWS API Gateway, an API might route requests for product details to a Lambda function retrieving data from DynamoDB, while another Lambda function handles customer reviews, and a third handles inventory updates. The gateway would transform and aggregate these responses before returning them to the client. Similarly, Azure API Management could be used to compose an API that integrates several Azure Functions, such as one for order processing and another for payment validation, with the gateway managing the routing, transformation, and security.
Finally, Google Cloud API Gateway can facilitate API composition by routing requests to Cloud Functions for various tasks like user authentication, data retrieval from Cloud SQL, and image processing using Cloud Storage. The choice depends on the existing cloud infrastructure and the specific needs of the API.
Data Transformation and Aggregation

Data transformation and aggregation are critical components in API composition within serverless architectures. As serverless functions often operate on disparate data sources and produce outputs in varying formats, the ability to manipulate and combine this data into a cohesive and usable form is essential for providing meaningful services to consumers. This process enables the creation of complex APIs that seamlessly integrate data from multiple backend systems, ultimately enhancing the functionality and value delivered by the serverless application.
Importance of Data Transformation and Aggregation in API Composition
The effective transformation and aggregation of data are crucial for several reasons:
- Data Format Consistency: Serverless functions may return data in different formats (e.g., JSON, XML, CSV). Transformation ensures a consistent format for the API consumer.
- Data Enrichment: Combining data from multiple sources allows for the enrichment of information, providing a more comprehensive view.
- Data Reduction: Aggregation can reduce the volume of data returned to the client, improving performance and efficiency.
- Business Logic Implementation: Transformations can encapsulate business rules, calculations, and data validations within the API layer.
- Abstraction of Backend Complexity: Hiding the complexity of the underlying data sources from the API consumer, providing a simplified interface.
Methods for Transforming Data Between Serverless Functions
Several methods can be employed for transforming data between serverless functions:
- JSONata: JSONata is a powerful query and transformation language for JSON data. It allows for complex data manipulation using declarative expressions.
- Custom Code (e.g., JavaScript, Python): Writing custom code within the serverless function provides flexibility for complex transformations and integration with external libraries.
- Mapping Tools within API Gateways: Some API gateways offer built-in mapping tools or integrations with data transformation services.
- Message Queues and Event-Driven Architectures: Using message queues like AWS SQS or Kafka, functions can publish data, and other functions can subscribe and transform the data asynchronously.
JSONata is particularly useful for its concise syntax and efficiency in processing JSON documents. For example, consider the following JSON payload returned by a serverless function:
"orderId": "12345", "customer": "customerId": "CUST001", "name": "John Doe", "email": "[email protected]" , "items": [ "itemId": "ITEM001", "quantity": 2, "price": 10.00 , "itemId": "ITEM002", "quantity": 1, "price": 25.00 ]
A JSONata expression to calculate the total order value could be:
$sum(items.quantity- items.price)
This expression would return 45.00. The advantage of JSONata is that it can be integrated directly within serverless functions or API gateway configurations, enabling efficient data manipulation.
Scenario: Aggregating Data from Multiple Serverless Functions
Consider a scenario where a serverless application needs to retrieve order details, customer information, and product descriptions. These data elements are managed by separate serverless functions:
- Function 1: Retrieves order details (order ID, customer ID, item IDs).
- Function 2: Retrieves customer information (customer ID, name, email).
- Function 3: Retrieves product descriptions (item ID, product name, price).
The following transformation steps would be necessary to aggregate this data into a single response:
- Function 1 Output (Order Details): This function returns a JSON object containing the order ID, customer ID, and a list of item IDs.
- Function 2 Invocation (Customer Information): Function 1 invokes Function 2, passing the customer ID from the order details. Function 2 returns the customer’s name and email.
- Function 3 Invocation (Product Descriptions): Function 1 iterates through the item IDs and invokes Function 3 for each item ID. Function 3 returns the product name and price for each item.
- Data Aggregation and Transformation: Within Function 1, the data from Functions 2 and 3 is aggregated. JSONata or custom code can be used to transform the data into a unified JSON response, combining order details, customer information, and product descriptions.
- Output Format: The final output from Function 1 might look like this:
"orderId": "12345", "customer": "name": "John Doe", "email": "[email protected]" , "items": [ "itemId": "ITEM001", "productName": "Widget", "price": 10.00, "quantity": 2 , "itemId": "ITEM002", "productName": "Gadget", "price": 25.00, "quantity": 1 ]
This aggregated response provides a comprehensive view of the order, combining data from multiple serverless functions into a single, coherent payload.
This scenario demonstrates the power of data transformation and aggregation in creating complex, user-friendly APIs within a serverless architecture.
Security Considerations
API composition in serverless environments introduces a complex security landscape. The distributed nature of serverless architectures, coupled with the reliance on third-party services and the ephemeral nature of function executions, presents unique challenges. Effective security strategies are critical to protect sensitive data, prevent unauthorized access, and maintain the integrity of the composite API.
Security Implications of API Composition
API composition amplifies security risks inherent in serverless deployments. The increased attack surface, arising from multiple interconnected services, requires careful consideration. Vulnerabilities in one component can cascade, potentially compromising the entire system.The following implications require focused attention:
- Increased Attack Surface: A composite API, by its very nature, exposes multiple endpoints, each potentially vulnerable to attacks. The more services involved, the larger the attack surface.
- Complex Authentication and Authorization: Managing authentication and authorization across multiple serverless functions and services becomes significantly more complex. Ensuring consistent and secure access control requires robust mechanisms.
- Data Exposure Risks: Data flowing between services within a composite API is vulnerable to interception and manipulation. Securing data in transit and at rest is paramount.
- Dependency Management: The reliance on third-party services and libraries introduces vulnerabilities. Regular vulnerability scanning and patching are essential.
- Monitoring and Logging Challenges: The distributed nature of serverless makes it challenging to monitor security events and identify potential threats. Centralized logging and comprehensive monitoring are crucial.
Securing Composite APIs
Securing composite APIs necessitates a multi-layered approach encompassing authentication, authorization, and rate limiting. Implementing these measures effectively requires careful planning and execution.
- Authentication: Authentication verifies the identity of the user or application accessing the API. Several methods can be employed:
- API Keys: Simple and commonly used, but vulnerable if keys are compromised. API keys are suitable for internal communications.
- JSON Web Tokens (JWT): A standard for securely transmitting information between parties as a JSON object. JWTs are widely supported and enable stateless authentication.
- OAuth 2.0: An open standard for access delegation, allowing users to grant third-party access to their data without sharing their credentials. OAuth 2.0 is used for delegated access.
- Authorization: Authorization determines what resources an authenticated user or application is permitted to access. Implement role-based access control (RBAC) or attribute-based access control (ABAC) to manage permissions.
- Rate Limiting: Rate limiting protects APIs from abuse, such as denial-of-service (DoS) attacks and excessive resource consumption. This is usually implemented at the API gateway level.
- Token Bucket Algorithm: Allows a certain number of requests per unit of time.
- Leaky Bucket Algorithm: Similar to token bucket, but allows requests to be processed at a constant rate.
- Input Validation: Validate all incoming data to prevent injection attacks (e.g., SQL injection, cross-site scripting). Use schema validation to ensure data conforms to expected formats.
- Encryption: Encrypt sensitive data in transit (using HTTPS/TLS) and at rest (using encryption keys).
- Regular Security Audits: Conduct regular security audits and penetration testing to identify vulnerabilities and ensure the effectiveness of security measures.
Designing a Security Strategy
A robust security strategy for composite APIs in serverless environments requires a holistic approach. It should be designed to address the unique challenges posed by the distributed nature of serverless architectures.A well-designed security strategy should incorporate the following best practices:
- Centralized API Gateway: Employ an API gateway as the central point of entry for all API requests. The API gateway can handle authentication, authorization, rate limiting, and other security-related functions.
- Identity and Access Management (IAM): Implement a robust IAM system to manage user identities, roles, and permissions. This should integrate with the API gateway and serverless functions.
- Least Privilege Principle: Grant serverless functions only the minimum permissions necessary to perform their tasks. This minimizes the impact of a potential security breach.
- Secure Communication: Enforce HTTPS/TLS for all communication between clients, API gateways, and serverless functions.
- Logging and Monitoring: Implement comprehensive logging and monitoring to track API usage, detect suspicious activity, and respond to security incidents.
- Automated Security Testing: Integrate security testing into the CI/CD pipeline to identify and address vulnerabilities early in the development process.
- Regular Updates and Patching: Regularly update and patch all dependencies, including serverless function runtimes, libraries, and third-party services, to address known vulnerabilities.
- Secrets Management: Securely store and manage sensitive information such as API keys, database credentials, and encryption keys. Utilize a secrets management service.
Consider a scenario where an e-commerce platform builds a composite API to handle user orders. The API is composed of serverless functions for order creation, payment processing, inventory updates, and shipping notifications. A security strategy would include the following:
- Authentication: Users authenticate using JWTs issued after successful login.
- Authorization: RBAC is implemented, with roles like “customer,” “administrator,” and “warehouse_staff.”
- API Gateway: An API gateway handles authentication, authorization, rate limiting, and request routing.
- Secrets Management: API keys for payment processing are stored in a secrets management service.
- Monitoring: Comprehensive logging and monitoring are in place to detect and respond to suspicious activities, such as brute-force login attempts or unusual API usage patterns.
Error Handling and Resilience
API composition in serverless architectures, while offering numerous benefits, introduces complexities in managing errors and ensuring system resilience. The distributed nature of serverless functions and the interactions between them create multiple points of failure. Robust error handling and retry mechanisms are essential to maintain service availability, data integrity, and a positive user experience. Failure to address these aspects can lead to cascading failures, data corruption, and significant downtime.
Importance of Error Handling and Resilience
Effective error handling and resilience are paramount for several reasons in API composition within a serverless environment. The inherent characteristics of serverless, such as the distributed execution model and reliance on external services, amplify the potential for failures.
- Increased Failure Points: Composed APIs involve multiple serverless functions and potentially numerous external services. Each component represents a potential point of failure. If one function fails, it can impact the entire API’s functionality.
- Data Integrity: Errors can lead to inconsistent or corrupted data. Without proper error handling, partial transactions might be committed, leaving the system in an unstable state. For example, an API updating customer information might succeed in updating the name but fail to update the address, leading to incorrect data.
- Service Availability: Resilience mechanisms ensure that the API remains available even when individual components fail. Retries, circuit breakers, and fallback strategies minimize downtime and maintain service continuity.
- User Experience: Errors should be handled gracefully to provide informative error messages and prevent a poor user experience. Instead of a generic error, users should receive clear explanations and, if possible, actionable steps to resolve the issue.
- Cost Optimization: Properly designed error handling and retry mechanisms can prevent unnecessary invocations of serverless functions, thereby reducing costs. For example, a failed database connection should not trigger multiple function invocations if a retry is already in progress.
Methods for Implementing Error Handling and Retry Mechanisms
Implementing robust error handling and retry mechanisms in serverless workflows involves a combination of strategies at different levels of the API composition. These methods ensure that failures are handled gracefully and the system recovers automatically whenever possible.
- Error Detection and Classification: The first step is to detect and classify errors. This involves identifying the types of errors that can occur, such as network errors, service unavailable errors, and validation errors. Errors can be categorized based on their severity and origin to determine the appropriate handling strategy.
- Retry Mechanisms: Retry mechanisms are used to automatically re-attempt failed operations. Retry policies should be carefully designed to avoid overwhelming downstream services. Common retry strategies include:
- Fixed Delay: Retries after a fixed time interval.
- Exponential Backoff: Increases the delay between retries exponentially. This is particularly useful for handling transient errors.
- Jitter: Adds a random delay to the retry interval to prevent all retries from occurring simultaneously.
- Circuit Breakers: Circuit breakers are used to prevent cascading failures. When a service repeatedly fails, the circuit breaker “opens,” preventing further requests from being sent to the failing service. After a period, the circuit breaker “closes” and allows requests to pass through to check if the service has recovered.
- Fallback Mechanisms: Fallback mechanisms provide alternative actions when an operation fails. This might involve using cached data, providing a degraded service, or returning a default response. For example, if a database query fails, the API could retrieve data from a cache.
- Dead-Letter Queues (DLQs): DLQs are used to store messages that could not be processed successfully. This allows for later investigation and manual intervention to handle the errors. DLQs are commonly used in asynchronous workflows where a function processing a message fails.
- Monitoring and Alerting: Comprehensive monitoring and alerting are essential for identifying and responding to errors. Metrics such as error rates, latency, and the number of retries should be monitored. Alerts should be configured to notify operators when critical errors occur.
Demonstration of Error Handling and Retries using a Chosen Orchestration Tool
This section provides a practical demonstration of error handling and retries using AWS Step Functions, a popular orchestration tool for serverless workflows. The example showcases how to implement a retry mechanism for a serverless function that interacts with an external service.
Scenario: A workflow is designed to process customer orders. One of the steps involves calling a serverless function to update the order status in a database. The database service may be temporarily unavailable. This example shows how to use AWS Step Functions to handle such transient failures.
Step Function Definition (JSON):
"StartAt": "UpdateOrderStatus", "States": "UpdateOrderStatus": "Type": "Task", "Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:updateOrderStatusFunction", "Retry": [ "ErrorEquals": [ "States.TaskFailed", "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException" ], "IntervalSeconds": 2, "MaxAttempts": 3, "BackoffRate": 2 ], "Next": "OrderProcessed" , "OrderProcessed": "Type": "Succeed"
Explanation:
- `StartAt`: Specifies the first state to execute, which is “UpdateOrderStatus.”
- `UpdateOrderStatus`: A task state that invokes a Lambda function responsible for updating the order status.
- `Resource`: The Amazon Resource Name (ARN) of the Lambda function.
- `Retry`: Defines the retry policy.
- `ErrorEquals`: Specifies the error types to retry. This includes common Lambda and service-related exceptions.
- `IntervalSeconds`: The initial delay before the first retry.
- `MaxAttempts`: The maximum number of retries.
- `BackoffRate`: The multiplier for the delay between retries. A backoff rate of 2 doubles the delay after each retry.
- `Next`: Indicates the next state to transition to if the task succeeds.
- `OrderProcessed`: A success state that indicates the workflow has completed successfully.
How it Works:
- The Step Function starts and invokes the “updateOrderStatusFunction” Lambda function.
- If the Lambda function fails with an error specified in the `ErrorEquals` array (e.g., a database connection error), the Step Function automatically retries the function.
- The retries occur with a delay, which increases with each attempt based on the `BackoffRate`.
- If the function succeeds within the retry limit, the workflow continues to the “OrderProcessed” state.
- If the function fails after the maximum number of retries, the Step Function will typically transition to a failure state (which is not explicitly defined in this example but could be handled with further error handling).
Illustrative Data:
Imagine the `updateOrderStatusFunction` fails with a database connection error on the first attempt. The Step Function waits for 2 seconds and retries. If the database is still unavailable, it retries again after 4 seconds (2 seconds
– 2). Finally, it retries a third time after 8 seconds (4 seconds
– 2). If the database is back online during any of these retries, the function succeeds, and the workflow continues.
If the function fails all three times, the workflow transitions to a failure state. The orchestration tool’s console allows for easy monitoring of these retries, displaying the number of attempts, the error messages, and the time elapsed during each step.
Monitoring and Logging

Effective monitoring and logging are crucial for the operational health and maintainability of composite APIs within a serverless architecture. They provide visibility into the performance, health, and behavior of individual services and the overall system. Without these capabilities, identifying and resolving issues, optimizing performance, and ensuring security become significantly more challenging.
Significance of Monitoring and Logging
Monitoring and logging serve several critical functions in the context of API composition. They allow for proactive issue detection, performance optimization, and security incident response. Detailed logs and real-time monitoring dashboards empower developers and operations teams to quickly diagnose problems, identify bottlenecks, and understand the impact of changes.
Monitoring the Performance of Composite APIs
Monitoring the performance of composite APIs involves tracking various metrics to identify potential issues and areas for improvement. This is achieved through a combination of techniques, including distributed tracing, service-level objectives (SLOs), and detailed performance dashboards.
- Service-Level Objectives (SLOs): SLOs define the expected performance of the composite API. These objectives are measurable targets, such as the percentage of successful requests within a specific timeframe (e.g., 99.9% success rate over a 30-day period) or the average response time. Monitoring systems track the API’s performance against these SLOs, providing alerts when thresholds are breached.
- Distributed Tracing: Distributed tracing systems, such as Jaeger, Zipkin, or AWS X-Ray, track the flow of a request as it traverses multiple microservices. This enables detailed analysis of individual service performance, including request latency, dependencies, and error rates. Distributed tracing provides valuable insights into performance bottlenecks and allows for pinpointing the root cause of issues within a complex, composite API. The information can be visualized in service dependency graphs, where each service is a node, and the edges represent the calls between them, including latency data.
- Performance Dashboards: Dashboards aggregate key performance indicators (KPIs) and provide a real-time view of the API’s health and performance. These dashboards display metrics such as request volume, error rates, latency, and resource utilization. They also allow for the correlation of metrics across different services, helping to identify performance degradation or anomalies. Dashboards can include visual representations of the data, such as time-series graphs and histograms, allowing for a more intuitive understanding of the API’s behavior.
Logging Strategy for a Composite API
A robust logging strategy is essential for capturing detailed information about the behavior of a composite API. This strategy should encompass a standardized format, centralized log aggregation, and a focus on capturing key metrics.
- Standardized Log Format: Implementing a consistent log format across all services ensures that logs are easily parsed and analyzed. This often involves using a structured format like JSON, which allows for efficient querying and filtering. Each log entry should include essential information such as timestamp, service name, request ID (for tracing), log level (e.g., INFO, WARNING, ERROR), and relevant context information.
- Centralized Log Aggregation: Centralizing logs from all services into a single location, such as an ELK stack (Elasticsearch, Logstash, Kibana), Splunk, or cloud-specific logging services (e.g., AWS CloudWatch Logs, Google Cloud Logging, Azure Monitor), is crucial for effective analysis. This allows for querying and analyzing logs across the entire system, identifying patterns and trends that would be difficult to detect otherwise. Log aggregation also simplifies auditing and security investigations.
- Key Metrics to Track: Identifying and tracking specific metrics provides valuable insights into the performance and health of the API.
- Request Volume: Track the number of requests received by each service and the overall composite API. This metric provides a baseline for understanding traffic patterns and identifying potential capacity issues.
- Error Rates: Monitor the percentage of requests that result in errors (e.g., 500-level HTTP status codes). High error rates can indicate underlying problems within the system. For instance, a sustained increase in 500 errors on a specific microservice may indicate a resource exhaustion issue.
- Latency: Measure the time it takes for requests to be processed, from start to finish. This includes the time spent in each service and the overall latency of the composite API. High latency can negatively impact user experience. For example, a composite API that takes more than 3 seconds to respond may result in users abandoning the application.
- Success Rate: Calculate the percentage of successful requests (e.g., 200-level HTTP status codes). A decreasing success rate suggests that something is impacting the ability of the API to respond successfully.
- Dependencies and External Services: Log the performance of dependencies and external services called by the composite API, including their latency and error rates.
- Resource Utilization: Monitor resource usage, such as CPU, memory, and network bandwidth, for each service. This information is essential for identifying resource bottlenecks and optimizing resource allocation.
- Business Metrics: Capture relevant business metrics, such as the number of transactions processed, revenue generated, or user engagement. These metrics help to understand the impact of the API on business outcomes.
Versioning and API Evolution
Evolving APIs is a critical aspect of serverless architecture, particularly when dealing with API composition. Serverless functions, due to their independent deployment and scaling capabilities, necessitate robust versioning strategies to maintain backward compatibility and prevent service disruptions. This section explores the challenges, methods, and design considerations involved in managing API versions in a serverless environment.
Challenges of Versioning and Evolving Composite APIs
Evolving a composite API presents several unique challenges. Changes to underlying serverless functions can impact the entire composite API, necessitating careful planning and execution.
- Backward Compatibility: Maintaining backward compatibility is paramount. Breaking changes in underlying functions can break existing client applications. Careful versioning and migration strategies are essential.
- Dependency Management: Composite APIs often rely on numerous serverless functions, each potentially with its own version. Managing these dependencies and ensuring consistency across versions is complex.
- Deployment Complexity: Deploying new versions of serverless functions and updating the composite API to utilize them requires careful orchestration to minimize downtime and ensure smooth transitions.
- Testing and Validation: Thorough testing is crucial to ensure that changes to underlying functions do not negatively impact the composite API. This includes testing across different API versions.
- Communication and Coordination: Effective communication between development teams is crucial to manage API evolution and avoid conflicts. Proper documentation and change management processes are vital.
Methods for Managing Different Versions of Serverless Functions
Several methods can be employed to manage different versions of serverless functions, each with its own advantages and disadvantages. The choice of method depends on the specific requirements of the API and the level of control desired.
- Versioning in Function Code: Implement versioning directly within the function code. This involves adding version identifiers to the function’s endpoint or request parameters. This allows for multiple versions of the same function to coexist. However, it can increase code complexity.
- Deploying Multiple Function Versions: Deploy multiple versions of the serverless function simultaneously. API gateways can then be configured to route traffic to the appropriate version based on headers, URL paths, or other criteria. This provides flexibility but requires careful management of deployments.
- Using Aliases: Many serverless platforms support aliases, which act as pointers to specific function versions. Aliases can be updated to point to newer versions, enabling a gradual rollout of changes. This simplifies traffic management and rollback procedures.
- Blue/Green Deployments: Implement blue/green deployments, where the new version (green) is deployed alongside the existing version (blue). Traffic is gradually shifted from the blue environment to the green environment. This minimizes downtime and allows for easy rollback.
Designing a Versioning Strategy for a Composite API, Considering Backward Compatibility
A well-defined versioning strategy is crucial for the long-term maintainability and success of a composite API. The strategy should prioritize backward compatibility to minimize disruption to existing clients.
- Versioning Scheme: Adopt a semantic versioning scheme (e.g., `v1.0`, `v1.1`, `v2.0`). This scheme clearly communicates the nature of changes (major, minor, patch).
- API Gateway Configuration: Utilize an API gateway to manage API versions and route traffic appropriately. Configure the gateway to support different versions based on URL paths, headers, or custom routing rules.
- Backward Compatibility Focus: Design new versions to be backward compatible whenever possible. Avoid breaking changes in existing API contracts. If breaking changes are unavoidable, clearly communicate them in the API documentation and provide migration guides.
- Gradual Rollouts: Implement gradual rollouts using techniques like canary releases or weighted traffic distribution. This allows for testing new versions in production with a limited user base before a full deployment.
- Deprecation Policies: Define a clear deprecation policy for older API versions. Communicate the deprecation timeline and provide sufficient notice to clients to migrate to newer versions.
- Monitoring and Logging: Implement robust monitoring and logging to track API usage, identify errors, and monitor the performance of different API versions. This data is crucial for making informed decisions about API evolution.
- Documentation: Maintain comprehensive and up-to-date API documentation that clearly describes each API version, its features, and any breaking changes. Use tools like OpenAPI (Swagger) to automate documentation generation.
- Example of a Versioning Strategy in Action: Consider an e-commerce platform with a composite API for product catalog. The API has a `v1` version. A new feature, such as product recommendations, is added. A new version, `v2`, is created. Clients that do not require recommendations continue to use `v1`.
Clients that need the new feature migrate to `v2`. This example showcases how new functionalities can be added without affecting the existing clients, maintaining backward compatibility.
Cost Optimization

API composition in serverless architectures presents unique opportunities and challenges regarding cost management. The inherent pay-per-use model of serverless functions allows for granular control over expenses, but the distributed nature of composed APIs introduces complexities that must be carefully addressed to prevent cost overruns. Effective cost optimization requires a multi-faceted approach, encompassing careful function design, strategic orchestration, and diligent monitoring.
Impact of API Composition on Serverless Application Costs
The cost of a serverless application built with API composition is directly influenced by several factors, including the number of function invocations, the duration of execution (memory allocation and execution time), the amount of data transferred, and the complexity of the composition logic. The more functions involved in a composed API, the higher the potential cost, especially if functions are poorly optimized or frequently invoked.
Moreover, the overhead associated with inter-function communication, such as network latency and data serialization/deserialization, contributes to both execution time and overall expenses. Unoptimized composition can lead to a cascading effect, where inefficiencies in one function propagate through the entire API, increasing the cost footprint.
Strategies for Optimizing Serverless Function Invocations
Optimizing serverless function invocations is crucial for controlling costs within a composed API. Several strategies can be employed to achieve this goal:
- Function Granularity: Fine-grained functions, each responsible for a specific task, can lead to increased flexibility and reusability. However, excessive granularity can increase the number of invocations, leading to higher costs. The ideal function granularity strikes a balance between modularity and efficiency, minimizing the overall number of invocations.
- Execution Time Optimization: Reducing the execution time of individual functions is a key cost-saving measure. This can be achieved through code optimization, efficient data access strategies, and selecting the appropriate memory allocation for each function. Profiling tools can help identify performance bottlenecks within the function code.
- Memory Allocation: Serverless platforms charge based on the memory allocated to a function. Selecting the optimal memory size is critical. Allocating too little memory can lead to performance degradation and longer execution times, while allocating too much memory results in unnecessary costs. Performance testing is important for finding the optimal memory setting.
- Efficient Data Transfer: Minimize the amount of data transferred between functions. This can be achieved by using efficient data formats (e.g., protocol buffers), compressing data where appropriate, and retrieving only the necessary data from data sources.
- Caching: Implementing caching mechanisms at various levels (e.g., API gateway, within functions) can significantly reduce the number of function invocations and data retrieval operations, leading to lower costs. Caching frequently accessed data can improve response times and decrease the load on backend services.
- Batching: Where applicable, batching requests can reduce the number of invocations. For example, instead of invoking a function for each individual item in a list, a single function invocation can process the entire batch.
- Idempotency: Implementing idempotency in functions can prevent duplicate invocations from causing unintended side effects and incurring unnecessary costs.
- Scheduled Invocation Management: Carefully plan and schedule function invocations to avoid unnecessary costs. Using scheduled triggers, such as those offered by cloud providers, can ensure functions are invoked only when required.
Comparison of Cost Optimization Techniques for a Composite API
Different cost optimization techniques have varying impacts on the overall cost of a composite API. The effectiveness of each technique depends on the specific architecture, workload, and characteristics of the composed functions.
| Technique | Impact on Cost | Considerations | Example |
|---|---|---|---|
| Function Granularity | Moderate to High (depending on the number of functions and invocation frequency) | Requires careful design to balance modularity and the number of invocations. Excessive granularity can increase costs. | Refactoring a monolithic function into several smaller, focused functions. |
| Execution Time Optimization | High (directly impacts the duration of execution, and consequently, cost) | Requires code profiling, efficient algorithms, and optimized data access strategies. | Replacing inefficient database queries with optimized ones, using efficient data structures, and optimizing loops. |
| Memory Allocation | Moderate (impacts the cost per invocation) | Requires performance testing to determine the optimal memory setting for each function. Under-allocation can lead to performance degradation, while over-allocation increases costs. | Dynamically adjusting memory allocation based on the workload or testing different memory sizes to find the most cost-effective setting. |
| Efficient Data Transfer | Moderate (reduces data transfer costs and potentially execution time) | Requires careful consideration of data formats, compression, and data retrieval strategies. | Using protocol buffers instead of JSON for data serialization, compressing large payloads before transfer. |
| Caching | High (reduces the number of invocations and data retrieval operations) | Requires a caching strategy that aligns with the data access patterns and cache invalidation mechanisms. | Implementing caching at the API gateway level for frequently accessed data or using a caching library within functions. |
| Batching | High (reduces the number of invocations) | Requires the ability to process requests in batches. | Combining multiple requests into a single request that is processed by a function. |
| Idempotency | Low (primarily protects against duplicate invocations, but indirectly reduces costs) | Requires careful design to ensure functions can be safely invoked multiple times without adverse effects. | Implementing unique request IDs and checking for existing results before processing a request. |
| Scheduled Invocation Management | High (prevents unnecessary invocations) | Requires a clear understanding of the function’s usage patterns and the use of scheduled triggers to invoke functions only when necessary. | Using cloud provider’s scheduled events to trigger a function at specific times. |
The choice of which techniques to prioritize depends on the specific characteristics of the API and the application’s usage patterns. A combination of these techniques, tailored to the unique requirements of the composite API, typically yields the best results in terms of cost optimization.
Real-World Use Cases
API composition in serverless architectures is not merely a theoretical concept; it’s a practical approach transforming how businesses build and deploy applications. This section delves into concrete examples, demonstrating how API composition solves real-world problems and drives tangible business value. The following examples showcase the versatility of API composition across diverse industries and use cases, illustrating its adaptability and effectiveness.
E-commerce Platform: Order Processing and Fulfillment
The complexities of order processing in e-commerce platforms necessitate efficient and scalable solutions. API composition provides the means to integrate disparate systems seamlessly.
The integration of various microservices allows for the creation of a robust order processing pipeline. The components include user authentication, product catalog retrieval, payment processing, inventory management, shipping calculations, and notification services.
| Problem | Solution | Technologies Used | Benefits |
|---|---|---|---|
| Handling high order volumes during peak seasons, leading to system overload and potential order failures. | Decomposing the order processing workflow into independent serverless functions. These functions, orchestrated through a serverless workflow engine, manage specific tasks like payment validation, inventory updates, and shipping label generation. API composition, using API gateways, routes requests to the appropriate function based on the order processing stage. | AWS Lambda, AWS Step Functions, API Gateway, DynamoDB, Payment Gateway APIs (e.g., Stripe, PayPal), Inventory Management APIs. | Improved scalability to handle peak loads, reduced latency, enhanced fault tolerance, and streamlined order fulfillment processes. The modularity also facilitates easier updates and feature additions. |
| Integrating multiple third-party services for payment processing, shipping, and fraud detection, resulting in complex integration challenges and potential points of failure. | Creating an API layer that acts as an abstraction layer over these third-party services. The API composition allows each function to focus on its specific task. The serverless functions handle payment processing through payment gateway APIs, shipping through shipping carrier APIs, and fraud detection through fraud detection services. The API gateway routes requests to these functions. | API Gateway, AWS Lambda, Payment Gateway APIs (e.g., Stripe, PayPal), Shipping Carrier APIs (e.g., FedEx, UPS), Fraud Detection APIs. | Simplified integration, improved maintainability, reduced dependencies on third-party service changes, and enhanced system resilience. |
| Providing a seamless user experience across different order statuses and updates, leading to customer dissatisfaction. | Orchestrating the order status updates through serverless workflows. As the order progresses through the fulfillment pipeline, the workflow triggers different serverless functions, each responsible for a specific step. API composition, using the API Gateway, provides a unified interface for order tracking. | AWS Lambda, AWS Step Functions, API Gateway, Amazon SNS, Amazon SQS. | Real-time order tracking, proactive notifications, and improved customer satisfaction. The orchestrated workflow ensures consistent updates and reduces manual intervention. |
Financial Services: Loan Application Processing
Financial institutions face complex challenges in streamlining loan application processes. API composition provides a flexible and scalable architecture.
Loan application processes involve multiple steps, including credit checks, income verification, and risk assessment. The microservices include credit scoring, income verification, risk assessment, loan origination, and notification services.
| Problem | Solution | Technologies Used | Benefits |
|---|---|---|---|
| Long processing times and manual interventions in loan applications, resulting in delays and customer dissatisfaction. | Automating the loan application workflow using serverless functions orchestrated through a workflow engine. Each function is responsible for a specific task, such as credit checks, income verification, and fraud detection. API composition allows each function to focus on its specific task. The API gateway routes requests to these functions. | AWS Lambda, AWS Step Functions, API Gateway, Credit Bureau APIs (e.g., Experian, Equifax), Income Verification APIs, Fraud Detection APIs. | Faster application processing, reduced manual effort, improved accuracy, and enhanced customer experience. |
| Integrating various third-party services for credit checks, fraud detection, and regulatory compliance, leading to complex integration challenges. | Creating an API layer that acts as an abstraction layer over these third-party services. Serverless functions are used to interact with external APIs, such as credit bureaus and fraud detection services. The API gateway routes requests to these functions. | API Gateway, AWS Lambda, Credit Bureau APIs, Fraud Detection APIs, Regulatory Compliance APIs. | Simplified integration, improved maintainability, and enhanced compliance with regulatory requirements. |
| Difficulty adapting to changing regulatory requirements and market conditions, leading to delays and compliance risks. | Designing a modular architecture where individual serverless functions can be updated and modified independently. API composition allows for quick modifications to specific components without affecting the entire system. The API gateway routes requests to the appropriate function based on the application needs. | AWS Lambda, API Gateway, Data Storage (e.g., DynamoDB, RDS), Notification Services. | Increased agility, faster time to market for new products and features, and improved ability to adapt to changing regulations. |
Healthcare: Patient Data Management
Healthcare providers need to manage patient data securely and efficiently. API composition enables the integration of various healthcare systems.
Patient data management involves secure storage, retrieval, and sharing of patient information. The microservices include patient registration, medical history retrieval, appointment scheduling, billing, and insurance verification services.
| Problem | Solution | Technologies Used | Benefits |
|---|---|---|---|
| Siloed patient data across different systems, making it difficult for healthcare providers to access comprehensive patient information. | Creating an API that aggregates data from various sources. Serverless functions are used to fetch data from different databases and systems, and the API Gateway exposes a unified interface for accessing patient data. | API Gateway, AWS Lambda, Database Connectors, Healthcare APIs (e.g., HL7), Data Storage (e.g., DynamoDB, RDS). | Improved access to patient information, enhanced data visibility, and better-informed decision-making by healthcare providers. |
| Ensuring compliance with HIPAA and other healthcare regulations, which requires stringent security measures. | Implementing robust security measures, including encryption, access control, and audit logging. Serverless functions are used to encrypt data and ensure secure communication with healthcare systems. The API Gateway enforces security policies and access controls. | API Gateway, AWS Lambda, Encryption Libraries, Identity and Access Management (IAM), Logging and Monitoring Tools. | Enhanced data security, improved compliance, and reduced risk of data breaches. |
| Integrating with different healthcare systems and devices, such as electronic health records (EHR) and medical devices. | Creating an API layer that acts as an abstraction layer over these systems. Serverless functions are used to integrate with different healthcare systems and devices, enabling data exchange and interoperability. The API Gateway routes requests to these functions. | API Gateway, AWS Lambda, EHR APIs, Medical Device APIs, Data Transformation Tools. | Improved interoperability, streamlined data exchange, and enhanced patient care. |
Last Word
In conclusion, API composition stands as a pivotal paradigm within serverless environments, enabling developers to construct sophisticated and scalable applications by strategically combining individual functions. From facilitating the decomposition of monolithic applications into microservices to optimizing costs and enhancing security, the advantages of this approach are undeniable. As the adoption of serverless continues to accelerate, a thorough understanding of API composition, including its orchestration tools, security considerations, and optimization strategies, becomes paramount for building resilient, cost-effective, and future-proof applications.
The ability to effectively compose APIs is not just a technical skill; it’s a fundamental requirement for thriving in the serverless era.
Detailed FAQs
What are the key benefits of using API composition in serverless?
API composition in serverless offers several key advantages, including improved scalability (by independently scaling functions), cost efficiency (through pay-per-use models), enhanced maintainability (due to smaller, modular components), and increased agility (allowing for faster development cycles and easier updates).
How does API composition contribute to cost optimization in serverless?
API composition allows for fine-grained control over resource utilization. By breaking down functionalities into smaller, independent functions, developers can optimize costs by only invoking the necessary functions, scaling them independently, and leveraging the pay-per-use pricing model of serverless platforms. Unnecessary resource allocation is minimized.
What are the common challenges associated with API composition in serverless?
Common challenges include managing dependencies between microservices, ensuring consistent data formats, implementing robust error handling and retry mechanisms, and maintaining security across a distributed architecture. Monitoring and logging also become more complex in a distributed environment.
How does API composition differ from a traditional monolithic API?
In a monolithic API, all functionalities are bundled within a single application, making it difficult to scale and maintain. API composition, in contrast, breaks down functionalities into independent, serverless functions, allowing for greater flexibility, scalability, and cost efficiency. The modular approach also allows for easier updates and modifications without affecting the entire system.