Event-Driven Architecture (EDA) with serverless computing represents a paradigm shift in software design, enabling highly scalable, responsive, and cost-effective applications. This architecture leverages the power of events – occurrences of state changes or actions – to trigger actions and propagate information across a system. By combining EDA’s asynchronous communication model with serverless’s on-demand resource allocation, developers can build systems that react instantly to changing conditions, scale automatically, and minimize operational overhead.
This exploration will dissect the core principles of EDA, outlining its components and demonstrating its operational flow through practical examples. Subsequently, we will delve into the world of serverless computing, highlighting its benefits and core characteristics. The synergy between EDA and serverless will be thoroughly examined, detailing how they complement each other to create powerful, efficient, and resilient applications. We’ll also analyze key components, implementation strategies, real-world applications, and the associated challenges and considerations.
Defining Event-Driven Architecture (EDA)

Event-Driven Architecture (EDA) represents a paradigm shift in software design, emphasizing asynchronous communication and real-time responsiveness. It allows different components of a system to react to events, leading to more flexible, scalable, and resilient applications. This approach is particularly well-suited for modern, distributed systems where components can operate independently and communicate with each other through events.
Core Principles of EDA
The core principles of EDA revolve around the concepts of events, event producers, and event consumers. These principles enable a decoupled and reactive system, allowing for greater flexibility and scalability.
- Events: Events are the fundamental building blocks of EDA. An event represents a significant occurrence or state change within the system. They are immutable and contain relevant data describing what happened. Examples include a user placing an order, a sensor detecting a temperature change, or a stock price reaching a certain threshold.
- Event Producers: Event producers are the components that generate events. They are responsible for detecting changes and publishing corresponding events. They do not need to know which consumers will react to the events. Their primary responsibility is to generate and publish events related to their specific domain.
- Event Consumers: Event consumers are the components that subscribe to and react to events. They are responsible for listening for specific event types and taking appropriate actions when those events occur. Consumers are decoupled from the producers, allowing them to be added, removed, or modified without affecting the producers.
- Asynchronous Communication: EDA promotes asynchronous communication, where components communicate without blocking each other. This means that event producers do not wait for consumers to process events before continuing their operation. This asynchronous nature enhances system responsiveness and scalability.
- Decoupling: EDA promotes decoupling between components. Producers and consumers are not directly aware of each other. They interact through a central event processing system, which handles the routing and delivery of events. This decoupling makes the system more modular and easier to maintain and evolve.
Components Involved in an EDA System
EDA systems typically consist of several key components that work together to enable event processing and communication. Understanding these components is crucial for designing and implementing an effective EDA.
- Event Producers: As previously mentioned, event producers generate events. These can be various parts of the system, such as microservices, databases, or external systems. They publish events to an event broker or event streaming platform.
- Event Broker/Event Streaming Platform: This is the central component that acts as the intermediary between producers and consumers. It receives events from producers, stores them (potentially), and routes them to the appropriate consumers. Popular examples include Apache Kafka, Amazon Kinesis, and RabbitMQ. These platforms often provide features like event storage, replay, and filtering.
- Event Consumers: Event consumers subscribe to specific events or event types and process them. They can be other microservices, databases, or external systems. Consumers are typically designed to perform specific tasks based on the events they receive.
- Event Schema Registry: This component manages the schema of events. It provides a central repository for defining the structure and format of events, ensuring that producers and consumers understand the data being exchanged. Examples include Apache Avro and JSON Schema.
- Event Channels/Topics: Event channels or topics are logical groupings of events. Producers publish events to specific channels, and consumers subscribe to channels to receive relevant events. This allows for efficient routing and filtering of events.
Real-World Example: Order Processing in an E-commerce System
Consider an e-commerce system built using EDA. This example demonstrates how events trigger actions in a real-world scenario.
- Event: A customer places an order. This is a significant event that triggers a series of actions.
- Event Producer: The “Order Service” is the event producer. When a customer submits an order, the Order Service creates an “OrderPlaced” event. This event contains details like the order ID, customer ID, items ordered, and total amount.
- Event Broker: The OrderPlaced event is published to an event broker, such as Apache Kafka, which acts as the central messaging system.
- Event Consumers and Actions: Several consumers subscribe to the OrderPlaced event and perform different actions:
- Inventory Service: Receives the OrderPlaced event and checks if the items in the order are in stock. If not, it might trigger an “OutOfStock” event.
- Payment Service: Receives the OrderPlaced event and initiates payment processing. It might trigger a “PaymentProcessed” or “PaymentFailed” event.
- Shipping Service: Receives the OrderPlaced event and creates a shipping label and starts the shipping process.
- Notification Service: Receives the OrderPlaced event and sends a confirmation email or SMS to the customer.
- Subsequent Events: As the order progresses, other events might be generated, such as “PaymentProcessed,” “ItemShipped,” and “OrderDelivered.” These events trigger further actions, like updating the order status in the database and sending notifications.
This example demonstrates how EDA enables a decoupled and responsive system. Each service acts independently, reacting to events without needing to know the details of other services. The event broker ensures reliable communication and scalability. This approach allows for easier maintenance, updates, and the addition of new features without disrupting existing functionality.
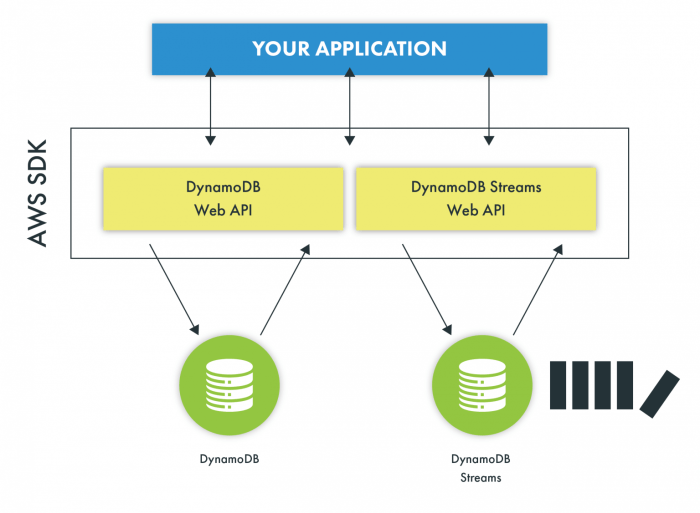
Serverless Computing Overview
Serverless computing, a cloud computing execution model, allows developers to build and run applications without managing servers. This model abstracts away the underlying infrastructure, enabling developers to focus solely on writing code and responding to events. Serverless architectures are intrinsically linked to event-driven architectures, providing a powerful combination for building scalable, resilient, and cost-effective applications.
Benefits of Serverless Computing
Serverless computing offers a range of advantages that make it an attractive option for modern application development. These benefits directly contribute to increased efficiency, reduced operational overhead, and improved scalability.
- Reduced Operational Overhead: Serverless providers manage the server infrastructure, including provisioning, scaling, and maintenance. This significantly reduces the operational burden on development teams, allowing them to focus on application logic rather than infrastructure management. This includes tasks such as patching, security updates, and capacity planning, all handled by the cloud provider.
- Automatic Scaling: Serverless platforms automatically scale resources based on demand. This ensures that applications can handle fluctuating workloads without manual intervention. The platform dynamically allocates compute resources, such as CPU and memory, as needed, leading to improved performance and responsiveness.
- Cost Optimization: Serverless computing typically employs a pay-per-use pricing model. Users are charged only for the actual compute time consumed by their functions. This can result in significant cost savings compared to traditional server-based models, particularly for applications with intermittent or spiky workloads. For instance, a web application that experiences peak traffic during specific hours of the day would only be charged for the compute resources used during those hours.
- Increased Developer Productivity: Serverless platforms often provide features like automatic deployment, built-in monitoring, and integrated logging. These features streamline the development process, allowing developers to iterate quickly and deploy updates with ease. The focus shifts from infrastructure management to code development, boosting overall productivity.
- Improved Scalability and Resilience: Serverless functions are inherently designed to be highly scalable and resilient. The platform automatically distributes function invocations across multiple instances, ensuring high availability and fault tolerance. If one instance fails, the platform automatically provisions a new one, minimizing downtime and impact on users.
Key Characteristics of Serverless Functions
Serverless functions, the fundamental building blocks of serverless applications, possess several key characteristics that differentiate them from traditional application components. These characteristics enable the benefits of serverless computing.
- Event-Driven Execution: Serverless functions are primarily triggered by events. These events can originate from various sources, such as HTTP requests, database changes, scheduled timers, or messages from a message queue. The function’s execution is triggered automatically in response to these events.
- Statelessness: Serverless functions are typically stateless. Each function invocation operates independently and does not maintain any state between invocations. Any necessary state information must be stored externally, such as in a database or a cache. This stateless design simplifies scaling and ensures that any instance can handle a function invocation.
- Short-Lived Execution: Serverless functions are designed for short-lived execution. They are typically optimized for handling specific tasks or operations and are designed to complete quickly. This short-lived nature contributes to the pay-per-use pricing model, as users are charged only for the duration of the function’s execution.
- Automatic Scaling and Concurrency: Serverless platforms automatically scale functions based on demand, allowing for concurrent execution of multiple function instances. The platform manages the allocation of resources to ensure that functions can handle high volumes of requests without performance degradation.
- Managed Infrastructure: The underlying infrastructure for serverless functions is fully managed by the cloud provider. This includes the provisioning, scaling, and maintenance of servers, operating systems, and other infrastructure components. Developers do not need to worry about these aspects, allowing them to focus on code development.
Design a Basic Serverless Function and Its Deployment Steps
Creating a basic serverless function involves writing the code, configuring the function’s trigger, and deploying it to a serverless platform. This process can be illustrated with a simple example.
Example: A simple serverless function that responds to HTTP GET requests and returns a “Hello, World!” message.
Function Code (Node.js):
exports.handler = async (event) => const response = statusCode: 200, body: JSON.stringify('Hello, World!'), ; return response;; Deployment Steps (using AWS Lambda and the AWS CLI):
- Package the Code: Create a ZIP archive containing the function code (e.g., `index.js`).
- Create an IAM Role: Define an IAM role with the necessary permissions for the function to execute (e.g., access to CloudWatch Logs).
- Deploy the Function: Use the AWS CLI to deploy the function to AWS Lambda. This involves specifying the function name, runtime (Node.js), handler (exports.handler), and the IAM role.
- Configure an API Gateway Trigger (Optional): If you want to expose the function via an HTTP endpoint, configure an API Gateway trigger. This involves creating an API Gateway API and associating it with the Lambda function.
- Test the Function: Invoke the function through the API Gateway endpoint (if configured) or through the AWS Lambda console.
aws lambda create-function \ --function-name my-hello-world-function \ --runtime nodejs18.x \ --handler index.handler \ --zip-file fileb://function.zip \ --role arn:aws:iam::123456789012:role/lambda-execution-role
Explanation of the example:
The Node.js code defines a function `handler` that is triggered by an event. The event, in this case, is an HTTP request. The function constructs a response object with a 200 status code and a JSON-encoded “Hello, World!” message. The deployment steps Artikel the process of packaging the code, creating the necessary permissions, deploying the function to AWS Lambda, and optionally configuring an API Gateway trigger to expose the function via an HTTP endpoint.
This allows for easy invocation via a URL. The AWS CLI commands show how to deploy the function, specifying details such as the function’s name, runtime environment, and the handler function.
The Synergy: EDA and Serverless
The convergence of Event-Driven Architecture (EDA) and serverless computing represents a powerful paradigm shift in modern software development. Serverless technologies provide an ideal platform for implementing and scaling EDA systems, while EDA unlocks the full potential of serverless’s event-driven nature. This synergistic relationship allows for building highly responsive, scalable, and cost-effective applications.
Serverless Complements EDA
Serverless computing provides a natural fit for EDA because of its event-driven execution model. Serverless functions, triggered by events, form the core of an EDA system. This allows developers to build applications that react instantly to changes in the system without the need for constant server provisioning and management.
- Event-Driven Triggers: Serverless functions are triggered by events, such as changes in a database, file uploads, or messages in a queue. This aligns perfectly with the EDA model, where events initiate workflows. For instance, an image upload to a cloud storage service can trigger a serverless function to resize the image, generate thumbnails, and store them in a different bucket.
This process is entirely event-driven.
- Scalability and Elasticity: Serverless platforms automatically scale resources based on demand. As event volume increases, the platform automatically provisions more function instances to handle the load. This ensures that the application remains responsive even during peak periods. For example, during an e-commerce flash sale, a serverless function responsible for processing orders can automatically scale up to handle thousands of concurrent requests, ensuring that the system remains operational.
- Cost-Effectiveness: Serverless computing follows a pay-per-use model. Developers only pay for the compute time consumed by their functions. This eliminates the need to pay for idle resources, making it a cost-effective solution, particularly for applications with fluctuating workloads. This is in stark contrast to traditional architectures where resources are provisioned and paid for regardless of actual usage.
- Simplified Operations: Serverless platforms manage the underlying infrastructure, including servers, operating systems, and scaling. This allows developers to focus on writing code and business logic rather than managing infrastructure. This reduces operational overhead and accelerates development cycles. This allows developers to concentrate on delivering business value instead of managing infrastructure.
Advantages of Combining EDA with Serverless Technologies
The combination of EDA and serverless offers several advantages over traditional architectures. This includes increased agility, reduced operational costs, and improved scalability.
- Increased Agility and Faster Time-to-Market: Serverless allows developers to rapidly deploy and iterate on applications. The event-driven nature of EDA, coupled with serverless’s ease of deployment, allows for faster development cycles. Features can be built, tested, and deployed more quickly, leading to a faster time-to-market.
- Improved Scalability and Resilience: Serverless platforms automatically scale functions based on event volume. This ensures that the application can handle fluctuating workloads without manual intervention. The distributed nature of serverless functions also increases resilience, as failures in one function instance do not necessarily affect the entire application.
- Reduced Operational Costs: Serverless computing follows a pay-per-use model, which reduces operational costs, especially for applications with fluctuating workloads. Furthermore, serverless platforms manage the underlying infrastructure, reducing the need for dedicated operations teams.
- Enhanced Developer Productivity: Serverless platforms abstract away infrastructure management, allowing developers to focus on writing code and business logic. This increases developer productivity and reduces the time spent on operational tasks.
Comparison of EDA with Serverless to Traditional Architectures
The following table compares EDA with serverless to traditional architectures across key aspects.
| Feature | Traditional Architecture | EDA with Serverless |
|---|---|---|
| Execution Model | Request-driven: Typically synchronous and relies on a client making a direct request to a server. | Event-driven: Asynchronous, where components react to events, and events trigger functions. |
| Scalability | Requires manual scaling, which can be time-consuming and often involves over-provisioning resources to handle peak loads. | Highly scalable due to automatic scaling of serverless functions based on event volume. |
| Cost | Requires paying for provisioned resources, regardless of actual usage, leading to potential waste during idle periods. | Pay-per-use model, where costs are directly tied to the execution time of serverless functions, leading to cost optimization. |
| Deployment and Management | Requires managing servers, operating systems, and other infrastructure components, which increases operational overhead. | Serverless platforms manage the underlying infrastructure, allowing developers to focus on code. Deployment is simplified, and operations are reduced. |
Key Components in an EDA Serverless System
Event-driven architecture in a serverless context relies on several key components working together to facilitate asynchronous communication and event processing. These components are the building blocks that enable the decoupled, scalable, and resilient nature of such systems. Understanding these elements is crucial for designing and implementing effective serverless EDA solutions.
Common Services in EDA Serverless Systems
Serverless EDA leverages a variety of services to manage events, process them, and trigger actions. These services typically fall into categories like event ingestion, event processing, and event storage. The selection of these services depends on the specific requirements of the application, including event volume, processing complexity, and desired latency.
- Event Ingestion: Services responsible for receiving events from various sources. Examples include API gateways, which receive HTTP requests and translate them into events, and streaming services that ingest high-volume data streams.
- Event Processing: The core of the EDA, where events are transformed, filtered, and routed. Serverless functions, triggered by events, are the primary processing units.
- Event Storage: Services used to persist events for auditing, replayability, and analytics. Examples include databases, object storage services, and event stores designed specifically for event sourcing.
- Message Queues: Act as intermediaries for asynchronous communication, decoupling event producers and consumers. They provide buffering and ensure message delivery even if consumers are temporarily unavailable.
- Event Buses: Centralized hubs for publishing, routing, and managing events. They simplify the process of connecting event producers and consumers and often provide features like event filtering and transformation.
- Monitoring and Observability: Crucial for understanding system behavior and identifying issues. Services provide metrics, logging, and tracing capabilities.
Message Queue Implementations
Message queues are a fundamental component of EDA, facilitating asynchronous communication and decoupling services. They store messages temporarily, enabling producers to send messages without waiting for consumers to process them immediately. Several message queue implementations are available, each with its own set of characteristics and trade-offs.
Below is a comparison of popular message queue implementations, highlighting their pros and cons:
- Amazon SQS (Simple Queue Service): A fully managed message queuing service offered by AWS.
- Pros: Highly scalable, cost-effective, integrates seamlessly with other AWS services, simple to use, supports standard and FIFO (First-In, First-Out) queues.
- Cons: Limited message size, basic features compared to more advanced message brokers, potential for eventual consistency.
- Google Cloud Pub/Sub: A fully managed, real-time messaging service from Google Cloud Platform.
- Pros: High throughput, global availability, supports both publish-subscribe and queueing models, integrates with other GCP services, provides features like message ordering and dead-letter queues.
- Cons: Pricing can be complex, potential for increased latency compared to some alternatives.
- Azure Service Bus: A fully managed enterprise integration service from Microsoft Azure.
- Pros: Supports advanced features like transactions, message sessions, and topics with subscriptions, integrates well with other Azure services, offers a robust feature set.
- Cons: Can be more complex to configure and manage than simpler queue services, potential for higher costs depending on usage.
- RabbitMQ: An open-source message broker that implements the Advanced Message Queuing Protocol (AMQP).
- Pros: Flexible and feature-rich, supports multiple messaging protocols, can be deployed on-premises or in the cloud, large and active community.
- Cons: Requires more operational overhead compared to fully managed services, needs dedicated infrastructure.
- Kafka: A distributed streaming platform used for building real-time data pipelines and streaming applications.
- Pros: High throughput, fault-tolerant, supports real-time stream processing, widely adopted for big data applications.
- Cons: Complex to set up and manage, requires dedicated infrastructure.
The Role of Event Brokers in Serverless EDA
Event brokers play a crucial role in serverless EDA by acting as a central hub for event management. They provide a layer of abstraction between event producers and consumers, decoupling them and simplifying the overall system architecture. Event brokers handle event routing, filtering, and delivery, making it easier to build and maintain complex event-driven applications.
Key functions of event brokers in serverless EDA include:
- Event Ingestion: Receiving events from various sources.
- Event Routing: Directing events to the appropriate consumers based on predefined rules or topics.
- Event Filtering: Allowing consumers to subscribe to specific types of events based on criteria.
- Event Transformation: Modifying the format or content of events before delivery.
- Event Delivery: Ensuring that events are delivered to the intended consumers reliably.
- Scalability and High Availability: Designed to handle large volumes of events and maintain availability.
Event brokers often provide features like:
- Topic-based or event type-based routing: Events are categorized by topic or event type, and consumers subscribe to the topics they are interested in.
- Event filtering: Consumers can filter events based on their content, such as the payload or metadata.
- Dead-letter queues: Events that fail to be processed are moved to a dead-letter queue for later analysis or retry.
- Event replay: The ability to replay past events for auditing or debugging.
Implementing EDA with Serverless
Implementing Event-Driven Architecture (EDA) with serverless technologies offers a streamlined approach to building scalable, resilient, and cost-effective applications. The process involves several key steps, from designing the event flow to deploying and monitoring the serverless functions that react to those events. This section provides a step-by-step guide to help navigate this implementation.
Designing an Event-Driven Serverless Application
Designing an event-driven serverless application requires careful consideration of the events, the sources of those events, the consumers of those events, and the overall flow of data. The following steps Artikel the design process:
- Identify Events: The first step is to identify the events that will drive the application. These events represent significant occurrences or changes within the system. For example, in an e-commerce application, events might include “Order Created,” “Payment Processed,” or “Shipment Delivered.”
- Define Event Sources: Determine the sources of each event. Event sources are the components or systems that generate the events. This could be a database, a user interface, or a third-party service.
- Define Event Consumers: Identify the components or services that need to react to each event. These are the consumers of the events, which could be serverless functions, other microservices, or external systems.
- Design Event Schemas: Establish a consistent schema for each event. The schema defines the structure and content of the event data, ensuring that consumers can reliably interpret the event information. Consider using formats like JSON for event payloads.
- Choose an Event Broker: Select an event broker to facilitate the communication between event sources and consumers. Popular choices include message queues (e.g., Amazon SQS, RabbitMQ) and event streams (e.g., Amazon Kinesis, Apache Kafka).
- Design Function Logic: Design the logic within each serverless function that will handle the events. This includes determining how the function will process the event data and what actions it will take.
- Map Events to Functions: Establish the relationship between events and the serverless functions that will process them. This involves configuring the event broker to route events to the appropriate functions.
Deploying a Serverless Function that Reacts to Events
Deploying a serverless function that reacts to events involves several stages, from writing the function code to configuring the event trigger. This process ensures that the function is correctly deployed and can respond to events as they occur.
- Write the Function Code: Develop the code for the serverless function. The function should be designed to process the event data and perform the necessary actions. The code should be designed to handle potential errors gracefully.
- Choose a Cloud Provider and Runtime: Select a cloud provider (e.g., AWS, Azure, Google Cloud) and a runtime environment (e.g., Node.js, Python, Java) for the function. The choice depends on the specific requirements of the application.
- Package the Function: Package the function code and any necessary dependencies into a deployment package. This package is uploaded to the cloud provider.
- Configure the Event Trigger: Configure the event trigger that will invoke the function. The trigger specifies the event source and the event type that will cause the function to execute. This typically involves setting up the connection between the event broker and the function.
- Deploy the Function: Deploy the function to the cloud provider. This process uploads the deployment package and configures the function’s execution environment.
- Test the Function: Test the function to ensure that it correctly processes events and performs the expected actions. This may involve sending test events to the function.
- Monitor the Function: Implement monitoring to track the function’s performance and identify any issues. Monitoring tools provide insights into function invocations, execution times, and errors.
Code Snippet Illustrating Event Publishing and Consumption
The following pseudo-code illustrates the basic principles of event publishing and consumption within an event-driven serverless system. This simplified example demonstrates how an event is published by a producer and consumed by a serverless function.
// Event Publisher (e.g., a service creating an order)function publishOrderCreatedEvent(orderData) // Choose an event broker (e.g., AWS SNS, Azure Event Grid, Google Cloud Pub/Sub) eventBroker.publish("order.created", JSON.stringify(orderData));// Event Consumer (e.g., a serverless function to process the order)function processOrderCreatedEvent(event) const orderData = JSON.parse(event.body); console.log("Received order:", orderData); // Perform actions based on the order data, e.g., //-Update the inventory //-Send a confirmation email //-Create a shipment// Event Broker (Conceptual Representation)// This section is not actual code but a conceptual representation// of how an event broker might work. The specific implementation// varies depending on the chosen event broker.const eventBroker = publish: (topic, message) => // In a real system, this would involve sending the message // to the event broker. For example, using AWS SNS: // snsClient.publish( // TopicArn: 'arn:aws:sns:...', // Message: message, // MessageAttributes: // 'EventType': // DataType: 'String', // StringValue: topic // // // ); console.log(`Published to $topic: $message`); , subscribe: (topic, handler) => // In a real system, this would involve configuring the // event broker to trigger the serverless function // when a message is published to the topic.
For example, // using AWS SQS and AWS Lambda. // Lambda function is triggered by SQS. ;// Example Usageconst order = orderId: "12345", customerId: "67890", items: [ productId: "A123", quantity: 2 ];publishOrderCreatedEvent(order);// In a real system, the event consumer (serverless function)// would be triggered by the event broker automatically.// The above is a conceptual example.
This pseudo-code illustrates the core concepts: a publisher (e.g., `publishOrderCreatedEvent`) sends an event to an event broker, and a consumer (e.g., `processOrderCreatedEvent`) is triggered by the event broker to process the event. The event broker acts as an intermediary, decoupling the publisher and consumer. The `eventBroker` object provides a conceptual representation of the event broker’s functionality. In a real-world implementation, the `publish` method would interact with a specific event broker service (e.g., AWS SNS, Azure Event Grid, Google Cloud Pub/Sub), and the `subscribe` would involve configuring triggers to activate serverless functions in response to events.
Benefits of EDA with Serverless
Event-Driven Architecture (EDA) combined with serverless computing unlocks a suite of advantages, fundamentally transforming how applications are designed, deployed, and managed. This synergistic approach provides significant improvements in scalability, responsiveness, and cost efficiency, making it a compelling choice for modern application development.
Scalability Advantages of EDA with Serverless
EDA with serverless inherently supports extreme scalability. Serverless platforms automatically scale resources based on the incoming event load, eliminating the need for manual provisioning and management of infrastructure. This dynamic scaling ensures that applications can handle sudden spikes in traffic or data processing demands without performance degradation.
The scalability benefits can be broken down further:
- Automatic Scaling: Serverless functions are designed to scale automatically in response to events. When an event occurs, the serverless platform provisions the necessary compute resources to handle the event. As the number of events increases, the platform automatically scales up the number of function instances. Conversely, when the event rate decreases, the platform scales down the resources, optimizing resource utilization.
- Independent Scaling of Components: In an EDA, different components (microservices or functions) can scale independently based on their specific event processing needs. This granular scaling capability is a key advantage over monolithic architectures, where the entire application must be scaled even if only a small portion of the functionality is experiencing high load. For instance, an e-commerce platform might have a separate serverless function to handle order processing, another for payment processing, and yet another for inventory updates.
Each function can scale independently based on the volume of orders, payments, or inventory changes.
- Horizontal Scaling: Serverless platforms typically employ horizontal scaling, which means adding more instances of a function to handle the workload. This approach is inherently more scalable and resilient than vertical scaling (increasing the resources of a single instance). Horizontal scaling allows applications to handle massive event volumes without impacting performance.
- Geographic Distribution: Serverless platforms often provide the ability to deploy functions across multiple geographic regions. This capability allows applications to be deployed closer to users, reducing latency and improving responsiveness. Geographic distribution also enhances fault tolerance, as if one region experiences an outage, traffic can be routed to other regions.
For example, consider an image processing service. Using EDA with serverless, when a user uploads an image, an event is triggered. A serverless function is invoked to process the image. If the service experiences a surge in image uploads, the serverless platform automatically scales up the number of function instances to handle the increased load. This ensures that images are processed quickly and efficiently, even during peak times.
Application Responsiveness Improvement with EDA and Serverless
EDA and serverless architecture significantly enhance application responsiveness. The event-driven nature of the system enables asynchronous processing, where tasks are decoupled and executed independently. Serverless functions, with their rapid startup times, can react quickly to events, minimizing latency and providing a more responsive user experience.
The improvements to responsiveness can be seen in the following ways:
- Asynchronous Processing: Events are processed asynchronously, meaning that the system does not have to wait for a task to complete before moving on to the next one. This non-blocking approach prevents bottlenecks and keeps the application responsive, even when dealing with long-running or complex operations. For instance, when a user places an order, the order confirmation, inventory update, and payment processing can be handled asynchronously, allowing the user to quickly receive confirmation while the backend tasks are processed in the background.
- Reduced Latency: Serverless functions typically have fast startup times (cold start), enabling them to respond quickly to events. This minimizes the time it takes for an application to react to user actions or system events, leading to a more responsive user interface and a better overall user experience.
- Real-time Updates: EDA facilitates real-time updates and notifications. When an event occurs, such as a new comment on a social media post or a price change on an e-commerce product, the system can immediately notify relevant users or systems. This real-time capability is crucial for applications that require up-to-the-minute information.
- Improved User Experience: The combination of asynchronous processing, reduced latency, and real-time updates results in a significantly improved user experience. Users perceive the application as being faster, more responsive, and more engaging.
Consider a ride-sharing application. When a user requests a ride, an event is triggered. Serverless functions can quickly handle the request, matching the user with a driver, sending notifications, and updating the map in real-time. This responsive system provides a seamless user experience.
Operational Cost Reduction with EDA and Serverless
EDA combined with serverless offers substantial cost savings compared to traditional architectures. The pay-per-use model of serverless computing eliminates the need to provision and manage infrastructure, resulting in lower operational expenses. Furthermore, the event-driven nature of the system optimizes resource utilization, as functions are only invoked when events occur.
The cost reduction is achieved through:
- Pay-per-Use Pricing: Serverless platforms charge only for the actual compute time and resources consumed by the functions. This pay-per-use model eliminates the need to pay for idle resources, which is common with traditional infrastructure. This means that costs scale directly with usage. If the application is not being used, the costs are minimal.
- Reduced Operational Overhead: Serverless platforms handle the underlying infrastructure management, including server provisioning, scaling, patching, and monitoring. This reduces the operational burden on the development team, freeing them to focus on building and deploying applications. This decrease in operational overhead translates directly into reduced costs associated with infrastructure management.
- Optimized Resource Utilization: EDA optimizes resource utilization. Functions are only invoked when events occur, which means that resources are only consumed when needed. This leads to more efficient use of compute resources and reduces overall costs. For example, a serverless function that processes images might only be invoked when a new image is uploaded, and the function only consumes resources during the image processing operation.
- Elimination of Over-Provisioning: With traditional infrastructure, it is common to over-provision resources to handle peak loads. This leads to wasted resources and increased costs. Serverless platforms automatically scale resources based on demand, eliminating the need for over-provisioning.
For instance, a web application using EDA and serverless can automatically scale the number of functions based on the number of user requests. If the application experiences a period of low activity, the platform scales down the number of function instances, resulting in lower costs. When the application experiences a surge in traffic, the platform automatically scales up the number of function instances to handle the increased load without requiring manual intervention.
This dynamic scaling and pay-per-use pricing model make serverless an economical choice for applications with variable workloads.
Challenges and Considerations
Implementing Event-Driven Architecture (EDA) with serverless computing presents several complexities that must be carefully considered to ensure successful deployment and operation. These challenges span architectural design, security protocols, and operational aspects, demanding a comprehensive understanding of both EDA principles and serverless constraints. Addressing these considerations proactively is crucial for realizing the full potential of this powerful combination.
Potential Challenges When Implementing EDA with Serverless
Several hurdles can impede the effective implementation of EDA with serverless. Overcoming these requires careful planning, meticulous execution, and continuous monitoring.
- Complexity in Event Correlation and Orchestration: Managing the flow of events and coordinating actions across multiple serverless functions can become intricate. As the number of events and functions grows, tracing the origin and impact of an event becomes increasingly difficult. This complexity can lead to debugging challenges and difficulties in understanding the system’s behavior. For example, a complex order processing system might involve multiple events (order placed, payment received, inventory updated, shipment initiated), each triggering several serverless functions.
Tracking the status of an order through this chain of events and identifying failures requires robust event correlation mechanisms.
- Debugging and Monitoring Difficulties: Serverless environments often lack the traditional debugging tools available in more conventional architectures. Distributed tracing, centralized logging, and comprehensive monitoring are essential to troubleshoot issues. Without these tools, identifying the root cause of a failure in a serverless EDA system can be a time-consuming and challenging process.
- Eventual Consistency and Data Management: EDA inherently relies on eventual consistency, which can pose challenges when dealing with data integrity. Serverless functions that react to events might not always have immediate access to the most up-to-date data. This requires careful consideration of data consistency models and the implementation of strategies to handle potential data conflicts or inconsistencies. For instance, if a function triggers an inventory update based on an order event, there might be a delay before the inventory database reflects the change.
This can lead to issues if another function tries to query the inventory immediately after the order event.
- Scalability and Throughput Considerations: While serverless offers automatic scaling, managing high event volumes and ensuring sufficient throughput can still be challenging. Event sources can generate bursts of events, potentially overwhelming serverless functions. Proper event queueing, function scaling configurations, and resource allocation are crucial to handle peak loads and prevent performance bottlenecks. For example, a sudden surge in website traffic might lead to a massive influx of order events, requiring the system to scale rapidly to process all orders without delays.
- Vendor Lock-in and Platform Dependencies: Serverless platforms often have specific implementations and integrations for event sources, event buses, and other services. This can lead to vendor lock-in, making it difficult to migrate the system to a different platform. Careful selection of platform-agnostic technologies and architectures is essential to mitigate this risk.
- Cold Starts and Function Initialization Time: Serverless functions can experience cold starts, which can introduce latency. When a function is not actively running, it needs to be initialized before it can process an event. This initialization process can take a few seconds, which can impact the performance of event processing. Optimizing function code, using warm pools, and pre-warming functions can help to reduce the impact of cold starts.
Security Considerations for Serverless EDA
Security is paramount in any serverless EDA implementation. The distributed nature of serverless architectures and the inherent reliance on event triggers introduce unique security challenges.
- Authentication and Authorization: Securely managing access to serverless functions and event sources is critical. This involves implementing robust authentication and authorization mechanisms to ensure that only authorized entities can trigger or consume events. Proper use of API keys, access tokens, and role-based access control (RBAC) is essential.
- Event Source Security: Protecting the event sources themselves is essential. This includes securing the event sources and preventing unauthorized access or manipulation of event data. For example, if an event source is a database, the database must be secured with appropriate access controls. Similarly, if an event source is an API, the API must be protected with authentication and authorization mechanisms.
- Data Encryption and Protection: Sensitive data transmitted through events or processed by serverless functions must be protected through encryption. Encryption should be applied both in transit and at rest. Additionally, implementing data masking and anonymization techniques can help to protect sensitive information.
- Function Security and Isolation: Serverless functions should be designed with security in mind. This includes following the principle of least privilege, using secure coding practices, and regularly patching dependencies. Isolating functions from each other and limiting their access to resources can minimize the impact of a security breach.
- Input Validation and Sanitization: All event data should be validated and sanitized to prevent injection attacks and other security vulnerabilities. Input validation ensures that the data conforms to expected formats and ranges, while sanitization removes or neutralizes potentially malicious code.
- Monitoring and Auditing: Implementing comprehensive monitoring and auditing capabilities is essential to detect and respond to security threats. This includes monitoring event logs, function execution logs, and access logs for suspicious activity. Auditing provides a record of all security-related events, enabling security teams to investigate incidents and identify vulnerabilities.
Monitoring and Debugging Serverless EDA Applications
Effective monitoring and debugging are crucial for the operational health of serverless EDA applications. Due to the distributed and ephemeral nature of serverless functions, traditional debugging methods are often inadequate.
- Centralized Logging: Centralized logging is essential for collecting and analyzing logs from all serverless functions and event sources. Logs should include detailed information about event triggers, function executions, errors, and performance metrics. Tools like cloud-native logging services (e.g., AWS CloudWatch Logs, Azure Monitor, Google Cloud Logging) provide centralized storage, search, and analysis capabilities.
- Distributed Tracing: Distributed tracing enables the tracking of requests and events across multiple serverless functions. It provides a visual representation of the event flow and helps to identify bottlenecks and performance issues. Tools like AWS X-Ray, Jaeger, and Zipkin can be used to implement distributed tracing.
- Performance Monitoring: Monitoring the performance of serverless functions and event sources is critical. This includes tracking metrics such as invocation duration, memory usage, error rates, and latency. Performance monitoring tools provide insights into function performance and help to identify areas for optimization.
- Alerting and Notifications: Setting up alerts and notifications is crucial for proactively identifying and responding to issues. Alerts can be triggered based on predefined thresholds for performance metrics, error rates, or other relevant events. Notifications can be sent to operations teams or other stakeholders to inform them of potential problems.
- Debugging Tools: Using appropriate debugging tools is essential. These can include local function testing, remote debugging, and integration with IDEs. Many serverless platforms provide tools for debugging functions locally and remotely.
- Error Handling and Retries: Implementing robust error handling and retry mechanisms is essential to handle transient failures and ensure the resilience of the system. Functions should be designed to gracefully handle errors and to retry failed operations. Event queues can be used to implement retry mechanisms.
Real-World Use Cases
Event-driven architecture (EDA) combined with serverless computing finds application across diverse industries, offering scalability, responsiveness, and cost-efficiency. This synergistic approach enables businesses to react rapidly to events, automate processes, and enhance customer experiences. Several sectors have demonstrably benefited from this architecture, showcasing its adaptability and value.
Industries Benefiting from EDA with Serverless
Several industries are well-suited to leverage the advantages of EDA with serverless due to their dynamic and event-rich operational environments. These sectors often deal with high volumes of data, real-time interactions, and the need for rapid responses to changing conditions.
- E-commerce: E-commerce platforms thrive on real-time updates and immediate responses to user actions.
- Finance: Financial institutions require immediate transaction processing and fraud detection capabilities.
- Healthcare: Healthcare providers can utilize EDA for patient monitoring and data analysis.
- Manufacturing: Manufacturing environments use EDA for supply chain management and predictive maintenance.
- IoT (Internet of Things): IoT applications generate a continuous stream of events that can be efficiently managed with EDA.
- Gaming: Online gaming platforms benefit from the real-time responsiveness and scalability of EDA.
E-commerce Application Use Case
In an e-commerce setting, EDA with serverless can streamline various operations, enhancing the customer experience and improving operational efficiency. The architecture allows for immediate responses to events, such as order placement, payment confirmation, and inventory updates.
Consider an e-commerce application using the following event flow:
- Order Placement: A customer places an order. This action triggers an “order_placed” event.
- Event Processing: The serverless event bus (e.g., Amazon EventBridge, Azure Event Grid) receives the “order_placed” event.
- Event Routing and Functions: The event bus routes the event to multiple serverless functions. These functions perform various tasks. For instance:
- A function updates the order database.
- A function sends a confirmation email to the customer.
- A function updates inventory levels.
- A function initiates payment processing.
- Payment Confirmation: Upon successful payment, a “payment_confirmed” event is generated.
- Shipping and Fulfillment: The “payment_confirmed” event triggers serverless functions responsible for:
- Generating shipping labels.
- Notifying the warehouse.
- Updating the order status to “shipped”.
- Real-time Updates: Throughout the process, customers receive real-time updates on order status via email, SMS, or in-app notifications, all driven by event triggers.
This architecture ensures a seamless and responsive user experience. The use of serverless functions ensures scalability. For example, during peak sales periods, the system can automatically scale up the processing capacity to handle a surge in orders. This architecture also facilitates the integration of third-party services, such as payment gateways and shipping providers, through event-driven interactions.
IoT Domain Use Case: Event Handling
The Internet of Things (IoT) domain is inherently event-rich, making EDA with serverless an ideal architecture for managing the continuous flow of data from connected devices. This approach enables efficient data processing, real-time monitoring, and automated responses to device events.
Consider a smart home system with various connected devices:
- Device Event Generation: Devices such as smart thermostats, security cameras, and door sensors generate events. For example:
- The thermostat detects a change in temperature (“temperature_changed” event).
- A security camera detects motion (“motion_detected” event).
- A door sensor detects a door opening (“door_opened” event).
- Event Ingestion: IoT devices send events to a cloud-based event bus (e.g., AWS IoT Core, Azure IoT Hub).
- Event Processing and Actions: The event bus routes events to serverless functions that handle specific actions:
- Temperature Control: The “temperature_changed” event triggers a function to adjust the thermostat to the desired temperature.
- Security Alerts: The “motion_detected” event triggers a function to send a notification to the homeowner and potentially record video.
- Home Automation: The “door_opened” event can trigger a function to turn on lights or disarm the security system.
- Data Storage and Analytics: Events can also be routed to data storage services (e.g., Amazon S3, Azure Blob Storage) for historical analysis and trend identification.
- Real-time Monitoring: Dashboards can be updated in real-time, providing homeowners with up-to-the-minute status updates.
This architecture allows for a responsive and automated smart home environment. The serverless nature ensures that the system can handle a large number of devices and events without requiring manual scaling. For instance, if a large number of devices simultaneously generate events, the serverless functions automatically scale to handle the increased load.
Tools and Technologies
Building robust and scalable Event-Driven Architectures (EDAs) with serverless computing necessitates leveraging a suite of specialized tools and technologies. These tools facilitate the design, development, deployment, and management of event-driven systems. The selection of appropriate technologies significantly impacts the performance, scalability, and maintainability of the overall architecture.
Popular Serverless Platforms
The adoption of serverless computing has grown rapidly, with several platforms emerging as industry leaders. These platforms offer a range of services and features tailored to the needs of developers building event-driven applications.
- AWS Lambda: Amazon Web Services (AWS) Lambda is a compute service that allows developers to run code without provisioning or managing servers. It supports multiple programming languages and integrates seamlessly with other AWS services, making it a popular choice for building serverless applications. AWS Lambda’s pay-per-use pricing model and automatic scaling capabilities contribute to its appeal. For instance, a retail company can utilize AWS Lambda to process real-time order events triggered by Amazon SQS, triggering inventory updates and shipment notifications.
- Azure Functions: Microsoft Azure Functions is a serverless compute service that enables developers to execute code in response to various triggers, such as HTTP requests, timers, and events from other Azure services. Azure Functions supports multiple programming languages and offers integration with Azure services like Event Hubs and Service Bus. Azure Functions, similar to AWS Lambda, offers features like automatic scaling and pay-per-execution pricing, making it suitable for event-driven applications.
An example is an e-commerce platform leveraging Azure Functions to process customer registration events from Azure Event Hubs, subsequently triggering welcome email campaigns and user profile creations in a database.
- Google Cloud Functions: Google Cloud Functions is a serverless execution environment for building event-driven applications. It allows developers to write code in response to events from Google Cloud services, HTTP requests, or other triggers. Google Cloud Functions supports multiple programming languages and integrates with Google Cloud services like Cloud Pub/Sub and Cloud Storage. Google Cloud Functions offers automatic scaling and pay-per-use pricing.
For example, a media company can use Google Cloud Functions to automatically generate thumbnails and transcode video files upon upload to Google Cloud Storage, triggered by the Cloud Storage event.
- Cloudflare Workers: Cloudflare Workers provides a serverless execution environment that runs on Cloudflare’s global network. It allows developers to deploy code that can respond to HTTP requests, events, and other triggers. Cloudflare Workers supports multiple programming languages and offers features like edge computing capabilities, allowing developers to deploy code closer to users, improving performance. A content delivery network (CDN) can use Cloudflare Workers to personalize content based on user location or device type, improving the user experience.
Relevant Technologies and Tools for Building EDA Systems
A comprehensive toolkit is essential for building and managing event-driven architectures. The following technologies and tools are frequently employed to address various aspects of EDA development.
- Event Brokers: Event brokers are crucial components of EDA systems, facilitating the routing and delivery of events between producers and consumers. They provide features like message queuing, topic management, and event filtering.
- API Gateways: API Gateways manage incoming requests, authenticate and authorize users, and route traffic to the appropriate backend services. They often play a role in event-driven systems by exposing event-driven services via APIs.
- Monitoring and Observability Tools: Monitoring and observability tools are essential for gaining insights into the behavior of event-driven systems. These tools help track event flow, identify bottlenecks, and diagnose issues. Examples include:
- Logging: Centralized logging platforms, like the ELK Stack (Elasticsearch, Logstash, Kibana) or Splunk, aggregate logs from various services to provide a comprehensive view of system activity.
- Tracing: Distributed tracing tools, such as Jaeger or Zipkin, track requests as they traverse different services in a distributed system, helping identify performance issues and dependencies.
- Metrics: Metric collection and monitoring systems, like Prometheus and Grafana, track key performance indicators (KPIs) and provide real-time dashboards for system health monitoring.
- CI/CD Pipelines: Continuous Integration and Continuous Delivery (CI/CD) pipelines automate the build, testing, and deployment processes. They are essential for ensuring that changes are delivered quickly and reliably to production environments.
- Serverless Frameworks: Serverless frameworks simplify the deployment and management of serverless functions and related resources. Examples include the Serverless Framework and AWS SAM (Serverless Application Model).
- Event Schema Registries: Event schema registries, like those offered by Confluent or Apicurio, provide a centralized repository for event schemas. They ensure that events are serialized and deserialized consistently across different services, promoting data consistency.
Comparison of Event Brokers
The selection of an event broker is a critical architectural decision. The following table compares several popular event brokers, highlighting their key features and capabilities.
| Feature | Apache Kafka | RabbitMQ | Amazon SQS | Google Cloud Pub/Sub |
|---|---|---|---|---|
| Architecture | Distributed streaming platform | Message broker based on the AMQP protocol | Fully managed message queuing service | Fully managed real-time messaging service |
| Scalability | Highly scalable, designed for high throughput and low latency | Scalable, supports clustering and federation | Scales automatically based on demand | Scales automatically based on demand |
| Message Persistence | Persistent storage of events | Persistent message storage | Messages are stored in queues until consumed | Messages are stored in the system |
| Message Ordering | Guaranteed message ordering within a partition | Message ordering can be configured | Message ordering is not guaranteed | Message ordering is not guaranteed by default, but can be achieved using keys |
| Use Cases | Real-time data streaming, event processing, log aggregation | General-purpose messaging, microservices communication | Decoupling applications, asynchronous task processing | Real-time data streaming, event-driven architectures |
Closing Notes
In conclusion, the integration of Event-Driven Architecture with serverless computing offers a compelling approach to building modern, scalable applications. This architectural pattern, characterized by its asynchronous nature and automated resource management, provides significant advantages in terms of responsiveness, scalability, and cost efficiency. By understanding the core principles, implementation strategies, and potential challenges, developers can harness the power of EDA with serverless to create robust, adaptable, and highly performant systems that meet the demands of today’s dynamic environments.
The shift towards this architecture signifies a significant advancement in the evolution of software development, offering new possibilities for innovation and efficiency.
FAQ Section
What is an event in the context of Event-Driven Architecture?
An event is a significant occurrence or state change within a system, such as a user clicking a button, a database update, or a sensor reading. Events are immutable and contain relevant data about what happened.
How does serverless improve the performance of an EDA system?
Serverless platforms automatically scale resources based on event volume, ensuring that event processing scales elastically. This eliminates the need for manual provisioning and management of infrastructure, allowing for high availability and reduced latency.
What are the main differences between message queues and event buses in an EDA system?
Message queues are primarily used for asynchronous communication and reliable message delivery, ensuring that messages are processed even if consumers are temporarily unavailable. Event buses, on the other hand, are designed for broadcasting events to multiple subscribers, enabling a many-to-many relationship and supporting more complex event routing.
What are the security considerations when implementing EDA with serverless?
Security considerations include securing event sources, authenticating and authorizing event consumers, and protecting data in transit and at rest. Proper configuration of access control lists (ACLs) and encryption are crucial.
How can I monitor and debug an event-driven serverless application?
Monitoring and debugging involve logging events, tracing event flows, and using distributed tracing tools. Serverless platforms often provide built-in monitoring and logging capabilities, and third-party tools can be integrated for more comprehensive insights.