Availability zones (AZs) are a fundamental aspect of cloud computing, providing a robust foundation for high-availability (HA) deployments. This exploration delves into the core principles of AZs, examining their role in ensuring application uptime and disaster resilience. We’ll cover crucial aspects from defining AZs and their benefits to designing applications that leverage multiple AZs, and the complexities of data replication and synchronization.
We’ll also consider the practicalities of implementation, monitoring, and security.
Understanding how to effectively use AZs is crucial for architects and engineers aiming to build highly resilient and performant applications in cloud environments. This detailed guide will provide practical insights into various aspects of AZ implementation, including the technical considerations and the potential cost implications.
Defining Availability Zones
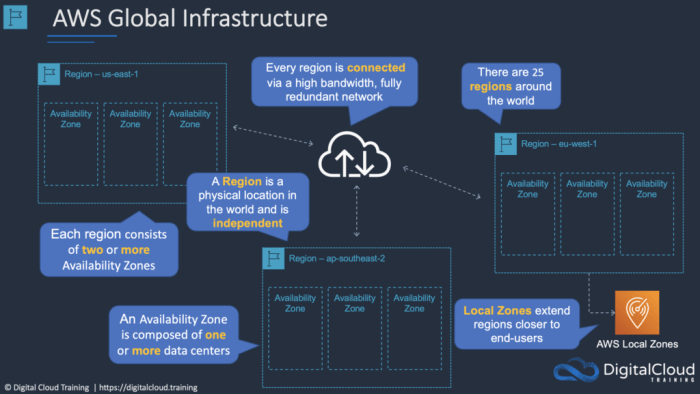
An availability zone (AZ) is a geographically isolated location within a region. It’s a fundamental building block for high availability and fault tolerance in cloud computing environments. Understanding AZs is crucial for architects designing and deploying applications that require minimal downtime and maximum resilience.AZs are distinct from data centers, though they may reside within the same physical location.
This isolation is key to preventing widespread outages if a single data center experiences a failure. The geographical separation, combined with independent power, cooling, and network infrastructure, ensures high availability for services deployed within them.
Characteristics of an Availability Zone
AZs are uniquely characterized by their geographical separation and independence. This isolation is designed to prevent a single point of failure. Multiple AZs within a region provide a robust and resilient infrastructure for applications and services.
- Geographical Isolation: AZs are physically separated locations, often spanning multiple data centers within a region. This separation minimizes the impact of local disasters, such as natural calamities or power outages.
- Independent Infrastructure: Each AZ has its own independent power, cooling, and network infrastructure. This independence is vital for preventing cascading failures.
- Fault Tolerance: The geographical and infrastructural independence of AZs dramatically enhances the fault tolerance of cloud services. Deploying applications across multiple AZs ensures continuous operation even if one AZ is compromised.
Comparison with Other Cloud Deployment Models
The following table illustrates the key distinctions between AZs and other cloud deployment models, focusing on the concept of shared resources.
| AZ | Region | Data Center | Shared Resources |
|---|---|---|---|
| A geographically isolated location within a region. | A collection of AZs. | A physical facility housing servers and networking equipment. | No shared resources between AZs. Independent infrastructure. |
| Independent power, cooling, and network infrastructure. | Shared network infrastructure, but separate AZs. | Often shared power, cooling, and network resources within a single data center. | Shared resources are present, but contained within a single data center or region. |
| Designed for high availability and fault tolerance. | Supports multiple AZs and regions, offering a wide geographical reach. | Provides physical resources for a specific region. | AZs are specifically designed to minimize shared resource vulnerabilities. |
Benefits of Using Availability Zones for High Availability (HA)
Availability Zones (AZs) play a critical role in enhancing application availability and resilience. By distributing resources across geographically separate locations, AZs effectively mitigate the risk of service disruption due to localized failures. This separation dramatically improves the overall reliability and performance of applications.Availability Zones are fundamental to achieving high availability. They provide a robust foundation for applications, enabling them to operate reliably and consistently.
By ensuring redundancy and independence, AZs significantly reduce the risk of outages. This approach is vital for modern applications requiring constant uptime and high levels of user engagement.
Enhanced Application Availability
AZs contribute to enhanced application availability by distributing components across multiple, independent locations. This geographic separation ensures that even if one AZ experiences a failure, the application remains operational in other, unaffected zones. This strategy minimizes the impact of localized outages, maintaining continuous service to end-users.
Mitigation of Single Points of Failure
A crucial benefit of AZs is their ability to mitigate single points of failure. Traditional architectures often rely on a single location for all resources, making the entire system vulnerable to localized events. By deploying applications across multiple AZs, organizations distribute the workload and eliminate the dependency on a single location, significantly reducing the likelihood of widespread outages.
This distributed approach is paramount for ensuring business continuity.
Contribution to Fault Tolerance and Disaster Recovery
Availability Zones contribute significantly to fault tolerance and disaster recovery. Fault tolerance is the ability of a system to continue operating even if some components fail. AZs achieve this by replicating applications and data across different physical locations. This replication ensures that the system can continue operating even if a particular AZ experiences a failure. Furthermore, AZs play a key role in disaster recovery by providing a backup location for operations in the event of a significant disaster in a primary region.
This redundancy safeguards against prolonged service disruptions and allows for a swift and efficient recovery process.
Advantages of HA Solutions Utilizing AZs
| Feature | Benefit | Explanation |
|---|---|---|
| Improved Uptime | Reduced downtime due to failures | Applications operate continuously even if a single AZ is affected, minimizing disruptions to users. |
| Reduced Downtime | Faster recovery from outages | The ability to quickly restore services from a healthy AZ in the event of an outage enhances recovery time. |
| Enhanced Fault Tolerance | High resilience against failures | By distributing components across AZs, the system remains operational even if parts of the system fail. |
| Improved Disaster Recovery | Faster recovery from major incidents | AZs provide alternative locations for operations, allowing quick recovery from significant events such as natural disasters. |
| Increased Reliability | Higher confidence in application availability | The distributed architecture of AZs improves the overall reliability of applications, ensuring consistent service delivery. |
Designing Applications for Availability Zones
Designing applications for availability zones (AZs) requires a careful consideration of how components are distributed across multiple AZs to ensure high availability. This approach minimizes the risk of a single point of failure and guarantees continued service even if one AZ experiences an outage. A well-designed application architecture will distribute data and functionality across multiple AZs, enabling fault tolerance and maximizing uptime.Effective application design in multiple AZs involves careful planning and strategic component distribution, enabling the application to continue operating even if an entire AZ is impacted.
This resilience is crucial in a high-availability architecture. By strategically deploying components across multiple AZs, businesses can enhance application reliability and minimize the impact of failures.
Basic Application Architecture
A basic application architecture leveraging multiple AZs can be visualized as a distributed system. Front-end components (web servers, APIs) reside in multiple AZs, ensuring that if one AZ experiences an outage, other AZs remain operational. This distributed approach significantly improves application availability.
Distributing Application Components
To ensure optimal distribution across multiple AZs, applications must be carefully designed. The most critical components, such as the application logic layer and database, should be replicated in different AZs. This strategy ensures that if one AZ is affected by a failure, the application can still function from the other AZs. The key is to avoid single points of failure by having redundant copies of essential components.
Load Balancers and Distributed System Components
Load balancers play a crucial role in a high-availability architecture. They distribute incoming traffic across multiple instances of the application in different AZs. This ensures that the application can handle a high volume of requests even during peak times. Sophisticated load balancers can also monitor the health of the instances and automatically redirect traffic to healthy instances, maintaining optimal performance and resilience.
A robust load balancer is essential for distributing traffic evenly and efficiently across multiple AZs, ensuring high availability and optimal performance.
Other distributed system components, like message queues and caching systems, should also be deployed across AZs. These components enable communication and data sharing between different parts of the application, and their redundancy across multiple AZs ensures seamless operation even in the face of failures.
Database Deployment Across AZs
Databases, both relational and NoSQL, can be deployed across AZs. For relational databases, techniques like database mirroring or clustering allow for data replication across AZs. This enables read replicas in other AZs to maintain application functionality even if the primary database is unavailable.
| Database Type | Deployment Strategy |
|---|---|
| Relational | Database mirroring or clustering across AZs |
| NoSQL | Replication across AZs using appropriate NoSQL strategies. |
NoSQL databases, too, offer replication capabilities that can be utilized to achieve high availability across AZs. Choosing the right replication strategy for a specific NoSQL database is critical to ensuring that data remains consistent and accessible even in the event of an AZ failure.
Data Replication and Synchronization Across Availability Zones
Ensuring high availability (HA) in cloud deployments requires robust data replication strategies across multiple availability zones (AZs). This ensures business continuity and minimizes service disruptions. Data replication methods play a crucial role in this process, allowing for seamless failover and maintaining data consistency.Data replication across availability zones is a critical aspect of achieving high availability. Different replication strategies offer varying degrees of performance and consistency, impacting the overall resilience of applications and the responsiveness of services.
Understanding these trade-offs is essential for selecting the appropriate approach for specific use cases.
Data Replication Methods for AZ Deployments
Various data replication methods are suitable for replicating data between AZs. Choosing the right method depends on the specific needs of the application, including the desired level of consistency and performance.
- Asynchronous Replication: This method replicates data in a non-real-time manner. Data is copied to the secondary zone after a certain delay, often suitable for applications with less stringent consistency requirements. This approach typically prioritizes faster replication speeds. Examples include applications where near real-time updates aren’t critical, such as logging or analytics systems.
- Synchronous Replication: In synchronous replication, data is copied to the secondary zone in real-time. This ensures data consistency, as both zones reflect the most up-to-date information. This method is generally more complex to implement and can be slower than asynchronous replication, particularly in high-volume environments. Applications that require absolute data consistency, such as financial transactions or mission-critical systems, often leverage synchronous replication.
- Multi-AZ Database Deployments: Many database services offer specific features for multi-AZ deployments. These solutions often combine synchronous or asynchronous replication methods with failover mechanisms. The approach often involves automatically replicating data to a standby database in another AZ, enabling quick failover in case of a primary zone outage. This method ensures high availability and minimizes data loss.
- Third-Party Replication Tools: Various third-party tools and services are available for replicating data across availability zones. These tools can offer specialized features tailored to specific application needs. This option can be particularly beneficial for complex deployments requiring specialized functionality or integration with existing infrastructure.
Process of Replicating Data Between AZs
The process of replicating data involves several key steps. The specific details vary based on the chosen replication method and the underlying infrastructure.
- Data Identification and Preparation: The process begins by identifying the data that needs to be replicated. This may involve selecting specific tables, databases, or data objects. Data preparation steps might include formatting or transforming data for optimal replication.
- Replication Setup: Configuring the replication process is crucial. This involves setting up the replication connection between the source and target availability zones. The configuration might include specifying the replication frequency, data transfer protocols, and other relevant parameters.
- Data Transfer: The actual data transfer occurs during the replication process. The chosen method will dictate the speed and consistency of the data transfer. Synchronous replication ensures that the data is transferred and synchronized in real-time.
- Verification and Validation: After the replication process, verification and validation are essential. This ensures the accuracy and completeness of the replicated data in the target zone. Methods like checksums and data consistency checks can be used for validation.
Performance and Consistency Comparison
Replication strategies differ in performance and consistency characteristics. A trade-off often exists between speed and data accuracy.
| Replication Method | Performance | Consistency | Use Case |
|---|---|---|---|
| Asynchronous | High | Near Real-time | Applications with less stringent consistency requirements. |
| Synchronous | Lower | Real-time | Applications requiring absolute data consistency. |
| Multi-AZ Databases | High (often) | High (often) | Database applications needing HA and data consistency. |
Implications of Data Consistency and Latency in Cross-AZ Deployments
Data consistency and latency are crucial considerations in cross-AZ deployments. Maintaining data consistency ensures data integrity and accuracy across multiple availability zones. Latency, or the time it takes for data to be replicated, affects the responsiveness of applications.Understanding the implications of data consistency and latency is essential for ensuring the stability and responsiveness of services. Choosing the right replication method is vital for achieving the desired level of consistency and performance in a cross-AZ deployment.
Implementing High Availability with Specific Cloud Services
Cloud platforms offer a range of services designed to facilitate high availability (HA) deployments within availability zones (AZs). Leveraging these services allows organizations to architect resilient applications capable of withstanding failures and maintaining service continuity. This section details how cloud-based compute, storage, and networking services enable HA implementations within AZs.
Compute Services and High Availability
Compute services, like virtual machines (VMs), are fundamental components in any application. Cloud providers offer mechanisms to ensure high availability of these VMs within AZs. This involves replicating VMs across multiple AZs to maintain operation even if one AZ experiences an outage. Furthermore, load balancers distribute traffic across these replicated VMs, ensuring uninterrupted service delivery.
- Instance Replication: Cloud providers offer options for automatically replicating instances across multiple AZs. This ensures that if one instance fails, the application can seamlessly transition to a healthy replica in a different AZ. For example, Amazon EC2 Auto Scaling can automatically create and manage instances in multiple AZs, maintaining availability even when an AZ faces issues.
- Load Balancing: Load balancers are critical for distributing traffic across multiple instances. They ensure that incoming requests are routed to available instances, preventing overload on any single instance and maximizing resource utilization. For example, Azure Load Balancer can distribute traffic across multiple VMs in different AZs, providing high availability and fault tolerance.
- Automated Scaling: Automated scaling capabilities allow applications to dynamically adjust the number of instances based on demand. This is crucial for HA as it ensures that there are sufficient resources available during peak usage periods and that resources are released when demand decreases, preventing waste and optimizing costs.
Storage Services and High Availability
Storage services play a vital role in HA deployments. Cloud providers offer options for replicating data across multiple AZs to ensure data availability even in case of failures. This replication can be automatic, ensuring that data remains accessible from multiple locations.
- Data Replication: Cloud storage services support various data replication strategies. These strategies can be configured to automatically replicate data across AZs, maintaining data integrity and accessibility even in the event of a localized failure. For example, Amazon S3 can replicate data across multiple AZs for disaster recovery and business continuity.
- Distributed Storage: Some storage solutions employ distributed architectures, ensuring data redundancy and fault tolerance. Data is spread across multiple storage nodes within the AZ, ensuring that the failure of a single node does not compromise data availability.
Networking Services and High Availability
Networking services are critical for ensuring communication and connectivity across different components of an application. Cloud providers offer features for HA in networking that can facilitate resilience and maintain connectivity in the event of an AZ outage.
- Redundant Connectivity: Cloud providers often offer multiple network connections within an AZ. This redundancy ensures that applications have multiple paths for communication, mitigating the impact of a network failure within a single AZ. For example, Google Cloud Platform offers multiple network interfaces for instances to maintain redundancy and high availability.
- Global Load Balancing: Global load balancers distribute traffic across multiple regions, providing even higher levels of availability and fault tolerance. They are essential for applications with a wide user base or deployments across different geographic regions.
Cloud Services and High Availability Capabilities
| Service | Feature | AZ Support | Description |
|---|---|---|---|
| Amazon EC2 | Auto Scaling, Instance Replication | Yes | Enables automatic scaling and replication of EC2 instances across AZs for high availability. |
| Amazon S3 | Cross-Region Replication | Yes | Provides replication of S3 data across multiple regions and AZs for disaster recovery and data redundancy. |
| Azure VMs | Availability Sets, Load Balancing | Yes | Offers Availability Sets for grouping VMs across AZs and load balancing for traffic distribution. |
| Google Compute Engine | Zone-based instances, Load Balancing | Yes | Supports zone-based instances and load balancing to ensure availability within and across AZs. |
Monitoring and Maintaining Availability Zone Deployments
Effective monitoring and maintenance of applications deployed across Availability Zones (AZs) is crucial for ensuring high availability and minimizing downtime. Proactive identification and resolution of potential issues are key to maintaining service levels and user satisfaction. A well-defined monitoring strategy, coupled with robust logging and auditing, enables swift responses to incidents and facilitates continuous improvement of the system.
Key Metrics for Monitoring Application Health
Monitoring the health and performance of applications across AZs requires tracking various key metrics. These metrics provide insights into the operational status of the application instances and the underlying infrastructure. Crucially, they help pinpoint potential bottlenecks and predict future issues.
- Application Response Time: Tracking average response time for application requests across different AZs is essential. Variations in response times may indicate performance degradation in specific AZs or overloaded resources. Monitoring these metrics allows for early detection of potential service disruptions.
- Resource Utilization: CPU, memory, and network utilization rates for each application instance within each AZ need to be monitored. High utilization levels might suggest resource contention or capacity issues that could lead to performance degradation. Monitoring resource utilization proactively helps in optimizing resource allocation.
- Error Rates: The frequency of errors and exceptions in the application logs, including error codes, provides insights into potential application failures or stability issues. Analyzing error rates in different AZs helps to identify any regional issues.
- Database Performance: For applications relying on databases, monitoring database response times and query execution times is vital. Poor database performance can lead to application slowdowns. Monitoring database metrics allows for quick identification of potential database bottlenecks.
Methods for Detecting and Resolving Issues
Proactive issue detection is paramount in maintaining high availability. A multi-layered approach, combining automated monitoring tools with manual review, is essential for promptly addressing issues and preventing widespread outages.
- Automated Monitoring Tools: Implementing monitoring tools that continuously track the metrics discussed above allows for early detection of anomalies and potential issues. These tools often generate alerts when thresholds are crossed, enabling swift responses to emerging problems. Examples include cloud-based monitoring services and custom-built monitoring scripts.
- Alerting Systems: Configure alerting systems to trigger notifications when critical metrics deviate from predefined thresholds. Alerts can be sent to system administrators, developers, and other stakeholders, ensuring prompt action. The alerts should include detailed information about the issue, affected AZs, and other relevant context.
- Root Cause Analysis: When issues arise, conducting a thorough root cause analysis is critical for understanding the underlying problem. This analysis involves reviewing logs, monitoring data, and investigating infrastructure components to determine the source of the issue. Root cause analysis helps in preventing similar issues from recurring.
Importance of Logging and Auditing in AZ Environments
Comprehensive logging and auditing are vital components of a robust monitoring strategy. Logs and audit trails provide a detailed record of events, enabling thorough analysis of system behavior and issue resolution.
- Detailed Event Logging: Logging all significant events, including application interactions, database queries, and system activities, provides a complete record of events that transpired. This allows for retrospective analysis to understand the sequence of events leading to an issue.
- Security Auditing: Auditing logs provide detailed information about user activity and access attempts. Security auditing is crucial for identifying and responding to potential security breaches or unauthorized access attempts.
- Compliance: Maintaining comprehensive logs and audit trails are often required for regulatory compliance. Logs help demonstrate adherence to industry standards and regulations.
Monitoring Dashboard for HA Applications
A well-designed monitoring dashboard is essential for effectively managing HA applications across multiple AZs. The dashboard should provide a centralized view of application performance, allowing for rapid identification of issues and effective resolution.
| Metric | Visualization | Actionable Insights |
|---|---|---|
| Application Response Time | Graph showing response time distribution across AZs | Identify AZs with high response times and potential bottlenecks |
| Resource Utilization | Gauge chart showing CPU, memory, and network utilization per AZ | Detect resource saturation in specific AZs |
| Error Rates | Table showing error counts per AZ and error type | Identify regions with high error rates and investigate underlying causes |
| Database Performance | Graph showing database query response times | Detect slow database queries and optimize database performance |
Security Considerations in Availability Zones
Ensuring the security of applications and data deployed across multiple availability zones (AZs) is paramount. Proper security measures are crucial to protect against threats and maintain the integrity and confidentiality of sensitive information. This section delves into specific security considerations unique to AZ deployments, outlining potential risks and strategies for mitigation.
Security Measures Specific to AZ Deployments
Implementing robust security measures requires careful planning and execution. This involves not only securing individual AZs but also ensuring secure communication and data transfer between them. This necessitates a holistic approach that considers the entire infrastructure. Security measures specific to AZ deployments often involve the use of specialized tools and techniques for monitoring and controlling access to resources across multiple zones.
Potential Security Risks Associated with AZ Deployments
Several security risks can arise when deploying applications across multiple AZs. These risks can range from compromised access controls to vulnerabilities in data replication mechanisms. A key risk is the potential for unauthorized access to data or applications residing in one AZ, potentially impacting the entire deployment. Other concerns include network security vulnerabilities, misconfigurations in security policies, and inadequate monitoring of security events.
Securing Data and Applications Across Multiple AZs
Securing data and applications across multiple AZs demands a comprehensive strategy. This involves implementing strong access controls, encryption of data at rest and in transit, and secure communication channels between AZs. The strategy should also encompass robust monitoring and logging mechanisms to detect and respond to security incidents promptly. Regular security audits and penetration testing can also help identify vulnerabilities and ensure the security posture of the AZ deployment remains strong.
Security Best Practices for AZ Environments
Implementing strong security practices in AZ deployments is crucial for mitigating risks. The table below Artikels key security best practices, addressing the risk, mitigation strategy, and implementation details.
| Risk | Mitigation Strategy | Implementation Details |
|---|---|---|
| Unauthorized Access to Resources | Implement strict access controls and role-based access control (RBAC) | Utilize Identity and Access Management (IAM) services to manage user permissions. Employ strong passwords and multi-factor authentication (MFA). Configure firewall rules to restrict network access to only authorized resources. |
| Data Breaches during Replication | Encrypt data both in transit and at rest across all AZs. | Employ encryption protocols like Transport Layer Security (TLS) for communication between AZs. Implement encryption at the database level or file system level. Regularly review and update encryption keys. |
| Compromised Network Infrastructure | Segment the network and implement network security tools. | Establish virtual networks and subnets to segment access between different parts of the application. Use intrusion detection and prevention systems (IDS/IPS) to monitor network traffic. Regularly update security patches on all network devices. |
| Inadequate Monitoring of Security Events | Implement robust logging and monitoring systems. | Configure logging to capture security events across all AZs. Use security information and event management (SIEM) tools to correlate and analyze security logs. Establish alerts and automated responses for critical security events. |
Cost Considerations of Using Availability Zones
Deploying applications across multiple Availability Zones (AZs) in a cloud environment offers enhanced resilience and high availability. However, this approach also has associated costs that need careful consideration. Understanding the pricing models and comparing the total cost of ownership (TCO) with single-region deployments is crucial for making informed decisions.The costs associated with AZ deployments are multifaceted, encompassing compute, storage, networking, and data transfer charges.
Different cloud providers employ various pricing structures, and the actual costs will vary based on the specific resources utilized, their configurations, and the volume of data transferred between AZs. Optimizing resource utilization and minimizing data transfer across AZs can significantly impact the overall cost.
Pricing Models for AZ Deployments
Cloud providers offer flexible pricing models for resources deployed across AZs. These models typically involve charges for compute instances, storage volumes, network bandwidth, and data transfer. Understanding these pricing components is vital for accurately forecasting and controlling costs. For instance, compute instances in different AZs might have varying prices depending on their specifications and demand.
Comparing AZ Deployments with Single-Region Deployments
The cost comparison between AZ deployments and single-region deployments depends on several factors, including the application’s architecture, the volume of data transferred between AZs, and the chosen pricing model.A single-region deployment is generally less expensive for simple applications, as it avoids the cost of data replication and transfer between AZs. However, this approach often compromises high availability, making it susceptible to single points of failure.
On the other hand, an AZ deployment, though more complex, can reduce downtime significantly, leading to higher operational efficiency and fewer lost revenue opportunities.
Detailed Cost Analysis of a Sample Application
Consider a web application deployed across two AZs. The application utilizes a web server instance in each AZ, a database instance in a separate AZ, and a load balancer distributing traffic across the web servers. Data replication between the database instances in different AZs incurs transfer costs. The overall cost will also include the cost of the load balancer, storage, and network bandwidth.
| Resource | Cost per AZ | Total Cost (2 AZs) |
|---|---|---|
| Web Server Instance | $10/month | $20/month |
| Database Instance | $15/month | $30/month |
| Load Balancer | $5/month | $5/month |
| Data Replication (2x) | $2/month | $4/month |
| Total | $60/month |
This example illustrates the potential costs involved in an AZ deployment. It’s crucial to remember that these costs are estimations, and the actual figures will depend on the specific configurations, pricing models, and utilization patterns of the chosen cloud provider.
Potential Savings from Improved Uptime and Reduced Downtime
The improved uptime and reduced downtime offered by AZ deployments can translate into substantial cost savings. By preventing service disruptions, applications can avoid significant revenue losses and associated operational costs.
Minimizing downtime translates into significant savings by preventing costly revenue losses and operational expenses.
For instance, a business experiencing frequent downtime due to single-region failures might incur substantial costs related to lost productivity, customer dissatisfaction, and potential legal liabilities. An AZ deployment, by providing redundancy, can drastically reduce these losses. Estimating the potential savings from improved uptime requires considering the application’s revenue streams, customer churn rates, and operational costs associated with downtime.
Illustrative Examples of AZ Deployments

Deploying applications across multiple availability zones (AZs) is a crucial aspect of achieving high availability and fault tolerance. Real-world examples demonstrate the practical application and value of this strategy. Understanding how various applications leverage AZs provides valuable insights into the benefits and challenges associated with this approach.
E-commerce Platform Deployment
E-commerce platforms experience high traffic volumes, making availability critical. A large online retailer might deploy its web servers and databases across multiple AZs. For example, customer-facing web servers could be replicated in AZ1 and AZ2, while database servers are in AZ3 and AZ4. This setup ensures that if one AZ experiences an outage, the application remains operational in other zones.
The challenge often lies in maintaining data consistency across these zones, requiring robust data replication mechanisms. Solutions include synchronous or asynchronous replication techniques, which depend on the desired level of consistency and the application’s tolerance for latency.
Cloud-Based Gaming Platform
Cloud-based gaming platforms demand consistent performance and low latency for players. By distributing game servers and player data across multiple AZs, the platform can minimize latency and maintain a seamless gaming experience. For instance, game servers handling specific regions might be located in AZs geographically close to those regions. This reduces latency and ensures a smoother experience for players worldwide.
The challenge involves managing the complex network traffic between servers in different AZs. Solutions include optimizing network configurations and utilizing low-latency connections.
Financial Transaction Processing System
Financial institutions require highly available systems to process transactions reliably. A bank’s transaction processing system could have transaction servers in AZ1 and AZ2, with database servers replicated in AZ3 and AZ4. This configuration allows transactions to continue even if one AZ experiences a disruption. A critical challenge in this scenario is maintaining data consistency and ensuring ACID (Atomicity, Consistency, Isolation, Durability) properties across different AZs.
Solutions involve implementing distributed transaction management and robust data synchronization protocols.
Case Study: A Successful AZ Deployment
A global social media platform deployed its infrastructure across multiple AZs, distributing its web servers, databases, and content storage. This ensured high availability and fault tolerance. The challenge was to manage the complex interactions between services spread across different geographic locations. Solutions included the development of custom tools to monitor performance and data consistency across AZs. By monitoring key metrics such as latency and data replication success rate, the team could quickly identify and address issues.
Furthermore, comprehensive testing was crucial to ensure the system’s performance under various conditions. This included simulating failures in specific AZs to validate the redundancy and recovery mechanisms.
Advanced Topics in Availability Zones
 Region ...")
Availability Zones (AZs) offer a robust foundation for high availability (HA) deployments. However, optimizing these deployments often requires leveraging advanced features and understanding their interplay with other cloud services. This section delves into advanced techniques for building highly resilient and efficient applications within an AZ framework.
Automated Failover Mechanisms
Automated failover mechanisms are crucial for maintaining application uptime during AZ outages. These mechanisms automatically switch traffic to a backup instance or region when a primary resource becomes unavailable. Cloud providers offer various options for implementing these automated failover procedures, which range from simple manual configurations to complex, fully automated solutions. Proper configuration of these mechanisms ensures seamless transitions, minimizing service disruption.
Hybrid Cloud Deployments Utilizing AZs
Hybrid cloud deployments offer a flexible approach to managing applications across on-premises and cloud environments. Availability Zones can be incorporated into hybrid deployments, providing disaster recovery and redundancy for critical applications. By replicating data and applications across on-premises and cloud AZs, organizations can create a resilient infrastructure capable of handling a wider range of disruptions. This approach is particularly beneficial for organizations with existing on-premises infrastructure that they want to seamlessly integrate with the cloud.
Orchestration Tools in Managing Deployments Across AZs
Orchestration tools are essential for automating the deployment and management of applications across multiple AZs. These tools handle tasks such as provisioning resources, scaling instances, and coordinating deployments across AZs. Effective use of orchestration tools significantly simplifies the management of complex, multi-AZ deployments. Popular tools like Kubernetes, for example, can be configured to manage applications across AZs, ensuring that applications remain available even if one AZ experiences issues.
Interplay Between AZs and Other Cloud Services for Enhanced Resilience
Cloud providers offer a suite of services beyond AZs, and the combination of these services can greatly enhance resilience. For example, integrating load balancers with AZs distributes traffic across multiple instances in different AZs, increasing application availability. Using managed databases across multiple AZs ensures data durability and accessibility. Similarly, employing message queues across AZs allows for seamless communication between services in different AZs, increasing application resilience during disruptions.
This integrated approach is key to creating a robust, resilient cloud infrastructure.
Conclusive Thoughts
In conclusion, leveraging availability zones for high availability is a critical strategy in modern cloud computing. By understanding the concepts of AZs, the benefits they offer, and the detailed implementation steps, you can build robust applications that are resilient to failures and offer superior uptime. This comprehensive guide provides a strong foundation for understanding and applying AZs in your cloud infrastructure, ultimately leading to more reliable and efficient systems.
FAQ Guide
What is the difference between an Availability Zone (AZ) and a Region?
A Region is a geographical area, containing one or more Availability Zones (AZs). AZs are isolated locations within a Region, physically separated to mitigate single points of failure. This separation ensures high availability and fault tolerance.
How do load balancers contribute to high availability in AZ deployments?
Load balancers distribute traffic across multiple instances in different AZs. If one AZ experiences an outage, the load balancer automatically redirects traffic to the remaining healthy instances, ensuring uninterrupted service.
What are the common data replication methods used in AZ deployments?
Common data replication methods include synchronous and asynchronous replication. Synchronous replication ensures immediate data consistency, while asynchronous replication offers faster replication speeds, potentially at the cost of some latency in data consistency.
What are some key metrics to monitor for AZ deployments?
Key metrics include application uptime, response times, error rates, resource utilization (CPU, memory, storage), and network latency. Monitoring these metrics allows for proactive identification and resolution of potential issues.


