NVIDIA NVLM-1
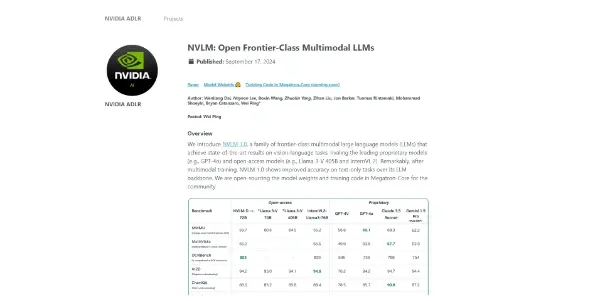
A family of advanced multimodal language models developed by NVIDIA. Outperforms proprietary models on many vision and language tasks, while improving performance on text tasks
NVIDIA NVLM-1: A Powerful, Free Multimodal Language Model
NVIDIA's NVLM-1 represents a significant advancement in the field of multimodal large language models (LLMs). This family of models demonstrates superior performance across a range of vision and language tasks, while also exhibiting improved capabilities in purely textual applications, all offered completely free of charge. This article delves into the capabilities, applications, and comparative advantages of NVLM-1.
What NVLM-1 Does
NVLM-1 is not a single model, but rather a family of advanced multimodal LLMs. This means it can understand and process both textual and visual information, unlike many LLMs that are solely text-based. Its core functionality revolves around understanding the relationship between images and text, allowing it to perform tasks that require integrating these different data modalities. This includes tasks such as image captioning, visual question answering, and image-text retrieval, surpassing the capabilities of many proprietary models in these areas. Furthermore, NVLM-1 also exhibits improved performance on standard natural language processing (NLP) tasks like text classification and summarization.
Main Features and Benefits
- Multimodality: The key feature is its ability to seamlessly process and integrate visual and textual data, leading to more comprehensive and nuanced understanding.
- Superior Performance: Benchmarks show NVLM-1 outperforming many comparable proprietary models on numerous vision-and-language tasks. This translates to more accurate and reliable results in applications.
- Improved Textual Capabilities: While excelling in multimodal tasks, NVLM-1 also shows improved performance compared to other open-source LLMs on traditional NLP tasks.
- Open-Source Accessibility: The free and open nature of NVLM-1 fosters collaboration and innovation within the AI community. Researchers and developers can freely access, adapt, and build upon the model.
- Scalability: The model architecture is likely designed for scalability, allowing for adaptation to various resource constraints and enabling deployment across different platforms.
Use Cases and Applications
The multimodal nature of NVLM-1 opens up a wide range of practical applications across diverse industries:
- Image Captioning and Description: Generating accurate and descriptive captions for images, beneficial for accessibility, content creation, and image search.
- Visual Question Answering (VQA): Answering questions about the content of images, useful for educational tools, image analysis, and customer service chatbots.
- Image-Text Retrieval: Efficiently searching and retrieving images based on textual descriptions, improving the functionality of image databases and search engines.
- Robotics and Autonomous Systems: Integrating visual perception with natural language understanding for improved robot control and interaction with the environment.
- Medical Image Analysis: Assisting in the interpretation of medical images, potentially accelerating diagnosis and treatment planning.
- Content Creation and Editing: Generating creative text formats based on images, helping with advertising copy, social media posts and more.
Comparison to Similar Tools
While direct comparisons require access to specific benchmark results, NVLM-1 distinguishes itself through a combination of factors. Many other multimodal models are either proprietary (and therefore inaccessible or expensive), less performant, or lack the breadth of capabilities demonstrated by NVLM-1. Open-source alternatives may exist, but NVLM-1's superior performance on key benchmarks and its comprehensive feature set establish it as a leading contender in the field.
Pricing Information
NVIDIA offers NVLM-1 completely free of charge. This open-source approach significantly reduces the barrier to entry for researchers and developers, enabling broader adoption and fostering innovation in the AI community.
Conclusion
NVIDIA NVLM-1 represents a significant contribution to the field of multimodal LLMs. Its superior performance, open-source accessibility, and wide range of applications position it as a valuable tool for researchers, developers, and businesses alike. The free availability of this powerful model promises to accelerate advancements and democratize access to cutting-edge AI technology.