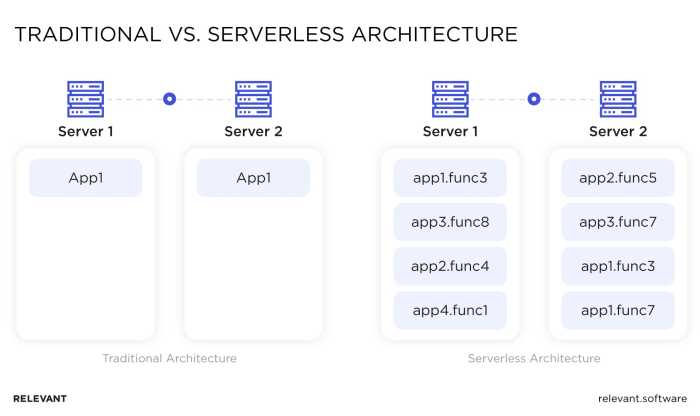
The journey of transforming a monolithic application into a serverless architecture presents a significant paradigm shift in software development. This transition, while potentially complex, unlocks a plethora of advantages, including enhanced scalability, cost optimization, and streamlined operational management. This exploration delves into the intricacies of this migration process, providing a systematic approach to navigate the challenges and leverage the benefits of serverless computing.
From understanding the fundamental characteristics of monolithic applications and the principles of serverless computing to the practical aspects of planning, decomposition, and implementation, this guide provides a structured roadmap. It covers essential aspects such as selecting appropriate serverless technologies, designing API gateways, implementing CI/CD pipelines, and ensuring robust testing and monitoring, all essential for a successful migration. The aim is to equip readers with the knowledge to assess suitability, strategize effectively, and execute a smooth transition, ultimately resulting in a more agile, scalable, and cost-efficient application infrastructure.
Understanding Monolithic Applications
Monolithic applications represent a traditional approach to software development, characterized by a unified architecture where all functionalities are bundled into a single, self-contained unit. This contrasts with modern, distributed architectures like microservices. This section will delve into the core characteristics, challenges, advantages, and disadvantages of monolithic applications, providing a comprehensive understanding of their structure and operational dynamics.
Architecture and Characteristics
Monolithic applications are designed as a single, cohesive unit. This means that all the components, from the user interface to the database interaction logic, reside within the same codebase and are deployed together. This architectural style is often associated with a layered approach, with distinct layers handling specific responsibilities.The typical architecture of a monolithic application can be represented by a layered structure:
- Presentation Layer: This layer handles the user interface and user interactions, responsible for displaying information and collecting user input. This layer typically involves technologies such as HTML, CSS, and JavaScript for web applications, or native UI frameworks for mobile or desktop applications.
- Business Logic Layer: This layer contains the core business rules and processes of the application. It orchestrates the interactions between the other layers and is responsible for making decisions based on user input and data.
- Data Access Layer: This layer manages the interaction with the database or other data storage mechanisms. It provides an abstraction layer that allows the business logic to interact with the data without needing to know the specific details of the underlying storage system.
- Database Layer: This layer stores and manages the application’s data. It can include relational databases (e.g., PostgreSQL, MySQL), NoSQL databases (e.g., MongoDB, Cassandra), or other data storage solutions.
The characteristics of a monolithic application include:
- Single Codebase: All the application’s code resides within a single repository, making it relatively easy to navigate and understand, at least initially.
- Single Deployment Unit: The entire application is deployed as a single unit. Any change, regardless of its scope, requires redeploying the entire application.
- Tight Coupling: Components within the application are often tightly coupled, meaning changes in one part of the application can have a ripple effect on other parts.
- Shared Resources: The application often shares resources like memory, CPU, and database connections.
Challenges Associated with Monolithic Architectures
Monolithic architectures, while initially simpler to develop, often present significant challenges as applications grow in size and complexity. These challenges can impact scalability, deployment, maintainability, and overall agility.
- Scalability: Scaling a monolithic application can be difficult. Because the entire application is deployed as a single unit, scaling often requires scaling the entire application, even if only a small part of it is experiencing high load. This can lead to inefficient resource utilization. For example, if only the payment processing module is overloaded, the entire application needs to be scaled, even though other modules might be underutilized.
- Deployment: Deploying changes to a monolithic application can be a time-consuming and risky process. Even small changes require redeploying the entire application, increasing the chances of downtime and errors. The deployment process can become complex and require significant coordination.
- Maintainability: As the application grows, the codebase becomes increasingly complex and difficult to understand. This can make it challenging to maintain, debug, and add new features. The tight coupling between components can make it difficult to isolate and fix bugs.
- Technology Lock-in: Monolithic applications are typically built using a single technology stack. This can limit the ability to adopt new technologies or choose the best technology for a specific task. If the application needs to adopt a new programming language or framework, the entire application may need to be rewritten or refactored.
- Development Speed: As the application grows, the development process can slow down. The large codebase and tight coupling can make it difficult for multiple developers to work on the application simultaneously without conflicts.
Advantages and Disadvantages of Monolithic Applications
Monolithic applications offer certain advantages, particularly for smaller projects or applications with relatively simple requirements. However, as the application grows, the disadvantages often outweigh the benefits.The advantages include:
- Simplicity: Monolithic applications are often simpler to develop and deploy initially, as everything is contained within a single unit.
- Easier Testing: Testing is generally straightforward because all components are readily available within the same application context.
- Performance: Inter-component communication is often faster in monolithic applications because components communicate through in-memory function calls rather than network calls.
- Centralized Monitoring: Monitoring and logging are often simpler to implement, as all application components are located within a single application.
The disadvantages include:
- Scalability Challenges: As discussed above, scaling can be difficult and resource-intensive.
- Deployment Complexity: Deploying changes can be slow and risky.
- Maintainability Issues: Large codebases are difficult to maintain and understand.
- Technology Lock-in: Limited flexibility in technology choices.
- Development Bottlenecks: Slow development speed as the application grows.
- Risk of Failure: A single point of failure. If any part of the application fails, the entire application can be affected.
Introduction to Serverless Computing
Serverless computing represents a paradigm shift in cloud computing, moving away from the traditional model of managing and maintaining underlying infrastructure. Instead, developers focus solely on writing and deploying code, while the cloud provider handles all aspects of server management, scaling, and resource allocation. This approach significantly impacts application development and operational strategies, offering a more agile and cost-effective alternative.
Defining Serverless Computing and Its Core Principles
Serverless computing is a cloud execution model where the cloud provider dynamically manages the allocation of machine resources. This allows developers to run code without managing servers. Key principles define serverless:
- Event-Driven Architecture: Serverless applications are typically triggered by events. These events can include HTTP requests, database updates, file uploads, or scheduled timers. The architecture reacts to these events, initiating code execution.
- Function as a Service (FaaS): FaaS is the core component of serverless computing. Developers deploy individual functions (small pieces of code) that execute in response to events. These functions are stateless and designed to be short-lived.
- Automatic Scaling: The cloud provider automatically scales the resources allocated to functions based on demand. This ensures that the application can handle fluctuating workloads without manual intervention. The scaling is typically horizontal, meaning more instances of the function are created to handle increased load.
- Pay-per-Use Pricing: Users are charged only for the actual compute time and resources consumed by their functions. This can lead to significant cost savings, especially for applications with intermittent workloads.
- Statelessness: Functions are generally designed to be stateless. This means that each function invocation is independent and does not rely on the state of previous invocations. This design simplifies scaling and ensures resilience.
Benefits of Serverless Computing
Serverless computing offers several advantages over traditional infrastructure-based approaches, including:
- Cost Optimization: Serverless’s pay-per-use model can dramatically reduce costs. Users only pay for the compute time their code uses, unlike traditional models where resources are provisioned and paid for regardless of utilization. For instance, consider a web application that experiences peak traffic during business hours and low traffic overnight. With serverless, costs are significantly lower during off-peak hours compared to having servers running 24/7.
- Scalability: Serverless platforms automatically scale applications based on demand. This eliminates the need for manual scaling, ensuring applications can handle sudden traffic spikes or increased workloads. This scalability is often demonstrated during promotional events or product launches, where the ability to handle a surge in user requests is critical.
- Reduced Operational Overhead: Serverless abstracts away the complexities of server management, including provisioning, patching, and scaling. Developers can focus on writing code and delivering features rather than managing infrastructure. This reduction in operational overhead translates to faster development cycles and reduced IT staff requirements.
- Increased Developer Productivity: The focus on code and the elimination of infrastructure management allows developers to be more productive. Faster development cycles and easier deployment processes lead to quicker time-to-market for new features and applications.
- Improved Reliability: Serverless platforms often offer built-in redundancy and fault tolerance. Functions are automatically deployed across multiple availability zones, ensuring that the application remains available even if one zone experiences an outage.
Comparing Serverless with Traditional Infrastructure-Based Approaches
Traditional infrastructure-based approaches, such as using virtual machines (VMs) or containers, require developers to manage the underlying servers, including provisioning, configuration, and maintenance. Serverless computing offers a distinct contrast:
| Feature | Serverless | Traditional Infrastructure |
|---|---|---|
| Infrastructure Management | Abstracted away by the cloud provider. | Requires manual provisioning, configuration, and maintenance. |
| Scaling | Automatic, based on demand. | Requires manual scaling or the use of autoscaling groups. |
| Cost Model | Pay-per-use (compute time, requests). | Pay-per-hour or fixed cost for provisioned resources. |
| Development Focus | Code and application logic. | Infrastructure and application logic. |
| Operational Overhead | Minimal. | Significant. |
| Deployment | Simplified; often involves uploading code and configuring triggers. | More complex, involving server setup, configuration, and deployment of application packages. |
Serverless computing represents a fundamental shift in how applications are built and deployed. By abstracting away infrastructure management, it allows developers to focus on their core competency: writing code that solves problems.
Assessing the Suitability for Migration
The decision to migrate a monolithic application to a serverless architecture is a strategic one, demanding careful consideration. A thorough assessment is crucial to determine if such a migration is feasible, beneficial, and likely to succeed. This assessment involves evaluating various aspects of the application, the development team, and the business goals. Ignoring this step can lead to wasted resources, project delays, and ultimately, a failed migration.
Criteria for Evaluating Serverless Suitability
Determining if a monolithic application is a suitable candidate for serverless migration requires evaluating several key criteria. These criteria help assess the application’s characteristics and identify potential benefits and challenges.
- Application Architecture and Functionality: Serverless architectures are most effective for applications with discrete, independent functions. Consider how easily the application can be broken down into smaller, self-contained units. Applications with high levels of interdependence between modules are often more complex to migrate. For instance, an e-commerce platform with separate functionalities for product catalog management, user authentication, and payment processing, could be a good candidate for a serverless migration, as each can be handled as independent services.
- Traffic Patterns and Scalability Needs: Applications experiencing fluctuating traffic patterns, such as those with seasonal peaks or unpredictable user loads, are well-suited for serverless. Serverless platforms automatically scale resources based on demand, eliminating the need for manual scaling and potentially reducing infrastructure costs. Consider a news website that experiences surges in traffic during breaking news events. Serverless can dynamically allocate resources to handle these spikes.
- Existing Infrastructure and Technology Stack: The current infrastructure and technology stack significantly impact the migration process. Applications already deployed on cloud platforms are often easier to migrate, as the underlying infrastructure is more readily compatible with serverless services. Consider the programming languages, databases, and other services used by the application. For example, applications built with Node.js and using cloud-native databases like DynamoDB are often well-suited for serverless.
- Development Team Skills and Experience: A team’s familiarity with serverless technologies, cloud platforms, and event-driven architectures is critical for a successful migration. A team with experience in these areas will be able to adapt more quickly and effectively. Training and upskilling might be necessary if the team lacks this expertise.
- Business Goals and Objectives: The migration should align with the business’s overall goals, such as reducing costs, improving scalability, and accelerating time-to-market. Evaluate the potential return on investment (ROI) and the impact on key performance indicators (KPIs).
Application Complexity Checklist
Assessing the complexity of a monolithic application is a critical step in determining the effort and resources required for a serverless migration. This checklist provides a structured approach to evaluate different aspects of the application and identify potential challenges.
- Codebase Size and Complexity: Evaluate the size of the codebase (lines of code, number of modules) and the complexity of the code (cyclomatic complexity, code coupling). Larger and more complex codebases generally require more effort to refactor and migrate.
- Database Schema and Data Volume: Analyze the database schema, the size of the data stored, and the complexity of the data model. Applications with complex schemas, large datasets, and numerous relationships can pose challenges for migration.
- Inter-module Dependencies: Identify and analyze the dependencies between different modules within the application. High levels of coupling between modules can make it difficult to break the application into independent functions.
- Third-party Integrations: Determine the number and complexity of integrations with third-party services, such as payment gateways, APIs, and external databases. These integrations need to be re-implemented or adapted for the serverless environment.
- Testing and Deployment Pipelines: Evaluate the existing testing and deployment pipelines. The migration may require changes to these pipelines to accommodate serverless deployments and testing methodologies.
- Security Considerations: Assess the security measures implemented in the application, such as authentication, authorization, and data encryption. These measures must be carefully considered and adapted for the serverless environment.
Factors Influencing Migration Challenges
Several factors can influence the difficulty and success of a serverless migration. Understanding these factors can help anticipate challenges and plan accordingly.
- Application Size and Scope: Larger, more complex applications with extensive functionality and numerous features typically require more time, resources, and effort to migrate.
- Codebase Quality and Structure: A well-structured, modular codebase with clear separation of concerns is generally easier to migrate. Conversely, a poorly structured codebase with high levels of coupling can significantly increase the complexity.
- Team’s Serverless Experience: The development team’s familiarity with serverless technologies, cloud platforms, and event-driven architectures directly impacts the speed and efficiency of the migration.
- Cloud Provider and Services Used: The choice of cloud provider and the specific serverless services used (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) can influence the migration process. Some services may be more suitable for specific types of applications or workloads.
- Data Migration Complexity: Migrating the application’s data to a serverless-compatible database or data store can be a complex and time-consuming process, especially for large datasets.
- Integration with Existing Systems: Integrating the serverless application with existing systems, such as legacy applications or on-premises infrastructure, can present significant challenges.
- Testing and Debugging: Testing and debugging serverless applications can be more complex than traditional applications, as they involve distributed components and asynchronous operations.
- Cost Optimization: Achieving cost optimization in a serverless environment requires careful planning and monitoring. The team needs to understand how serverless services are priced and how to optimize resource usage to minimize costs.
Planning the Migration Strategy
Migrating a monolithic application to a serverless architecture necessitates meticulous planning to ensure a successful transition. A well-defined strategy minimizes risks, optimizes resource allocation, and facilitates a smoother deployment process. This section Artikels a step-by-step guide, compares different migration approaches, and provides a risk assessment framework for serverless migration projects.
Determining Scope and Setting Goals
Defining the scope and setting clear, measurable goals are fundamental to a successful serverless migration. This process involves a thorough understanding of the existing monolithic application and the desired outcomes of the migration.
- Application Analysis: Conduct a comprehensive analysis of the monolithic application. This includes identifying all functionalities, dependencies, and performance bottlenecks. Documenting the application’s architecture, including its components, their interactions, and data flows, is crucial. Use tools like static code analysis, performance profiling, and dependency graphs to gather detailed insights. This analysis forms the foundation for making informed decisions about the migration scope.
- Define Migration Goals: Establish specific, measurable, achievable, relevant, and time-bound (SMART) goals. Examples of SMART goals include: reducing infrastructure costs by X% within Y months, improving application performance by Z%, or increasing deployment frequency to N times per week. These goals provide a clear benchmark for measuring the success of the migration.
- Prioritize Features: Identify and prioritize the application features that will be migrated to serverless first. This prioritization should be based on factors such as business value, technical complexity, and potential risk. Start with features that are less complex and have a lower impact on critical business functions to mitigate risks.
- Select Serverless Services: Choose the appropriate serverless services offered by the cloud provider based on the application’s requirements. This might include services like AWS Lambda, Azure Functions, or Google Cloud Functions for compute; Amazon API Gateway, Azure API Management, or Google Cloud API Gateway for API management; and various database and storage services. Evaluate each service’s capabilities, limitations, and pricing models.
- Establish Metrics: Define key performance indicators (KPIs) to monitor the performance of the serverless application. These KPIs should align with the migration goals and include metrics such as latency, error rates, cost, and scalability. Implement monitoring and logging solutions to track these metrics and provide insights into the application’s behavior.
Comparison of Migration Strategies
Several migration strategies can be employed when moving from a monolithic application to a serverless architecture. Each strategy has its advantages and disadvantages, and the optimal choice depends on the specific application and business requirements.
- Lift-and-Shift (Rehosting): This involves migrating the entire application to a serverless environment without making any code changes. The application is essentially “lifted” from its existing infrastructure and “shifted” to a serverless platform. This approach is the fastest way to move to the cloud but may not fully leverage the benefits of serverless, such as scalability and cost optimization. For example, a simple web application might be rehosted on a serverless platform using containers.
- Replatforming: Replatforming involves making some modifications to the application to run on a serverless platform. This might include changing the underlying operating system or database. This approach offers more opportunities for optimization than lift-and-shift, but it requires more effort. An example would be migrating a database to a serverless database service.
- Refactoring: Refactoring involves rewriting portions of the application to take advantage of serverless features. This can involve breaking down the monolithic application into smaller, independent functions or services. This approach maximizes the benefits of serverless but is the most time-consuming and complex. The strangler fig pattern is a common refactoring technique.
- Strangler Fig Pattern: The strangler fig pattern is a gradual approach to migrating a monolithic application. It involves wrapping parts of the monolithic application with serverless functions, allowing the new serverless components to coexist with the existing monolith. Over time, more functionality is migrated to serverless, and the monolith is “strangled” until it is completely replaced.
- Implementation: The implementation involves identifying a small piece of functionality within the monolith to migrate.
This could be a specific API endpoint or a background process. A new serverless function is created to handle the functionality, and the monolith is updated to call the new function instead of handling the functionality itself.
- Benefits: The benefits include reduced risk, incremental deployments, and the ability to iterate and test the new serverless components before replacing the entire monolith. This approach allows teams to gain experience with serverless technologies while minimizing disruption to the business.
- Challenges: The challenges include the need to manage communication between the monolith and the serverless functions, as well as potential performance issues if the communication is not optimized.
- Implementation: The implementation involves identifying a small piece of functionality within the monolith to migrate.
- Re-architecting: Re-architecting involves completely redesigning the application for a serverless architecture. This is the most radical approach and involves building a new application from scratch. This approach offers the greatest potential for optimization but is the most expensive and time-consuming.
Risk Assessment Framework
A risk assessment framework is essential for identifying, evaluating, and mitigating potential risks associated with a serverless migration project. This framework should be implemented throughout the entire migration process.
- Risk Identification: Identify potential risks associated with the migration. These risks can be technical, organizational, or financial. Examples include:
- Technical Risks: Performance issues, scalability limitations, vendor lock-in, integration challenges, and security vulnerabilities.
- Organizational Risks: Lack of serverless expertise, resistance to change, and communication issues.
- Financial Risks: Unexpected costs, budget overruns, and inaccurate cost estimations.
- Risk Assessment: Assess the likelihood and impact of each identified risk. This can be done using a risk matrix, which plots the likelihood of a risk occurring against its potential impact. Risks are then categorized based on their severity.
- Risk Mitigation: Develop mitigation strategies for each identified risk. These strategies might include:
- Technical Mitigation: Using performance testing, choosing cloud-agnostic solutions, implementing robust security measures, and creating detailed integration plans.
- Organizational Mitigation: Providing training, fostering collaboration, and establishing clear communication channels.
- Financial Mitigation: Creating detailed cost estimations, setting up cost monitoring tools, and implementing cost optimization strategies.
- Risk Monitoring and Control: Continuously monitor the risks throughout the migration process. Track the effectiveness of the mitigation strategies and adjust them as needed. Regularly review the risk assessment framework to ensure it remains relevant and up-to-date. Implement automated alerts and dashboards to proactively identify and address potential issues.
- Documentation: Maintain detailed documentation of the risk assessment process, including the identified risks, their assessments, mitigation strategies, and monitoring results. This documentation serves as a valuable resource for future serverless migration projects.
Decomposing the Monolith
Decomposing a monolithic application is a critical step in migrating to a serverless architecture. This process involves identifying and extracting independent functionalities within the monolith, transforming them into self-contained services. The goal is to break down the large, complex application into smaller, more manageable units, each responsible for a specific set of tasks. This modularity facilitates independent development, deployment, and scaling, which are key advantages of a serverless environment.
Identifying and Extracting Independent Functionalities
Identifying independent functionalities within a monolithic application requires a thorough understanding of its codebase and business logic. Several methods can be employed to achieve this decomposition.
- Analyzing Code Dependencies: Examine the code to understand how different parts of the application interact. Tools like dependency graphs can visually represent these relationships, highlighting areas with high coupling (dependencies) and areas with lower coupling, which are potential candidates for extraction. Analyze class diagrams, package structures, and module dependencies to identify cohesive units of functionality. For example, if a section of code consistently handles user authentication and authorization, it is a strong candidate for extraction as a separate service.
- Business Domain Analysis: Understand the core business processes the application supports. Identify distinct business capabilities, such as order processing, product catalog management, or user management. Each capability can potentially map to a separate service. Domain-Driven Design (DDD) principles can be applied to identify bounded contexts, which represent specific areas of the business and can serve as service boundaries. For example, a large e-commerce application might have distinct bounded contexts for “Catalog,” “Orders,” and “Payments.”
- Profiling and Performance Analysis: Use profiling tools to identify performance bottlenecks within the monolith. Analyze resource usage, such as CPU and memory consumption, for different parts of the application. Identify the most resource-intensive functionalities. If a specific functionality consistently consumes a significant portion of resources, it may be a good candidate for independent scaling as a serverless function.
- Use Case Analysis: Review the application’s use cases to identify distinct user journeys and functionalities. Map each use case to the underlying code and identify areas that handle specific user interactions. Functionalities that support a specific use case, such as submitting an order or resetting a password, can often be extracted as independent services.
- Team Structure and Expertise: Consider the existing team structure and expertise. Align service boundaries with team responsibilities to facilitate independent development and ownership. Teams that are responsible for a specific area of functionality within the monolith can be assigned to own and maintain the corresponding serverless service.
Defining Service Boundaries
Defining service boundaries is crucial for ensuring that the decomposed services are loosely coupled and maintainable. A well-defined service boundary encapsulates a specific business capability, exposing a well-defined API for interaction.
- Cohesion: A service should be highly cohesive, meaning that all of its components should be related and work together to achieve a specific goal. A service should ideally have a single responsibility. For example, a “User Management” service would handle user registration, login, profile updates, and password resets.
- Loose Coupling: Services should be loosely coupled, meaning they should have minimal dependencies on other services. Changes in one service should not require changes in other services. Communication between services should primarily occur through APIs and asynchronous messaging, such as message queues.
- Autonomy: Each service should be autonomous, meaning it can be developed, deployed, and scaled independently of other services. This allows for faster development cycles and easier scaling.
- API Design: Define clear and consistent APIs for each service. APIs should be well-documented and follow standard protocols, such as REST or gRPC. Consider using API gateways to manage and secure access to the services.
- Data Ownership: Each service should own its data. Avoid sharing data directly between services. Services should interact with each other through APIs, and each service should be responsible for its own data storage and management.
Visual Representation of the Decomposition Process
The decomposition process can be visualized as a series of transformations, starting with the monolithic application and ending with a collection of independent serverless services. The following diagram illustrates the process:
Monolithic Application
|
Decomposition Process:
-Analysis of Code Dependencies, Business Domain, Performance, Use Cases, and Team Structure
-Identification of Independent Functionalities
-Definition of Service Boundaries (Cohesion, Loose Coupling, Autonomy, API Design, Data Ownership)
|
Extracted Services
-User Authentication Service
-Product Catalog Service
-Order Processing Service
-Payment Processing Service
-… other independent services …
|
Serverless Deployment (Each service deployed as a collection of serverless functions, APIs, and data stores)
The diagram depicts the monolith being dissected into smaller, specialized services. The decomposition process involves analyzing the monolith to identify independent functionalities. The process is followed by defining the boundaries of each service, based on principles such as cohesion, loose coupling, and autonomy. Finally, each extracted service is deployed as a collection of serverless components, leveraging the scalability and cost-efficiency of a serverless environment.
This transformation represents a significant shift from a tightly coupled monolithic application to a more flexible and scalable architecture.
Selecting Serverless Technologies
Choosing the right serverless technologies is critical for a successful migration. The selection process requires careful consideration of various factors, including application requirements, vendor-specific features, cost implications, and operational complexities. This section provides guidance on selecting appropriate serverless technologies for different application components, along with a comparison of major cloud providers.
Serverless Provider Comparison
The choice of serverless provider significantly impacts the architecture, performance, and cost of the migrated application. Several providers, including AWS, Azure, and Google Cloud, offer a comprehensive suite of serverless services. Understanding the strengths and weaknesses of each platform is essential for making an informed decision. The following table compares key features across these providers:
| Feature | AWS | Azure | Google Cloud |
|---|---|---|---|
| Compute (Functions) | AWS Lambda | Azure Functions | Cloud Functions |
| API Gateway | API Gateway | API Management / Azure Functions HTTP Triggers | Cloud Endpoints / API Gateway |
| Database (Serverless) | DynamoDB, Aurora Serverless | Cosmos DB, SQL Serverless | Cloud Firestore, Cloud SQL (with auto-scaling) |
| Object Storage | S3 | Azure Blob Storage | Cloud Storage |
| Event Triggering | EventBridge, SQS, SNS | Event Grid, Service Bus, Event Hubs | Cloud Pub/Sub, Cloud Storage Triggers |
| Container Support | Lambda (Container Images) | Azure Container Apps | Cloud Run |
| Monitoring & Logging | CloudWatch | Application Insights, Log Analytics | Cloud Logging, Cloud Monitoring |
| Pricing Model | Pay-per-use (requests and duration) | Pay-per-use (executions and resources) | Pay-per-use (executions and resources) |
Database Selection Considerations
The selection of a database is crucial in serverless architectures. Serverless databases offer automatic scaling, pay-per-use pricing, and simplified management, making them well-suited for serverless applications. Several factors influence the choice of database, including data structure, read/write patterns, and scalability requirements.
- Data Structure: Consider the data model of the application. Relational databases are suitable for structured data with complex relationships, while NoSQL databases are often preferred for flexible schemas and high-volume data.
- Read/Write Patterns: Analyze the application’s read and write patterns. High read-heavy workloads might benefit from databases optimized for read performance, while write-intensive applications require databases that handle high write throughput.
- Scalability: Evaluate the expected growth of the application. Serverless databases automatically scale based on demand, providing elasticity. Ensure the chosen database can handle the anticipated load.
- Cost: Compare the pricing models of different serverless databases. Consider the cost per request, storage costs, and the impact of scaling on the overall budget.
- Consistency Requirements: Determine the consistency requirements of the data. Some databases offer strong consistency, while others prioritize availability and eventual consistency. Choose a database that aligns with the application’s consistency needs.
API Gateway Selection
API Gateways play a crucial role in serverless architectures by providing a single entry point for API calls, managing authentication, authorization, and traffic control. The choice of an API Gateway depends on the application’s API design, security requirements, and performance needs.
- API Design: Select an API Gateway that supports the desired API design (e.g., REST, GraphQL). The gateway should be able to handle the necessary routing, transformation, and validation.
- Security: Ensure the API Gateway provides robust security features, including authentication, authorization, and protection against common attacks (e.g., DDoS).
- Performance: Consider the performance characteristics of the API Gateway, including latency and throughput. The gateway should be able to handle the expected traffic volume.
- Monitoring and Logging: Choose an API Gateway that provides comprehensive monitoring and logging capabilities. This allows for tracking API usage, identifying performance bottlenecks, and troubleshooting issues.
- Integration with Serverless Functions: The API Gateway should seamlessly integrate with the chosen serverless function platform (e.g., AWS Lambda, Azure Functions, Google Cloud Functions).
Other Service Considerations
Beyond compute, databases, and API gateways, several other services are crucial for a serverless application. These services enhance functionality, improve performance, and provide essential capabilities.
- Object Storage: Object storage services (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage) are used for storing and serving static content, such as images, videos, and documents.
- Message Queues: Message queues (e.g., AWS SQS, Azure Service Bus, Google Cloud Pub/Sub) enable asynchronous communication between application components, improving scalability and resilience.
- Event Triggers: Event trigger services (e.g., AWS EventBridge, Azure Event Grid, Google Cloud Storage Triggers) allow functions to be triggered by events from various sources, such as database changes or file uploads.
- Caching: Caching services (e.g., AWS ElastiCache, Azure Cache for Redis, Google Cloud Memorystore) can improve performance by storing frequently accessed data in memory.
- Monitoring and Logging: Comprehensive monitoring and logging tools (e.g., AWS CloudWatch, Azure Application Insights, Google Cloud Logging) are essential for tracking application performance, identifying errors, and troubleshooting issues. These tools provide insights into function execution, API calls, and resource utilization.
Implementing Serverless Functions
The successful migration of a monolithic application to a serverless architecture hinges on the effective implementation of serverless functions. This involves not only the creation and deployment of these functions but also the adherence to best practices in design, organization, and error handling to ensure scalability, maintainability, and resilience. Serverless functions, at their core, are event-triggered units of execution, and their implementation demands a shift in perspective from traditional application development.
Creating and Deploying Serverless Functions
The creation and deployment of serverless functions are fundamental steps in the migration process. The process generally involves writing code, packaging it, and configuring the function within a serverless platform. This section Artikels the typical steps involved.
- Code Development: The first step involves writing the function’s code. This code typically performs a specific task, such as processing data, responding to an API request, or interacting with a database. The choice of programming language depends on the platform’s support and the developer’s preference. Popular choices include JavaScript (Node.js), Python, Java, Go, and C#.
- Packaging the Code: The code is then packaged along with any necessary dependencies. The method of packaging varies depending on the platform. Some platforms, like AWS Lambda, allow you to upload a zip file containing the code and dependencies. Others, like Google Cloud Functions, might use container images or other packaging formats.
- Configuration and Deployment: The packaged code is then deployed to the serverless platform. This involves configuring the function with details such as the memory allocation, execution timeout, trigger (e.g., HTTP request, event from a message queue), and any environment variables required. The deployment process often uses a command-line interface (CLI) or a web-based console provided by the platform. Tools like the Serverless Framework and AWS SAM (Serverless Application Model) can automate and streamline this process.
- Testing and Monitoring: After deployment, thorough testing is crucial. This involves testing the function’s functionality, performance, and error handling. Serverless platforms provide monitoring tools to track metrics like invocation count, execution time, and error rates. These metrics are essential for identifying performance bottlenecks and potential issues.
Best Practices for Function Design
Designing serverless functions effectively is critical for maximizing their benefits. Good design practices lead to more efficient, scalable, and maintainable functions.
- Single Responsibility Principle: Each function should have a single, well-defined responsibility. This principle promotes modularity and reusability. A function should focus on performing one specific task, such as processing a specific type of event or transforming data.
- Idempotency: Functions should be idempotent, meaning that running them multiple times with the same input produces the same result. This is particularly important for functions that handle events or process data. Idempotency helps to prevent unintended side effects from duplicate executions.
- Statelessness: Functions should be stateless, meaning they do not store any state between invocations. This allows the platform to scale functions horizontally by running multiple instances concurrently. If state is required, it should be stored externally, such as in a database or a cache.
- Code Organization: Well-organized code is essential for maintainability. This includes using clear and consistent naming conventions, breaking down complex logic into smaller, reusable functions, and using appropriate comments. Using a code structure appropriate for the programming language is also beneficial.
- Error Handling: Robust error handling is crucial. Functions should gracefully handle potential errors, such as invalid input, network issues, or database failures. This includes using try-catch blocks, logging errors, and returning appropriate error responses to the caller. The error handling should also include strategies for retrying failed operations, implementing circuit breakers to prevent cascading failures, and handling timeouts.
- Logging and Monitoring: Implement comprehensive logging and monitoring to track function behavior. Log important events, errors, and performance metrics. Utilize the monitoring tools provided by the serverless platform to track invocation count, execution time, and error rates. This data is essential for identifying and resolving issues.
Code Snippets in Different Programming Languages
The following code snippets illustrate the implementation of simple serverless functions in different programming languages, demonstrating the core concepts. These are illustrative examples; real-world functions would be more complex.
- Python (using AWS Lambda): This example demonstrates a simple Python function that takes a name as input and returns a greeting.
“`python
import jsondef lambda_handler(event, context):
name = event.get(‘name’, ‘World’)
greeting = f”Hello, name!”
return
‘statusCode’: 200,
‘body’: json.dumps(‘message’: greeting)“`
- Node.js (using AWS Lambda): This example showcases a Node.js function that retrieves a value from an environment variable.
“`javascript
exports.handler = async (event) =>
const value = process.env.MY_VARIABLE;
const response =
statusCode: 200,
body: JSON.stringify( message: `The value is: $value` ),
;
return response;
;
“` - Java (using AWS Lambda): This Java function demonstrates a simple “Hello, World!” example.
“`java
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;public class HelloHandler implements RequestHandler
“`
- Go (using AWS Lambda): A simple Go function to return a greeting.
“`go
package mainimport (
“fmt”
“github.com/aws/aws-lambda-go/lambda”
)type Request struct
Name string `json:”name”`func HandleRequest(req Request) (string, error)
if req.Name == “”
return “Hello, World!”, nilreturn fmt.Sprintf(“Hello, %s!”, req.Name), nil
func main()
lambda.Start(HandleRequest)“`
API Gateway and Event-Driven Architecture
API Gateways and event-driven architectures are crucial components in successfully migrating a monolithic application to a serverless architecture. They provide the necessary infrastructure for exposing serverless functions to the outside world and enabling communication between different serverless services, respectively. This section delves into the practical aspects of using API Gateways and adopting an event-driven approach in a serverless environment.
API Gateway Configuration for Serverless Functions
API Gateways act as a central point of entry for all API requests, handling tasks such as authentication, authorization, request routing, and rate limiting. Configuring an API Gateway correctly is vital for ensuring the smooth operation and security of serverless functions.The following steps are typically involved in configuring an API Gateway:
- Defining API Endpoints: API Gateways allow the creation of endpoints, each corresponding to a specific serverless function. For instance, a function handling user creation might be mapped to an endpoint like `/users` with a `POST` method. The API Gateway routes incoming requests to the appropriate function based on the defined endpoint and HTTP method.
- Method Integration: Method integration links the API Gateway’s defined endpoints and methods to the backend serverless functions. This involves specifying the function’s ARN (Amazon Resource Name) or other identifier that the API Gateway uses to invoke the function. For example, an endpoint `/products/productId` with a `GET` method might be integrated with a serverless function named `getProductDetails`.
- Request Transformation: API Gateways often support request transformation, allowing modification of the incoming request before it reaches the serverless function. This is useful for tasks like converting data formats, adding headers, or filtering specific data. Consider a scenario where the client sends data in XML, but the serverless function expects JSON. The API Gateway can transform the XML request to JSON before invoking the function.
- Response Transformation: Similar to request transformation, response transformation allows the API Gateway to modify the response from the serverless function before returning it to the client. This might involve formatting the response, adding headers, or masking sensitive information.
- Authentication and Authorization: API Gateways provide mechanisms for securing APIs. This can involve using API keys, OAuth, or other authentication methods to verify the identity of the client. Authorization policies then control what resources the authenticated client can access. For example, an API Gateway could require an API key for accessing a protected resource, preventing unauthorized access.
- Rate Limiting and Throttling: To protect serverless functions from being overwhelmed, API Gateways can implement rate limiting and throttling. This restricts the number of requests a client can make within a specific time frame, preventing abuse and ensuring service availability.
- Monitoring and Logging: API Gateways provide comprehensive monitoring and logging capabilities. This allows for tracking API usage, identifying performance bottlenecks, and troubleshooting issues. Metrics like request latency, error rates, and the number of requests per second can be monitored to assess the health of the API.
Here is an example of how to configure an API Gateway to expose a serverless function using AWS API Gateway. This example uses the AWS CloudFormation template format:“`yamlResources: MyLambdaFunction: Type: AWS::Lambda::Function Properties: FunctionName: MyFunction Handler: index.handler Runtime: nodejs18.x Code: ZipFile: | exports.handler = async (event) => const response = statusCode: 200, body: JSON.stringify(‘Hello from Lambda!’), ; return response; ; Role: !GetAtt LambdaExecutionRole.Arn LambdaExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: ‘2012-10-17’ Statement:
Effect
Allow Principal: Service: lambda.amazonaws.com Action: sts:AssumeRole Policies:
PolicyName
root PolicyDocument: Version: ‘2012-10-17’ Statement:
Effect
Allow Action:
logs
CreateLogGroup
logs
CreateLogStream
logs
PutLogEvents Resource: ‘arn:aws:logs:*:*:*’ MyApi: Type: AWS::ApiGateway::RestApi Properties: Name: MyApiGateway MyResource: Type: AWS::ApiGateway::Resource Properties: ParentId: !GetAtt MyApi.RootResourceId PathPart: hello RestApiId: !Ref MyApi MyMethod: Type: AWS::ApiGateway::Method Properties: HttpMethod: GET ResourceId: !Ref MyResource RestApiId: !Ref MyApi AuthorizationType: NONE Integration: Type: AWS_PROXY IntegrationHttpMethod: POST Uri: !Sub “arn:aws:apigateway:$AWS::Region:lambda:path/2015-03-31/functions/$MyLambdaFunction.Arn/invocations” MyDeployment: Type: AWS::ApiGateway::Deployment DependsOn: MyMethod Properties: RestApiId: !Ref MyApi StageName: prod MyPermission: Type: AWS::Lambda::Permission Properties: FunctionName: !Ref MyLambdaFunction Action: lambda:InvokeFunction Principal: apigateway.amazonaws.com SourceArn: !Sub “arn:aws:execute-api:$AWS::Region:$AWS::AccountId:$MyApi/*/*/*”“`This CloudFormation template defines a simple API Gateway that exposes a “Hello World” Lambda function.
It creates the Lambda function, defines the API Gateway, creates a resource `/hello`, and integrates the GET method of the resource with the Lambda function. The `MyDeployment` resource deploys the API, making it accessible. The `MyPermission` resource grants the API Gateway permission to invoke the Lambda function.
Event-Driven Architecture in Serverless Applications
Event-driven architecture (EDA) is a software design paradigm where applications react to events. In a serverless context, this means functions are triggered in response to events, such as a file being uploaded to an S3 bucket, a message being published to a queue, or a database record being updated. EDA offers significant benefits for serverless applications, including loose coupling, scalability, and resilience.The principles of event-driven architecture are:
- Events: Events are significant occurrences in the system. They represent a change of state or an action performed. Events are immutable and contain relevant information about what happened. Examples include “Order Created,” “Payment Received,” or “File Uploaded.”
- Event Producers: Event producers are services or components that generate events. They are responsible for detecting events and publishing them to an event bus or message queue. They do not need to know about the consumers of the events.
- Event Consumers: Event consumers are services or components that subscribe to and react to events. They are decoupled from the event producers and can independently process events. Multiple consumers can subscribe to the same event, allowing for parallel processing and increased scalability.
- Event Bus/Message Queue: The event bus or message queue acts as a central intermediary for event communication. It receives events from producers and delivers them to the appropriate consumers. It provides a mechanism for asynchronous communication, decoupling producers and consumers. Examples include Amazon SQS, Amazon SNS, and Apache Kafka.
- Asynchronous Communication: EDA emphasizes asynchronous communication. Producers and consumers do not communicate directly. Instead, producers publish events, and consumers react to those events asynchronously. This improves system responsiveness and scalability.
Consider an e-commerce application. An event-driven architecture can be used to handle order processing:
- Event Producer: The “Order Service” is the event producer. When a customer places an order, the Order Service publishes an “Order Created” event. This event might contain details such as the order ID, customer ID, and items ordered.
- Event Bus: Amazon SNS or Amazon SQS serves as the event bus. The Order Service publishes the “Order Created” event to the bus.
- Event Consumers:
- “Payment Service”: Subscribes to the “Order Created” event and processes the payment.
- “Inventory Service”: Subscribes to the “Order Created” event and updates the inventory levels.
- “Shipping Service”: Subscribes to the “Order Created” event and prepares the order for shipment.
This architecture allows the services to operate independently. The Order Service does not need to know how the payment, inventory, or shipping services work. The payment, inventory, and shipping services can scale independently based on their specific workloads. If the payment service fails, it does not prevent the inventory or shipping services from functioning.
API Gateway Configuration for Event-Driven Interactions
API Gateways can be integrated with event-driven architectures to provide an entry point for external systems to trigger events within the serverless application. This is especially useful for initiating workflows or processes based on external actions.Here’s how API Gateways can be configured for event-driven interactions:
- Triggering Events via API Calls: An API Gateway can be configured to receive an API request and then publish an event to an event bus (e.g., SNS, SQS). The API Gateway acts as a “producer” in this scenario. For example, an API endpoint `/orders` with a `POST` method could be used to create a new order. The API Gateway would then publish an “OrderCreated” event to an SNS topic.
- Integrating with Event Buses: The API Gateway’s integration settings can be configured to directly interact with the event bus. This usually involves specifying the event bus’s endpoint (e.g., the SNS topic ARN) and the message payload to be sent. The API Gateway handles the necessary authentication and authorization to publish the event.
- Request Transformation for Event Payloads: The API Gateway can transform the incoming API request into a format suitable for the event bus. This involves extracting relevant data from the request and constructing the event payload. For instance, the API Gateway could extract order details from the request body and format them into a JSON payload for the “OrderCreated” event.
- Error Handling and Retry Mechanisms: API Gateways can be configured to handle errors that occur when publishing events. This might involve logging errors, retrying the event publishing, or sending error notifications. This ensures that events are reliably published to the event bus.
- Security Considerations: When using API Gateways to trigger events, security is crucial. API Gateways should use authentication and authorization mechanisms (e.g., API keys, OAuth) to control who can trigger events. The event bus itself should also be secured to prevent unauthorized access.
An example scenario: A mobile application needs to submit a customer support ticket. The mobile app makes a POST request to an API Gateway endpoint `/tickets`. The API Gateway then publishes a `TicketCreated` event to an SNS topic. A Lambda function, subscribed to the SNS topic, processes the event and creates a ticket in a helpdesk system.Here is an example of how to configure an API Gateway to publish a message to an SNS topic using AWS CloudFormation:“`yamlResources: MyApi: Type: AWS::ApiGateway::RestApi Properties: Name: MyEventDrivenApi MyResource: Type: AWS::ApiGateway::Resource Properties: ParentId: !GetAtt MyApi.RootResourceId PathPart: tickets RestApiId: !Ref MyApi MyMethod: Type: AWS::ApiGateway::Method Properties: HttpMethod: POST ResourceId: !Ref MyResource RestApiId: !Ref MyApi AuthorizationType: NONE Integration: Type: AWS_PROXY IntegrationHttpMethod: POST Uri: !Sub “arn:aws:apigateway:$AWS::Region:sns:path//$SNSTopic.TopicName” PassthroughBehavior: WHEN_NO_MATCH RequestTemplates: application/json: | “message”: “$input.json(‘$’)” MyDeployment: Type: AWS::ApiGateway::Deployment DependsOn: MyMethod Properties: RestApiId: !Ref MyApi StageName: prod SNSTopic: Type: AWS::SNS::Topic Properties: TopicName: MyTicketTopic SNSPermission: Type: AWS::IAM::Policy Properties: PolicyName: SNSPermission PolicyDocument: Version: ‘2012-10-17’ Statement:
Effect
Allow Action: sns:Publish Resource: !Ref SNSTopic Roles:
!Ref ApiGatewayRole
ApiGatewayRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: ‘2012-10-17’ Statement:
Effect
Allow Principal: Service: apigateway.amazonaws.com Action: sts:AssumeRole Policies:
PolicyName
root PolicyDocument: Version: ‘2012-10-17’ Statement:
Effect
Allow Action:
sns
Publish Resource: !GetAtt SNSTopic.Arn“`This CloudFormation template defines an API Gateway that publishes messages to an SNS topic. The `MyApi` resource creates the API Gateway. The `MyResource` resource creates the `/tickets` resource. The `MyMethod` resource defines the POST method for the `/tickets` resource, integrating it with SNS.
The `Integration` property specifies that the API Gateway should use the SNS service and provides the ARN of the SNS topic. The `RequestTemplates` property transforms the incoming request body into a format suitable for the SNS message. The `SNSTopic` resource creates the SNS topic. The `SNSPermission` resource grants the API Gateway the necessary permissions to publish to the SNS topic, using an IAM role.
The `ApiGatewayRole` resource creates an IAM role that the API Gateway assumes to publish to the SNS topic.
Testing and Monitoring in a Serverless Environment
Migrating a monolithic application to serverless necessitates a paradigm shift in testing and monitoring strategies. The distributed nature of serverless architectures introduces complexities that require specialized approaches to ensure application reliability, performance, and cost-effectiveness. Robust testing and proactive monitoring are critical for the success of a serverless migration.
Testing Serverless Functions and Applications
Testing serverless applications demands a multifaceted approach due to the decoupled nature of functions and the reliance on external services. Testing strategies should encompass unit, integration, and end-to-end tests, adapted to the serverless environment.
- Unit Testing: Unit tests are fundamental for verifying the correctness of individual serverless functions. They isolate a function and test its behavior in response to various inputs. These tests typically involve mocking dependencies and validating the output against expected values. For example, a function that processes a user registration might be tested with valid and invalid email addresses, password lengths, and username formats.
Mocking database calls and API interactions allows for isolated testing of the function’s logic.
- Integration Testing: Integration tests assess the interaction between different serverless functions and with external services, such as databases, APIs, and message queues. These tests simulate real-world scenarios where multiple components work together. For instance, testing the interaction between a function that receives a file upload, another function that processes the file, and a third function that updates a database entry requires integration tests.
Integration tests should also validate the correct handling of errors and edge cases across multiple components.
- End-to-End (E2E) Testing: End-to-end tests simulate the entire user workflow, from the initial request through all backend processes and responses. These tests ensure that the application functions as a whole and that all components are working correctly together. E2E tests often involve deploying the application to a test environment and simulating user interactions using tools like Selenium or Cypress. These tests should cover critical user journeys and validate the overall application behavior, including performance and responsiveness.
- Testing Frameworks and Tools: Several frameworks and tools are specifically designed to simplify serverless testing. Frameworks like Serverless Framework, AWS SAM (Serverless Application Model), and frameworks such as Jest or Mocha, along with libraries like Supertest or Axios, provide features for local function execution, mocking, and automated testing. These tools allow developers to simulate the serverless environment locally and automate the testing process, making it easier to identify and fix issues.
- Testing Event-Driven Architectures: Serverless applications frequently leverage event-driven architectures. Testing event-driven systems requires simulating the events that trigger function invocations. This involves publishing test events to services like Amazon SQS, Amazon SNS, or Kinesis and verifying that the functions react as expected. Testing tools should allow the simulation of various event payloads and the verification of function outputs, including database updates and notifications.
Monitoring and Logging Best Practices for Serverless Environments
Effective monitoring and logging are essential for understanding the behavior of a serverless application, identifying performance bottlenecks, and troubleshooting issues. Serverless environments provide a wealth of data, but this data needs to be collected, analyzed, and acted upon effectively.
- Centralized Logging: Centralized logging involves aggregating logs from all serverless functions and related services into a single location. This allows for easier analysis and correlation of events across the entire application. Services like AWS CloudWatch Logs, Google Cloud Logging, and Azure Monitor provide centralized logging capabilities. Logs should include timestamps, function names, request IDs, and relevant contextual information for effective debugging.
- Structured Logging: Structured logging involves formatting log messages in a standardized way, such as JSON. This makes it easier to parse and analyze logs programmatically. Structured logs allow for easier searching, filtering, and aggregation of log data. For example, each log entry can include fields for the log level (INFO, WARNING, ERROR), the function name, the request ID, and the message content.
- Monitoring Metrics: Monitoring metrics involve tracking key performance indicators (KPIs) such as function invocation count, execution time, error rates, and memory usage. These metrics provide insights into the performance and health of the application. Cloud providers offer built-in monitoring services, such as AWS CloudWatch, that automatically collect and display these metrics.
- Alerting and Notifications: Setting up alerts based on predefined thresholds for critical metrics is crucial. Alerts notify developers of potential issues, allowing for proactive intervention. For example, an alert can be triggered if the error rate for a function exceeds a certain percentage or if the execution time consistently exceeds a defined limit.
- Distributed Tracing: Distributed tracing involves tracking requests as they flow through multiple serverless functions and services. This provides a detailed view of the request’s journey, including the time spent in each function and service. Tools like AWS X-Ray, Jaeger, and Zipkin provide distributed tracing capabilities. This helps identify performance bottlenecks and troubleshoot issues in complex serverless applications.
- Cost Monitoring: Serverless applications often have a pay-per-use pricing model. Monitoring costs is essential to ensure that the application remains cost-effective. Monitoring tools can track the cost of function invocations, data transfer, and other service usage. Setting up cost alerts can prevent unexpected expenses.
Debugging Serverless Applications
Debugging serverless applications requires a different approach than debugging monolithic applications. The distributed nature of serverless architectures necessitates the use of specialized debugging techniques.
- Log Analysis: The first step in debugging a serverless application is often analyzing the logs. Logs provide valuable information about the execution of functions, including errors, warnings, and informational messages. Examining the logs can help identify the root cause of an issue.
- Request Tracing: Request tracing, using tools like AWS X-Ray, provides a detailed view of a request’s journey through the application. This allows developers to pinpoint the exact function or service that is causing an issue. Tracing can help identify performance bottlenecks and errors that occur across multiple components.
- Local Function Invocation: Many serverless frameworks and tools allow for local function invocation. This allows developers to run functions locally and debug them using a local debugger. This can be particularly useful for testing and debugging individual functions in isolation.
- Remote Debugging: Cloud providers often provide remote debugging capabilities. This allows developers to connect to a running function in the cloud and step through the code, inspect variables, and set breakpoints. This is useful for debugging issues that are difficult to reproduce locally.
- Error Handling and Reporting: Implementing robust error handling and reporting is crucial for debugging serverless applications. Functions should gracefully handle errors and provide detailed error messages, including stack traces and relevant contextual information. Centralized error reporting tools can aggregate errors and provide insights into the most frequent issues.
- Version Control and Rollbacks: Using version control systems, such as Git, is essential for managing the code for serverless functions. This allows developers to track changes, revert to previous versions, and collaborate effectively. Deploying new versions of functions frequently and quickly, alongside the possibility of quick rollbacks, reduces the impact of any introduced errors.
Deployment and CI/CD Pipelines

Automating the deployment process and establishing robust Continuous Integration and Continuous Deployment (CI/CD) pipelines are crucial for the efficient and reliable operation of serverless applications. These pipelines streamline the build, testing, and deployment phases, allowing for faster release cycles, reduced human error, and improved application stability. A well-designed CI/CD pipeline is essential for managing the complexity of serverless architectures, where multiple functions and services interact.
Designing a CI/CD Pipeline for Serverless Deployments
The design of a CI/CD pipeline for serverless applications must account for the unique characteristics of this architecture, including the stateless nature of functions, the use of infrastructure-as-code, and the event-driven nature of many applications. The pipeline should encompass several key stages, each serving a specific purpose in the overall deployment process.
- Code Repository and Version Control: The process begins with a code repository, such as Git, to store the application’s source code, infrastructure definitions (e.g., Terraform, CloudFormation, Serverless Framework), and configuration files. Version control is essential for tracking changes, enabling rollbacks, and facilitating collaboration among developers.
- Build Stage: This stage typically involves compiling the code, packaging dependencies, and creating deployment artifacts. For serverless functions, this might involve bundling the function code with its dependencies. For example, if using Node.js, this stage could involve running `npm install` to install dependencies and bundling the code using a tool like Webpack.
- Testing Stage: Rigorous testing is critical. This stage should include unit tests to verify individual function logic, integration tests to ensure interactions between functions and external services, and end-to-end tests to validate the overall application functionality. Automated testing frameworks, such as Jest for JavaScript or JUnit for Java, are commonly used.
- Infrastructure Provisioning and Configuration: This step involves defining and provisioning the infrastructure required by the serverless application, such as API Gateways, databases, and event sources. Infrastructure-as-code (IaC) tools like Terraform, AWS CloudFormation, or the Serverless Framework are used to automate this process, ensuring consistency and repeatability.
- Deployment Stage: This is the stage where the built and tested code is deployed to the serverless platform (e.g., AWS Lambda, Azure Functions, Google Cloud Functions). The deployment process should be automated and repeatable, using tools like the Serverless Framework or platform-specific deployment mechanisms.
- Monitoring and Alerting: After deployment, comprehensive monitoring and alerting are essential to detect and respond to issues in production. This involves collecting metrics, logs, and traces, and setting up alerts to notify the development team of any anomalies or performance degradation. Monitoring tools like AWS CloudWatch, Azure Monitor, and Google Cloud Operations are commonly used.
Automating Deployments Using Tools
Automating deployments is essential for efficient and reliable serverless application management. Several tools are available to automate the deployment process, including Infrastructure-as-Code (IaC) tools and dedicated serverless deployment frameworks.
- Terraform: Terraform is a popular IaC tool that allows you to define and provision infrastructure resources across multiple cloud providers. It uses a declarative configuration language to describe the desired state of your infrastructure, and Terraform then automatically provisions and manages the resources to match that state. For serverless deployments, Terraform can be used to define and deploy resources such as API Gateways, Lambda functions, and databases.
For instance, a Terraform configuration might define an AWS Lambda function with its associated IAM role, API Gateway endpoint, and S3 bucket for code storage.
- Serverless Framework: The Serverless Framework is a dedicated framework designed specifically for building and deploying serverless applications. It simplifies the process of deploying and managing serverless functions and related resources. The Serverless Framework uses a YAML configuration file (serverless.yml) to define the application’s functions, events, and resources. For example, a `serverless.yml` file might define an AWS Lambda function triggered by an HTTP request through an API Gateway.
The framework handles the deployment, configuration, and management of these resources.
- AWS SAM (Serverless Application Model): AWS SAM is an open-source framework for building serverless applications on AWS. It provides a simplified way to define and deploy serverless applications using CloudFormation templates. SAM extends CloudFormation with a set of resources and properties specific to serverless applications, making it easier to define Lambda functions, API Gateways, and other related resources.
- Azure Functions Core Tools: For Azure, Azure Functions Core Tools provide a command-line interface (CLI) for developing, testing, and deploying Azure Functions. They can be integrated into CI/CD pipelines to automate the deployment process.
- Google Cloud Functions Deployment: Google Cloud Functions supports deployment through the Google Cloud SDK (gcloud CLI). The gcloud CLI allows you to deploy functions from your local machine or integrate them into CI/CD pipelines.
Deployment Strategies and Their Benefits
Various deployment strategies can be employed to minimize downtime, reduce risk, and enable easier rollbacks during serverless application updates. Each strategy offers different benefits, and the choice depends on the specific requirements of the application.
- Blue/Green Deployments: This strategy involves maintaining two identical environments: a “blue” environment (the current production environment) and a “green” environment (the new environment). When a new version of the application is ready, it is deployed to the green environment. After testing and validation, traffic is gradually switched from the blue environment to the green environment. This approach minimizes downtime and allows for easy rollback to the blue environment if issues arise.
- Canary Deployments: In a canary deployment, a small percentage of production traffic is routed to the new version of the application (the “canary”). This allows for real-world testing of the new version without affecting all users. If the canary deployment performs well, the traffic is gradually increased until all traffic is routed to the new version. This strategy minimizes risk and allows for early detection of issues.
- Rolling Deployments: This strategy involves updating the application in a rolling fashion, one instance or component at a time. This approach can minimize downtime, but it requires careful planning to ensure that the application remains functional during the update process.
- Immutable Deployments: This approach involves deploying a completely new version of the application, including all dependencies, each time an update is made. The old version is then retired. This strategy simplifies the deployment process and reduces the risk of configuration drift. It is particularly well-suited for serverless applications.
- Traffic Shifting: For serverless platforms, traffic shifting techniques allow for fine-grained control over how traffic is routed between different versions of a function. This can be used to implement blue/green or canary deployments by adjusting the traffic distribution. For example, in AWS Lambda, you can use aliases and weighted routing to control traffic flow.
Final Thoughts
In conclusion, migrating a monolithic application to a serverless environment is a transformative undertaking that necessitates careful planning, strategic execution, and a thorough understanding of both monolithic and serverless architectures. This comprehensive guide provides a structured framework for navigating this process, offering insights into the critical steps involved, from initial assessment and planning to deployment and ongoing management. By embracing the principles Artikeld herein, developers can successfully modernize their applications, unlocking the full potential of serverless computing and paving the way for a more agile, scalable, and cost-effective future.
Answers to Common Questions
What are the primary benefits of serverless migration?
The primary benefits include reduced operational overhead, automatic scaling, cost optimization (pay-per-use), increased agility, and improved developer productivity.
How do you determine if a monolithic application is suitable for serverless migration?
Assess the application’s complexity, the degree of coupling between modules, and the potential for independent scaling of functionalities. Applications with well-defined, independent features are better candidates.
What are the key challenges of migrating to serverless?
Challenges include managing distributed systems, debugging and monitoring serverless functions, vendor lock-in, and the need for a shift in development and operational practices.
What is the “strangler fig pattern” and how does it relate to serverless migration?
The “strangler fig pattern” involves gradually replacing parts of the monolith with serverless functions, allowing the new system to “strangle” the old one until it’s entirely replaced. This approach minimizes risk and downtime.
How can you ensure the security of serverless functions?
Implement robust security measures, including using least-privilege access, regularly updating dependencies, securing API gateways, and employing proper authentication and authorization mechanisms.