Data migration, the strategic movement of information from one system to another, presents a complex landscape of security considerations. The process, while crucial for technological advancement and operational efficiency, inherently introduces vulnerabilities that can compromise sensitive data. This guide delves into the multifaceted strategies required to navigate this landscape, ensuring data privacy remains paramount throughout the migration lifecycle.
The core of this exploration lies in a systematic approach. We will dissect the critical phases of data migration, from meticulous planning and preparation to secure data transfer, robust access control, and unwavering compliance with regulatory mandates. Furthermore, we will examine the technical underpinnings of data protection, including data masking, anonymization, and encryption techniques. Each element will be examined in detail, providing a robust framework for mitigating risks and safeguarding valuable information.
Planning and Preparation for Data Migration
Data migration, a critical undertaking in modern data management, necessitates meticulous planning and preparation to ensure data integrity, minimize downtime, and safeguard sensitive information. This initial phase establishes the foundation for a successful migration project, mitigating risks and defining the scope of the endeavor. Failure to adequately plan can lead to significant cost overruns, data loss, and reputational damage.
Risk Assessment and Scope Definition
A comprehensive risk assessment and a clearly defined scope are paramount to a successful data migration. This process proactively identifies potential threats and establishes the boundaries of the project, ensuring resources are allocated effectively and expectations are managed appropriately.
- Risk Assessment: This involves identifying potential risks associated with the migration process. These risks can be categorized into several areas, including:
- Data Loss: The possibility of losing data during the extraction, transformation, or loading (ETL) process. This could be due to hardware failures, software bugs, or human error. Mitigation strategies include implementing robust backup and recovery procedures, conducting thorough testing, and employing data validation techniques.
- Data Corruption: The risk of data being altered or damaged during migration, leading to inaccurate or unusable information. This can arise from incorrect data mapping, incompatible data formats, or inadequate data validation. Preventing this involves meticulous data mapping, rigorous data validation checks, and the use of data transformation tools.
- Downtime: The period during which systems are unavailable to users due to the migration process. Minimizing downtime is crucial for business continuity. Strategies include planning for phased migrations, utilizing parallel processing techniques, and optimizing the ETL process.
- Security Breaches: The potential for unauthorized access to sensitive data during migration. Security risks are addressed by implementing strong access controls, encrypting data in transit and at rest, and adhering to data privacy regulations.
- Compliance Violations: The risk of violating data privacy regulations, such as GDPR or CCPA, during the migration process. This involves ensuring compliance with relevant data privacy regulations. Adhering to data governance policies and seeking legal counsel where necessary can help ensure compliance.
- Scope Definition: Clearly defining the scope of the migration project is essential. This involves:
- Data Identification: Determining which data will be migrated. This involves identifying all relevant data sources and the specific data elements that need to be transferred.
- Target System Selection: Choosing the destination system for the migrated data. This requires evaluating different options based on factors such as functionality, scalability, and cost.
- Migration Timeline: Establishing a realistic timeline for the migration project, including milestones and deadlines.
- Resource Allocation: Identifying and allocating the necessary resources, including personnel, hardware, and software.
- Budget Planning: Estimating the costs associated with the migration project, including personnel costs, software licensing fees, and hardware expenses.
Data Migration Plan Checklist
Creating a comprehensive data migration plan involves documenting all aspects of the migration process. This plan serves as a roadmap, ensuring that the migration is executed efficiently and effectively. The following checklist provides a structured approach to developing a robust data migration plan.
- Project Goals and Objectives: Defining the overall goals of the migration project, such as improving data quality, reducing costs, or enhancing system performance.
- Data Inventory: Creating a detailed inventory of the data to be migrated, including data sources, data types, and data volumes.
- Data Mapping: Mapping the data elements from the source system to the target system. This process identifies how data will be transformed and transferred.
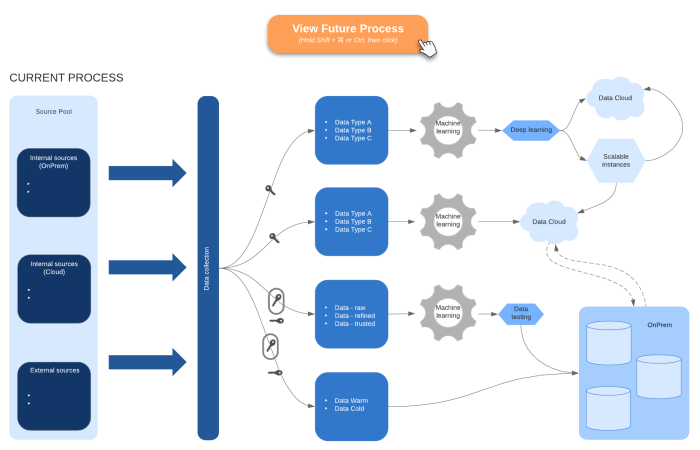
- Data Extraction, Transformation, and Loading (ETL) Strategy: Outlining the ETL process, including the tools and techniques to be used for data extraction, transformation, and loading.
For example, the ETL process might involve extracting data from a legacy database, transforming it to conform to the target system’s schema, and loading it into a new cloud-based data warehouse.
- Data Validation and Verification: Establishing a comprehensive data validation strategy to ensure the accuracy and completeness of the migrated data. This includes:
- Data Profiling: Analyzing the source data to understand its characteristics and identify potential data quality issues.
- Data Cleansing: Correcting and standardizing data to improve its quality.
- Data Transformation: Converting data from the source system’s format to the target system’s format.
- Data Validation Rules: Defining a set of rules to validate the data during the migration process. These rules can check for data completeness, accuracy, and consistency.
- Data Reconciliation: Comparing the data in the source and target systems to ensure that the data has been migrated correctly.
- Testing Strategy: Developing a testing strategy to validate the migration process. This includes:
- Unit Testing: Testing individual components of the migration process.
- Integration Testing: Testing the integration of different components.
- System Testing: Testing the entire migration process.
- User Acceptance Testing (UAT): Allowing users to test the migrated data and ensure that it meets their needs.
- Cutover Plan: Creating a detailed cutover plan that Artikels the steps involved in migrating the data to the target system. This includes:
- Data Freeze: Preventing any changes to the source data during the migration process.
- Data Migration: Executing the ETL process to migrate the data to the target system.
- System Switchover: Switching users to the target system.
- Post-Migration Activities: Performing post-migration activities, such as data validation and system stabilization.
- Rollback Plan: Developing a rollback plan in case of any issues during the migration process. This plan Artikels the steps to revert to the original system.
- Communication Plan: Establishing a communication plan to keep stakeholders informed about the migration progress.
- Training Plan: Developing a training plan to train users on the new system.
- Data Security and Privacy: Implementing measures to ensure data security and privacy during the migration process.
Data Governance Policies in Migration Projects
Data governance policies are essential for ensuring data quality, security, and compliance throughout a data migration project. These policies provide a framework for managing data assets, defining data ownership, and establishing data standards.
- Data Ownership and Accountability: Defining clear roles and responsibilities for data ownership and accountability. This includes identifying who is responsible for the quality, accuracy, and security of the data.
- Data Quality Standards: Establishing data quality standards to ensure that the migrated data meets the required level of accuracy, completeness, and consistency.
- Data Security Policies: Implementing data security policies to protect sensitive data during the migration process. This includes access controls, encryption, and data masking.
For instance, if migrating Personally Identifiable Information (PII), implementing data masking techniques can obscure sensitive data elements to prevent unauthorized access.
- Data Privacy Regulations: Ensuring compliance with data privacy regulations, such as GDPR and CCPA. This includes obtaining consent for data processing, providing data subject rights, and implementing data minimization techniques.
- Data Retention Policies: Defining data retention policies to determine how long data should be stored and when it should be archived or deleted.
- Data Cataloging and Metadata Management: Establishing a data catalog to document the data assets and their metadata. This includes defining data definitions, data lineage, and data quality metrics.
- Data Change Management: Implementing a data change management process to control changes to the data during and after the migration. This includes change request procedures, change impact assessments, and change approvals.
- Monitoring and Auditing: Establishing monitoring and auditing mechanisms to track data quality, security, and compliance. This includes data quality dashboards, security logs, and audit trails.
For example, a financial institution migrating customer data might implement strict access controls and regularly audit user access to ensure compliance with regulations like PCI DSS.
Data Inventory and Classification
A critical step in ensuring data privacy during migration involves a comprehensive understanding of the data landscape. This necessitates a meticulous process of identifying, classifying, and categorizing all data assets within an organization. The objective is to establish a clear and structured approach to data handling, enabling informed decisions regarding protection mechanisms, access controls, and compliance strategies throughout the migration process.
Accurate data inventory and classification are foundational for mitigating risks and upholding privacy regulations.
Process for Identifying and Classifying Sensitive Data
Establishing a robust process for identifying and classifying sensitive data requires a multi-faceted approach. This process should encompass several key steps, designed to systematically uncover and categorize all data assets.
- Define Data Sensitivity Criteria: This involves establishing clear and concise criteria for determining data sensitivity. These criteria should align with relevant regulatory requirements (e.g., GDPR, CCPA, HIPAA) and organizational policies. Data should be classified based on potential impact, which considers factors like:
- Confidentiality: The risk of unauthorized disclosure.
- Integrity: The risk of data alteration or destruction.
- Availability: The risk of data loss or unavailability.
For instance, data containing personally identifiable information (PII) such as social security numbers or medical records should be automatically classified as highly sensitive due to the significant potential for harm resulting from unauthorized access or disclosure.
- Data Discovery and Mapping: Employing automated data discovery tools and manual assessments to identify and locate all data repositories across the organization’s infrastructure, including databases, file servers, cloud storage, and applications. This phase should involve scanning various data sources to identify data elements that match the predefined sensitivity criteria. For example, a data discovery tool might scan a database and identify columns containing email addresses, phone numbers, or credit card numbers.
- Data Profiling and Analysis: Conducting data profiling to understand data characteristics, including data types, formats, and values. This involves analyzing data content to identify patterns and anomalies that could indicate sensitive information. Data profiling helps in accurately assessing the sensitivity of data. For example, data profiling can identify the frequency of specific values in a column to assess the likelihood of sensitive data.
- Data Classification and Tagging: Classifying data based on the defined sensitivity criteria and assigning appropriate tags or labels. This involves assigning a sensitivity level (e.g., public, internal, confidential, restricted) to each data asset or data element. Data classification can be automated using rules-based systems or machine learning algorithms, or it can be performed manually by data stewards. An example of automated classification is using a system to flag any document containing a credit card number as “Confidential”.
- Documentation and Reporting: Documenting the data inventory and classification results, including data sources, sensitivity levels, and associated metadata. This documentation serves as a central repository of information about the organization’s data assets and facilitates ongoing monitoring and management. Reporting should provide visibility into the data landscape, allowing for risk assessment and compliance tracking. For example, a data inventory report can include the location, sensitivity level, and owner of each data asset.
Methods for Categorizing Data Based on Sensitivity and Regulatory Requirements
Categorizing data requires a methodical approach, taking into account both the sensitivity of the data and the regulatory frameworks that apply. This categorization process provides a framework for implementing appropriate protection measures and ensuring compliance.
- Sensitivity Level Determination: This step involves assigning a sensitivity level to each data asset or data element based on the potential impact of a data breach or unauthorized access. Common sensitivity levels include:
- Public: Data that can be freely shared with the public.
- Internal: Data that is for internal use only and not for public disclosure.
- Confidential: Data that requires restricted access and should only be shared with authorized personnel.
- Restricted: Highly sensitive data that requires the highest level of protection and is subject to specific regulatory requirements.
For instance, a company’s internal policy documents would likely be classified as “Internal,” while financial records containing customer data would be classified as “Confidential” or “Restricted.”
- Regulatory Compliance Mapping: Identifying and mapping data assets to the relevant regulatory requirements. This involves determining which regulations apply to each data type and ensuring that appropriate controls are in place to meet those requirements.
For example:- GDPR: Applies to the processing of personal data of individuals within the European Union.
- CCPA: Applies to the collection, use, and sale of personal information of California residents.
- HIPAA: Applies to the protection of protected health information (PHI).
For instance, health records would need to be protected according to HIPAA regulations, requiring specific security measures like encryption and access controls.
- Data Minimization and Purpose Limitation: Implementing data minimization principles by collecting and retaining only the data necessary for a specific purpose. Furthermore, defining and limiting the purposes for which data can be processed. This approach reduces the overall risk associated with data handling. For example, an organization might only collect a customer’s name and email address if it’s essential for providing a service, and not collect additional unnecessary information.
- Data Governance Policies and Procedures: Establishing comprehensive data governance policies and procedures to manage data throughout its lifecycle. This includes defining data ownership, access controls, data retention policies, and incident response plans. These policies should be regularly reviewed and updated to ensure they remain effective and aligned with regulatory requirements. For example, data governance policies would define who has access to specific data sets and how data breaches should be handled.
Data Types and Protection Needs Table
The following table provides a structured overview of different data types and their respective protection needs. This table serves as a reference for implementing appropriate security measures and ensuring compliance with relevant regulations.
| Data Type | Description | Sensitivity Level | Regulatory Requirements | Protection Needs |
|---|---|---|---|---|
| Personally Identifiable Information (PII) | Information that can be used to identify an individual (e.g., name, address, email, phone number). | Confidential / Restricted | GDPR, CCPA, HIPAA (if health-related) | Encryption, access controls, data minimization, pseudonymization, data masking. |
| Financial Data | Bank account details, credit card numbers, transaction history. | Restricted | PCI DSS, GDPR, CCPA | Encryption, tokenization, strict access controls, regular security audits, data loss prevention (DLP). |
| Health Information | Medical records, diagnoses, treatment information. | Restricted | HIPAA, GDPR | Encryption, access controls, audit trails, business associate agreements, data breach notification procedures. |
| Intellectual Property (IP) | Trade secrets, patents, copyrights, proprietary designs. | Confidential / Restricted | Trade Secret Laws, Copyright Laws | Access controls, version control, data loss prevention, non-disclosure agreements (NDAs), watermarking. |
| Employee Data | Employee records, performance reviews, salary information. | Confidential | GDPR, CCPA | Access controls, data minimization, data retention policies, employee training, secure storage. |
| Customer Data | Customer purchase history, preferences, and interactions. | Confidential | GDPR, CCPA | Access controls, data minimization, data retention policies, encryption, data masking. |
Data Masking and Anonymization Techniques
Data masking and anonymization are crucial strategies for safeguarding sensitive information during data migration. These techniques transform data to protect privacy while maintaining its utility for testing, development, or analysis. Effective implementation requires careful consideration of the specific data types, regulatory requirements, and intended uses of the migrated data.
Data Masking Techniques
Data masking involves altering sensitive data to conceal its original values, while preserving its format and usability. This process allows organizations to use data for various purposes without exposing confidential information.
- Substitution: This technique replaces sensitive data elements with realistic, but fabricated, values. For example, a credit card number could be replaced with a randomly generated, but valid, credit card number format. The substitution should maintain the data type and format to ensure data integrity for testing or analysis.
Example:
Original Data:
Customer ID Credit Card Number Name Address 12345 5123-4567-8901-2345 John Doe 123 Main St, Anytown Masked Data (Substitution):
Customer ID Credit Card Number Name Address 12345 5432-1098-7654-3210 Jane Smith 456 Oak Ave, Othertown - Shuffling: Shuffling involves reordering the values within a column while maintaining the original data type. This method preserves the statistical properties of the data but removes the link between the original values and the associated records.
Example:
Original Data:
Customer ID Email 1 [email protected] 2 [email protected] 3 [email protected] Masked Data (Shuffling):
Customer ID Email 1 [email protected] 2 [email protected] 3 [email protected] - Redaction: Redaction removes or blanks out specific parts of the data. This technique is often used for sensitive data like social security numbers or medical records.
Example:
Original Data:
Social Security Number Medical Record 123-45-6789 Patient X has diabetes. Masked Data (Redaction):
Social Security Number Medical Record XXX-XX-XXXX Patient X has [REDACTED]. - Data Generation: This technique generates synthetic data that mimics the characteristics of the original data. This is useful when the original data is not available or needs to be significantly altered.
Example:
Original Data:
Zip Code Income 90210 100000 Masked Data (Data Generation):
Zip Code Income 91001 85000 - Character Masking: This involves replacing some or all characters in a data field with masking characters. It is useful for partially obscuring sensitive information.
Example:
Original Data:
Phone Number 555-123-4567 Masked Data (Character Masking):
Phone Number XXX-XXX-4567
Anonymization vs. Pseudonymization
Anonymization and pseudonymization are both techniques used to protect personal data, but they differ in their approach and the level of protection they provide. Understanding these differences is crucial for choosing the right method during data migration.
- Anonymization: Anonymization transforms data in a way that makes it impossible to identify the original subject, even with additional information. This process involves removing or modifying all identifying information, rendering the data non-personal. Anonymized data falls outside the scope of data protection regulations like GDPR. Techniques include generalization, suppression, and record swapping.
Example:
Original Data:
Name Age City John Doe 30 New York Anonymized Data (Generalization and Suppression):
Age Range Region 20-39 Northeast - Pseudonymization: Pseudonymization replaces identifying information with pseudonyms (artificial identifiers). Unlike anonymization, pseudonymized data can potentially be re-identified if the key to the pseudonyms is available. This technique is often used to protect data while allowing for some level of data analysis or tracking. Pseudonymized data is still considered personal data and is subject to data protection regulations. Techniques include tokenization and encryption.
Example:
Original Data:
Name Email John Doe [email protected] Pseudonymized Data (Tokenization):
Pseudonym Email Token123 [email protected] - Comparison: The key difference lies in the reversibility. Anonymization aims to make re-identification impossible, while pseudonymization allows for re-identification with the appropriate key. Anonymization offers stronger privacy protection but may limit the utility of the data. Pseudonymization provides a balance between privacy and utility, making it suitable for various data processing tasks while still complying with data protection regulations. The choice between these methods depends on the specific requirements of the data migration project and the acceptable level of risk.
Applying a Data Masking Technique: Substitution Example
Applying data masking techniques requires careful planning and execution to ensure that the masked data remains useful for its intended purpose. Here is a detailed example of applying the substitution technique to a sample dataset.
Consider a dataset containing customer information that needs to be migrated to a development environment for testing. The dataset includes personally identifiable information (PII) such as names, email addresses, and credit card numbers.
To protect this sensitive data, the substitution masking technique can be applied.
Step 1: Data Selection and AnalysisIdentify the sensitive data fields that need to be masked. In this example, the fields to be masked are:
- Credit Card Number
- Email Address
- Phone Number
- Address
Step 2: Define Masking RulesDefine the specific masking rules for each field. For substitution, this involves determining how the original values will be replaced.
- Credit Card Number: Replace with a valid, but randomly generated, credit card number format (e.g., using a Luhn algorithm to ensure validity).
- Email Address: Replace with a generic email address format (e.g., [email protected]).
- Phone Number: Replace with a randomly generated phone number.
- Address: Replace with a randomly generated address.
Step 3: Implement MaskingImplement the masking rules using a data masking tool or script. The following is an example using a simplified Python script:
“`pythonimport randomimport redef generate_credit_card(): # Simplified Luhn algorithm for generating valid credit card numbers card_number = ”.join(random.choices(‘0123456789’, k=16)) return card_numberdef mask_email(email): return “[email protected]”def mask_phone(phone): return “555-123-4567″def mask_address(address): return “123 Fake St, Anytown”def mask_data(data): masked_data = [] for row in data: masked_row = for key, value in row.items(): if key == “Credit Card Number”: masked_row[key] = generate_credit_card() elif key == “Email”: masked_row[key] = mask_email(value) elif key == “Phone”: masked_row[key] = mask_phone(value) elif key == “Address”: masked_row[key] = mask_address(value) else: masked_row[key] = value masked_data.append(masked_row) return masked_data# Sample Datasample_data = [ “Customer ID”: 1, “Credit Card Number”: “1234-5678-9012-3456”, “Email”: “[email protected]”, “Phone”: “555-123-4567”, “Address”: “123 Main St, Anytown”, “Customer ID”: 2, “Credit Card Number”: “9876-5432-1098-7654”, “Email”: “[email protected]”, “Phone”: “555-987-6543”, “Address”: “456 Oak Ave, Othertown”]# Apply Maskingmasked_sample_data = mask_data(sample_data)# Print Masked Datafor row in masked_sample_data: print(row)“`
Step 4: Test and ValidateTest the masked data to ensure that the masking rules have been applied correctly and that the data format and usability are preserved.
Validate the masked data against the original data to verify that the masking process did not introduce any errors or inconsistencies.
Step 5: Migrate Masked DataMigrate the masked data to the target environment (e.g., the development environment).
Original Data:
| Customer ID | Credit Card Number | Phone | Address | |
|---|---|---|---|---|
| 1 | 1234-5678-9012-3456 | [email protected] | 555-123-4567 | 123 Main St, Anytown |
| 2 | 9876-5432-1098-7654 | [email protected] | 555-987-6543 | 456 Oak Ave, Othertown |
Masked Data (Substitution):
| Customer ID | Credit Card Number | Phone | Address | |
|---|---|---|---|---|
| 1 | 5432-1098-7654-3210 | [email protected] | 555-123-4567 | 123 Fake St, Anytown |
| 2 | 6789-0123-4567-8901 | [email protected] | 555-123-4567 | 123 Fake St, Anytown |
This example demonstrates the basic steps involved in applying the substitution technique. The specific implementation and complexity will vary depending on the size and complexity of the dataset, the masking tool used, and the specific data protection requirements.
Secure Data Transfer Methods
Data migration necessitates the secure transit of sensitive information across networks, demanding the implementation of robust protocols and encryption techniques to safeguard confidentiality, integrity, and availability. The selection of appropriate transfer methods is crucial, considering factors like data volume, network bandwidth, and security requirements. This section explores secure data transfer protocols, encryption methodologies, and their practical application in real-world scenarios.
Secure Data Transfer Protocols
Various protocols facilitate the secure transfer of data, each possessing distinct strengths and weaknesses. Choosing the optimal protocol depends on the specific migration context, including the sensitivity of the data and the infrastructure capabilities.
- Secure Shell (SSH): SSH provides a secure channel for transferring data between systems. It utilizes encryption to protect data in transit, ensuring confidentiality and integrity. Its key strength lies in its robust security features, making it suitable for transferring sensitive data. However, the transfer speed can be slower compared to other protocols, particularly for large files. The primary use case involves secure remote access and file transfer between servers.
- Secure File Transfer Protocol (SFTP): SFTP, built on top of SSH, offers a secure method for file transfer. It encrypts both the data and the control commands, ensuring secure file operations. SFTP is widely supported and offers features like file integrity checking. It is often preferred for transferring files between a client and a server, such as uploading backups or distributing software updates.
- HTTPS (Hypertext Transfer Protocol Secure): HTTPS employs Transport Layer Security (TLS) or Secure Sockets Layer (SSL) to encrypt communication between a web server and a client. It is commonly used for web-based data transfers and ensures data confidentiality. While HTTPS is generally secure, its reliance on certificate authorities makes it susceptible to vulnerabilities if certificates are compromised. It is frequently used for accessing web applications and transferring data through web browsers.
- Aspera FASP (Fast, Adaptive, Secure Protocol): Aspera FASP is a proprietary protocol designed for high-speed data transfer over wide area networks. It utilizes a UDP-based transport protocol, enabling faster transfer speeds than TCP-based protocols like SFTP, especially over long distances. FASP offers robust security features, including encryption and authentication. It is commonly used for transferring large datasets, such as media files or scientific data, where speed is critical.
- WebDAVS (Web Distributed Authoring and Versioning over SSL/TLS): WebDAVS extends HTTP/S to enable collaboration and document management. It secures data transfer through SSL/TLS encryption, providing confidentiality and integrity. WebDAVS supports file locking and versioning features. It is frequently used for collaborative document editing and sharing across networks.
Encryption During Data Transfer
Encryption is a fundamental component of secure data transfer, transforming data into an unreadable format to protect its confidentiality. Different encryption methods offer varying levels of security and performance characteristics.
- Symmetric Encryption: Symmetric encryption utilizes the same key for both encryption and decryption. It is generally faster than asymmetric encryption, making it suitable for encrypting large volumes of data. Examples include Advanced Encryption Standard (AES) and Data Encryption Standard (DES).
AES is widely adopted due to its robust security and performance, offering various key lengths (128, 192, and 256 bits) to provide different security levels.
- Asymmetric Encryption: Asymmetric encryption uses a pair of keys: a public key for encryption and a private key for decryption. This method enables secure key exchange and digital signatures. Examples include Rivest-Shamir-Adleman (RSA) and Elliptic-Curve Cryptography (ECC).
RSA is a widely used algorithm, while ECC offers similar security with shorter key lengths, making it suitable for resource-constrained environments.
- Hashing Algorithms: Hashing algorithms generate a fixed-size output (hash) from input data. They are used to verify data integrity by detecting any changes to the data. Examples include SHA-256 and MD5. Hashing alone does not provide encryption; it’s primarily used for integrity checks.
SHA-256 is a widely used hashing algorithm known for its strong collision resistance. MD5, while once popular, is considered cryptographically broken and should not be used for security-critical applications.
- Encryption Modes: Encryption modes define how the encryption algorithm is applied to the data. Common modes include Cipher Block Chaining (CBC), Electronic Codebook (ECB), and Counter (CTR).
CBC mode provides better security than ECB by incorporating the previous ciphertext block into the encryption of the current block. CTR mode allows parallel encryption and decryption, improving performance.
Implementation of a Secure Data Transfer Protocol: Real-World Scenario
Consider a scenario where a financial institution migrates customer data from an on-premises data center to a cloud environment. The data includes sensitive information like Personally Identifiable Information (PII) and financial records. The institution needs to ensure the secure transfer of this data.The following steps can be taken:
- Protocol Selection: SFTP is chosen as the primary protocol for data transfer due to its robust security features and widespread support.
- Encryption Implementation:
- All data is encrypted using AES-256 symmetric encryption before transfer. The encryption key is managed securely using a key management system (KMS) within the cloud environment.
- SFTP encrypts the data and control commands during transfer, protecting the data from eavesdropping.
- Authentication and Authorization:
- Multi-factor authentication is implemented to verify the identities of users initiating data transfers.
- Access controls are configured to restrict data access based on the principle of least privilege.
- Monitoring and Auditing:
- All data transfer activities are logged, including timestamps, user identities, and data transfer sizes.
- Security Information and Event Management (SIEM) systems are used to monitor the logs for suspicious activity and security incidents.
- Real-world Example: A major financial institution migrated customer data using SFTP with AES-256 encryption and implemented rigorous access controls. This migration involved several terabytes of data. After the migration, the institution conducted regular security audits and penetration tests to ensure the continued security of the data. This approach resulted in a successful and secure data migration, preventing any data breaches.
Access Control and Authentication
Ensuring robust access control and authentication mechanisms is paramount throughout the data migration process to safeguard sensitive information. Implementing these measures effectively prevents unauthorized access, data breaches, and potential misuse of migrated data. The following sections detail the implementation of these critical security components.
Implementing Access Control Mechanisms
Implementing robust access control mechanisms requires a layered approach, encompassing both technical and administrative controls. This ensures that only authorized personnel can access specific data, minimizing the risk of data exposure.
- Role-Based Access Control (RBAC): RBAC assigns permissions based on user roles. This approach simplifies access management, as changes to access rights can be applied to roles rather than individual users. For example, a ‘Data Analyst’ role might have read-only access to a specific dataset, while a ‘Data Administrator’ role could have full read, write, and modify permissions. This aligns with the principle of least privilege, granting users only the necessary access.
- Attribute-Based Access Control (ABAC): ABAC refines access control by considering attributes of the user, the data, and the environment. This provides a more granular and flexible approach. For instance, access to financial data might be restricted based on the user’s department, the sensitivity level of the data, and the time of day. ABAC can be particularly useful in complex data environments.
- Data Encryption: Encrypting data at rest and in transit is a fundamental access control measure. Even if unauthorized access occurs, the encrypted data remains unreadable without the appropriate decryption keys. Encryption should be implemented using strong cryptographic algorithms such as AES-256.
- Network Segmentation: Isolating the data migration environment from other networks limits the attack surface. This prevents unauthorized access from compromised systems on other networks. The data migration environment should be on a separate network segment, and access should be strictly controlled.
- Regular Auditing: Implementing comprehensive auditing of access logs is crucial. These logs should record all access attempts, successful and unsuccessful, including user ID, timestamp, data accessed, and action performed. Regular review of these logs allows for the detection of suspicious activity and potential security breaches.
Authentication Methods for Secure Access
Strong authentication methods are essential to verify the identity of users accessing migrated data. Implementing multi-factor authentication (MFA) is highly recommended to enhance security.
- Multi-Factor Authentication (MFA): MFA requires users to provide multiple forms of authentication, such as a password and a one-time code generated by a mobile app or sent via SMS. This significantly increases security by making it much harder for attackers to gain unauthorized access, even if they compromise a user’s password.
- Password Management: Enforcing strong password policies, including length, complexity, and regular changes, is crucial. Using password managers and avoiding the reuse of passwords across different systems are also essential.
- Biometric Authentication: Biometric authentication, such as fingerprint or facial recognition, provides a highly secure method of verifying user identity. This method is especially valuable in sensitive data environments.
- Certificate-Based Authentication: Using digital certificates for authentication provides a strong, cryptographic-based method of verifying user identity. This is particularly useful for securing access to critical systems and data.
- Single Sign-On (SSO): SSO allows users to access multiple applications with a single set of credentials. This improves user experience while still providing a centralized authentication mechanism. However, the SSO system itself must be secured.
Workflow Diagram: User Access Control During Data Migration
The following workflow diagram illustrates the user access control process during data migration. This diagram highlights the steps involved in granting, managing, and revoking user access, ensuring data security throughout the migration lifecycle.
Workflow Diagram Description:
The diagram begins with a user requesting access to the migrated data. The request triggers an access request process, involving user authentication and authorization checks. These checks are performed against an identity provider and access control lists (ACLs). If the user is authorized, access is granted, and audit logs are generated. If the user is not authorized, access is denied, and an alert is triggered.
The diagram also illustrates the continuous monitoring of access, including regular audits, and the process of revoking access when necessary. This comprehensive approach ensures data security throughout the migration process.
Detailed Steps:
- Access Request: A user initiates a request to access migrated data.
- Authentication: The user’s identity is verified using an authentication method (e.g., MFA, password).
- Authorization: The system checks the user’s role and permissions against the defined access control policies (e.g., RBAC, ABAC).
- Access Granted/Denied: Based on the authorization check, access is either granted or denied.
- Auditing: All access attempts, successful and unsuccessful, are logged for auditing purposes.
- Data Access: If access is granted, the user can access the migrated data.
- Monitoring and Auditing: Continuous monitoring of access logs and regular audits are performed to detect anomalies and potential security breaches.
- Access Revocation: Access is revoked when necessary (e.g., user leaves the organization, role changes).
Compliance with Regulations (GDPR, CCPA, etc.)
Data migration, while essential for business agility and innovation, presents significant challenges regarding compliance with data privacy regulations. These regulations, such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), mandate specific requirements for how personal data is handled, including during migration processes. Failure to comply can result in substantial penalties and reputational damage.
GDPR and CCPA Requirements for Data Migration
Both GDPR and CCPA place stringent demands on data processing activities, including data migration. These regulations prioritize the protection of individuals’ rights regarding their personal data. Understanding the specific requirements of each regulation is crucial for a compliant data migration strategy.
Regarding GDPR:
The GDPR, applicable to organizations processing the personal data of individuals within the European Economic Area (EEA), dictates several key requirements during data migration:
- Lawful Basis for Processing: Data migration must be based on a valid legal basis, such as consent, contract, or legitimate interest. The chosen basis must be appropriate for the data being migrated and the purpose of the migration.
- Data Minimization: Only data that is strictly necessary for the intended purpose of the migration should be migrated. This principle helps reduce the scope of potential data breaches and minimizes compliance burden.
- Purpose Limitation: Data should only be processed for the specific, explicit, and legitimate purposes for which it was collected. The migration process should align with these original purposes.
- Data Subject Rights: Organizations must facilitate the exercise of data subject rights, including the right to access, rectify, erase, and restrict processing of their data. These rights must be honored throughout the migration process, ensuring that individuals retain control over their data.
- Security Measures: Appropriate technical and organizational measures must be implemented to ensure the security of personal data during migration, protecting it from unauthorized access, loss, or alteration. This includes encryption, access controls, and regular security audits.
- Data Protection Impact Assessments (DPIAs): DPIAs may be required, especially when migrating large volumes of sensitive data or when the migration involves high-risk processing activities. DPIAs help identify and mitigate potential privacy risks.
- Notification of Data Breaches: Organizations must notify the relevant supervisory authority and affected data subjects of any data breaches within 72 hours of becoming aware of them. This applies even during the migration process.
Regarding CCPA:
The CCPA, applicable to businesses that collect, sell, or share the personal information of California residents, imposes the following key requirements during data migration:
- Right to Know: Consumers have the right to know what personal information is being collected, used, and shared. This right extends to data migration activities, requiring businesses to be transparent about how data is being moved.
- Right to Delete: Consumers have the right to request the deletion of their personal information. Organizations must ensure that data deletion requests are honored during the migration process, including deleting data from both the source and target systems.
- Right to Opt-Out of Sale: Consumers have the right to opt-out of the sale of their personal information. If data migration involves the sale of personal information, organizations must provide consumers with the opportunity to opt-out.
- Right to Non-Discrimination: Businesses cannot discriminate against consumers who exercise their CCPA rights. This principle applies to the migration process, ensuring that individuals are not penalized for exercising their rights.
- Security Measures: Businesses must implement reasonable security measures to protect personal information from unauthorized access, disclosure, or use during the migration process.
Ensuring Compliance During Data Migration
Compliance with data privacy regulations during data migration requires a multifaceted approach. It involves careful planning, robust technical controls, and adherence to established data governance principles.
Strategies for ensuring compliance include:
- Data Mapping: Conducting a comprehensive data inventory and mapping exercise to understand the location, type, and sensitivity of data being migrated. This helps identify the specific regulations that apply and the necessary compliance measures.
- Data Masking and Anonymization: Employing data masking and anonymization techniques to protect sensitive data during migration. This reduces the risk of unauthorized access and helps ensure compliance with data minimization principles.
- Secure Data Transfer: Utilizing secure data transfer methods, such as encrypted connections and secure file transfer protocols, to protect data in transit. This minimizes the risk of data breaches during the migration process.
- Access Control and Authentication: Implementing robust access controls and authentication mechanisms to restrict access to data during migration to authorized personnel only. This prevents unauthorized access and helps maintain data security.
- Data Retention Policies: Establishing clear data retention policies and ensuring that data is retained only for as long as necessary. This helps minimize the volume of data subject to compliance requirements.
- Documentation: Maintaining thorough documentation of all data migration activities, including data mapping, security measures, and compliance procedures. This provides a clear audit trail and demonstrates compliance efforts.
- Training: Providing comprehensive training to all personnel involved in the data migration process on data privacy regulations, security best practices, and compliance procedures. This ensures that all staff are aware of their responsibilities.
- Vendor Management: Carefully selecting and managing third-party vendors involved in the data migration process, ensuring that they also comply with data privacy regulations. This includes conducting due diligence and incorporating data privacy requirements into vendor contracts.
- Regular Audits and Assessments: Conducting regular audits and assessments to monitor compliance and identify areas for improvement. This ensures that compliance efforts are effective and that any necessary adjustments are made.
Penalties for Non-Compliance
Non-compliance with data privacy regulations can result in significant penalties, including financial fines, reputational damage, and legal action. The specific penalties vary depending on the regulation and the severity of the violation.
Penalties breakdown for GDPR:
- Financial Fines: Organizations can be fined up to €20 million or 4% of their annual global turnover, whichever is higher, for serious violations of GDPR. Fines are tiered, with less severe violations attracting lower penalties. For example, failing to implement adequate security measures that lead to a data breach could result in a significant fine.
- Reputational Damage: Data breaches and non-compliance can severely damage an organization’s reputation, leading to a loss of customer trust and business opportunities. News of a GDPR violation can spread quickly, impacting public perception.
- Legal Action: Data subjects can take legal action against organizations that violate their GDPR rights, potentially leading to lawsuits and compensation claims. These legal actions can be costly and time-consuming.
- Corrective Actions: Supervisory authorities can impose corrective actions, such as requiring organizations to implement specific data protection measures or to cease data processing activities. These actions can disrupt business operations and require significant resources to implement.
Penalties breakdown for CCPA:
- Financial Fines: Organizations can be fined up to $7,500 per violation for each intentional violation of the CCPA and $2,500 per violation for each unintentional violation. These fines can quickly accumulate, especially in the case of a data breach affecting a large number of California residents.
- Private Right of Action: Consumers have the right to sue businesses for data breaches resulting from a failure to implement reasonable security measures. This can lead to significant legal costs and compensation claims.
- Legal Action: The California Attorney General can take legal action against businesses that violate the CCPA, including seeking injunctions and civil penalties.
- Business Restrictions: Businesses that repeatedly violate the CCPA may face restrictions on their ability to collect, sell, or share personal information.
Data Backup and Recovery Strategies
Data backup and recovery are crucial components of a successful and secure data migration strategy. Implementing robust backup and recovery plans ensures data integrity, minimizes downtime, and protects against data loss during the migration process. A well-defined strategy allows for the swift restoration of data in case of unforeseen events, such as hardware failures, human errors, or cyberattacks, preserving business continuity.
Significance of Data Backup and Recovery Plans During Migration
A data backup and recovery plan is of paramount importance during data migration. It safeguards against data loss, corruption, or unavailability, which can arise from various issues throughout the migration process. A comprehensive plan incorporates regular backups, secure storage, and a clearly defined recovery process. This plan is essential to mitigate risks and ensure the successful transfer of data.
Best Practices for Data Backup and Recovery
Following best practices for data backup and recovery is critical to protect data during migration.
- Establish a Backup Schedule: Implement a consistent backup schedule that aligns with the data’s volatility and the recovery point objective (RPO). The RPO defines the maximum acceptable data loss in a disaster scenario. This schedule should include full, incremental, and differential backups. A full backup copies all data, while incremental backups only copy data changed since the last backup, and differential backups copy data changed since the last full backup.
- Choose Appropriate Backup Methods: Select backup methods that suit the specific data and infrastructure. Options include:
- Full Backups: These are the most comprehensive, backing up all data. They provide the fastest recovery time but require more storage space and time to perform.
- Incremental Backups: These back up only the data that has changed since the last backup (full or incremental). They are faster than full backups but slower to restore.
- Differential Backups: These back up the data that has changed since the last full backup. They are faster than full backups but slower to restore than incremental backups.
- Implement Data Validation: Regularly validate backups to confirm data integrity. This involves restoring data to a test environment and verifying its accuracy and completeness. Data validation reduces the risk of restoring corrupted or incomplete data.
- Test Recovery Procedures: Periodically test the recovery procedures to ensure they function correctly and that the recovery time objective (RTO) is met. The RTO defines the maximum acceptable downtime in a disaster scenario.
- Secure Backup Storage: Protect backup data with robust security measures, including encryption, access controls, and physical security. Ensure backups are stored in a geographically diverse location to protect against site-specific disasters. Consider offsite or cloud-based backup solutions.
- Automate Backup Processes: Automate the backup process to reduce the risk of human error and ensure consistency. Utilize backup software that provides automated scheduling, monitoring, and reporting capabilities.
Strategies for Ensuring Data Integrity and Availability
Data integrity and availability are fundamental during data migration. Strategies to ensure these factors include careful planning, implementation, and monitoring throughout the migration process.
- Data Verification Checks: Implement data verification checks before, during, and after the migration. These checks can involve checksums, hash functions, and data validation scripts to identify and correct any data corruption or inconsistencies.
- Redundancy and Replication: Employ redundancy and replication mechanisms to ensure data availability. This can include replicating data to multiple storage locations or implementing a failover mechanism that automatically switches to a secondary system if the primary system fails.
- Version Control: Utilize version control systems to track changes to data and configurations. This allows for the rollback to previous versions in case of errors or data corruption.
- Monitoring and Alerting: Implement a robust monitoring system to track the migration process, including data transfer rates, error rates, and system performance. Set up alerts to notify administrators of any issues that require immediate attention.
- Staged Migration: Perform the migration in stages to minimize the impact on business operations. This allows for testing and validation at each stage, reducing the risk of widespread data loss or downtime. A staged approach also provides an opportunity to identify and resolve issues before they impact the entire dataset.
Disaster Recovery Plan for a Data Migration Project
A well-defined disaster recovery plan is essential to ensure business continuity during a data migration project. This plan Artikels the steps to be taken in the event of a disaster, such as data loss, system failure, or security breach.
- Assessment and Planning:
- Identify potential threats and risks that could disrupt the migration process.
- Define recovery point objectives (RPO) and recovery time objectives (RTO) for critical data and systems.
- Establish a communication plan to inform stakeholders of the disaster and recovery progress.
- Backup Procedures:
- Establish a schedule for regular backups of the source and target data.
- Implement data validation procedures to ensure backup integrity.
- Store backups in a secure and geographically diverse location.
- Recovery Procedures:
- Define step-by-step procedures for restoring data from backups.
- Document the order in which systems and applications should be restored.
- Test the recovery procedures regularly to ensure they function correctly.
- Testing and Validation:
- Conduct regular disaster recovery drills to simulate various disaster scenarios.
- Validate the recovery procedures and make adjustments as needed.
- Document the results of the tests and update the plan accordingly.
- Communication and Coordination:
- Establish clear communication channels to inform stakeholders of the disaster and recovery progress.
- Assign roles and responsibilities to individuals involved in the recovery process.
- Coordinate with relevant third parties, such as cloud providers or vendors.
Monitoring and Auditing

Continuous monitoring and robust auditing are crucial for maintaining data privacy throughout the data migration process and after its completion. These practices ensure that data is handled securely, access is controlled appropriately, and any potential breaches or anomalies are quickly identified and addressed. They provide an audit trail for compliance, allowing organizations to demonstrate adherence to privacy regulations and internal policies.
Importance of Continuous Monitoring
Continuous monitoring serves as a proactive defense against data breaches and privacy violations. It involves the constant surveillance of data access, data transfer activities, and system performance to detect any suspicious or unauthorized actions. This real-time visibility allows for immediate response to potential threats, minimizing the impact of any security incidents.
- Real-time Threat Detection: Monitoring systems continuously analyze data access patterns, network traffic, and system logs to identify anomalies and potential security breaches. For example, unusual access from unexpected locations or an excessive number of failed login attempts could trigger an alert.
- Performance Optimization: Monitoring helps identify performance bottlenecks and inefficiencies in the data migration process. By tracking key metrics such as data transfer speeds, resource utilization, and error rates, organizations can optimize the migration strategy and ensure a smooth transition.
- Compliance Verification: Continuous monitoring provides evidence of compliance with data privacy regulations such as GDPR and CCPA. By tracking data access, changes, and transfers, organizations can demonstrate that they are adhering to the required security and privacy controls.
- Incident Response: In the event of a security incident, monitoring data provides valuable information for investigation and response. This includes identifying the scope of the breach, the affected data, and the actions taken by the attacker.
Auditing Mechanisms for Data Access and Changes
Auditing mechanisms provide a detailed record of data access and changes, enabling organizations to track who accessed data, when they accessed it, and what actions they performed. This audit trail is essential for identifying unauthorized access, detecting data manipulation, and investigating security incidents.
- Access Logging: Access logging records every attempt to access data, including the user’s identity, the data accessed, the time of access, and the method of access. This includes database queries, file access, and API calls.
- Change Tracking: Change tracking captures any modifications made to data, including the user who made the change, the date and time of the change, and the specific data elements that were modified. This can be implemented at the database level using triggers or through version control systems for files.
- User Activity Monitoring: User activity monitoring tracks user behavior within the system, including the applications they use, the websites they visit, and the files they open. This can help identify unusual or suspicious activity that may indicate a security breach.
- Security Information and Event Management (SIEM) Systems: SIEM systems collect and analyze security-related data from various sources, including logs, network traffic, and security devices. They use this data to detect and respond to security threats, providing a centralized view of security events.
Data Migration Audit Report Template
A well-structured audit report provides a comprehensive overview of the data migration process, including key metrics, findings, and recommendations. This report should be generated regularly throughout the migration process and after its completion to ensure that data privacy and security are maintained.
Here’s a sample audit report template:
| Report Section | Description | Example/Key Metrics |
|---|---|---|
| Executive Summary | Overview of the audit, including key findings and recommendations. | Summarize the overall assessment of data privacy and security during the migration. |
| Migration Scope | Description of the data migration project, including the data sources, targets, and scope. | Identify all databases, applications, and data sets involved in the migration. |
| Data Inventory and Classification Review | Assessment of the data inventory and classification process. | Verify the accuracy and completeness of the data inventory, classification, and sensitivity levels. |
| Data Masking and Anonymization Assessment | Evaluation of the data masking and anonymization techniques used. | Verify the effectiveness of data masking techniques in protecting sensitive data. For example, check that personally identifiable information (PII) like Social Security numbers or credit card numbers were properly masked. Check that data anonymization techniques are used to remove identifiers and allow for data utility without compromising privacy. |
| Secure Data Transfer Review | Assessment of the methods used for secure data transfer. | Confirm the use of encryption, secure protocols (e.g., HTTPS, SFTP), and access controls during data transfer. For example, verify the use of TLS/SSL encryption for all data transfers between the source and target systems. |
| Access Control and Authentication Review | Evaluation of the access control and authentication mechanisms. | Verify the implementation of role-based access control (RBAC), multi-factor authentication (MFA), and strong password policies. For example, verify that only authorized personnel have access to sensitive data during the migration. |
| Compliance with Regulations Review | Assessment of compliance with relevant data privacy regulations (e.g., GDPR, CCPA). | Verify compliance with GDPR and CCPA requirements, including data subject rights, data breach notification, and data minimization. For example, confirm that data subject requests for data access, rectification, or erasure were handled appropriately. |
| Monitoring and Auditing Review | Evaluation of the monitoring and auditing mechanisms. | Verify the implementation of access logging, change tracking, and SIEM systems. For example, review audit logs to identify any unauthorized access or data modifications. |
| Data Backup and Recovery Review | Assessment of the data backup and recovery strategies. | Verify the implementation of data backup and recovery procedures to ensure data availability and integrity. For example, confirm that data backups were performed regularly and that recovery procedures were tested. |
| Key Metrics | Key performance indicators (KPIs) related to data migration. | Data transfer speed, error rates, number of data records migrated, and resource utilization. |
| Findings | Summary of the audit findings, including any identified vulnerabilities or risks. | Identify any areas where data privacy or security controls were not properly implemented or maintained. |
| Recommendations | Recommendations for addressing the identified findings and improving data privacy and security. | Provide specific recommendations for mitigating risks and improving data privacy and security. For example, recommend the implementation of stronger access controls or the enhancement of data masking techniques. |
| Conclusion | Overall assessment of the data migration process. | State whether the data migration process was successful and whether data privacy and security were maintained. |
For example, a finding might be “Insufficient access control on the target database”. A corresponding recommendation could be “Implement role-based access control (RBAC) and restrict access to only authorized personnel.”
User Training and Awareness

Data privacy during migration is not solely a technical undertaking; it heavily relies on the human element. Employees must understand their roles and responsibilities in protecting sensitive data throughout the migration process. Robust user training and awareness programs are essential to cultivate a culture of data privacy, minimizing the risk of human error and ensuring compliance with relevant regulations. A well-informed workforce is a critical defense against data breaches and privacy violations.
Importance of User Training on Data Privacy
Training users on data privacy best practices is paramount before, during, and after a data migration. This ensures all employees are aware of their obligations and how to handle sensitive data responsibly. The effectiveness of data protection measures hinges on user compliance. Without adequate training, employees may inadvertently expose sensitive information, leading to significant risks.
- Pre-Migration Training: Before the migration begins, employees must understand the importance of data classification, secure handling of data, and potential risks associated with the migration. This includes identifying sensitive data, understanding access controls, and knowing how to report potential security incidents.
- During-Migration Training: During the migration, employees should be trained on any new systems or procedures implemented. This ensures that they can properly utilize new tools and understand their responsibilities for maintaining data privacy in the new environment. This also covers the handling of temporary data and the procedures for reporting any issues.
- Post-Migration Training: After the migration is complete, ongoing training is necessary to reinforce best practices and to familiarize employees with the new data environment. This includes refresher courses on data privacy policies, updates on new regulations, and training on how to use new features and systems.
Examples of Training Materials and Awareness Programs
Effective training programs incorporate various materials and methods to cater to different learning styles and ensure comprehensive coverage of relevant topics. These programs aim to create a data-privacy-conscious environment.
- Interactive Online Modules: These modules often include videos, quizzes, and interactive simulations to engage users and test their understanding of data privacy concepts. They are designed to be accessible and easily integrated into existing training platforms.
- In-Person Workshops: Workshops offer a more personalized learning experience, allowing for direct interaction with trainers and the opportunity to ask questions. These workshops are often used to cover complex topics or to discuss specific scenarios relevant to the organization.
- Regular Email Communications: Regular emails provide updates on data privacy policies, highlight security incidents, and share best practices. These communications reinforce key messages and keep data privacy top of mind.
- Posters and Infographics: Posters and infographics displayed in the workplace serve as visual reminders of data privacy principles and provide quick reference guides for common tasks. These are designed to be eye-catching and easy to understand.
- Phishing Simulations: Simulated phishing attacks test employees’ ability to recognize and report suspicious emails. These simulations provide valuable insights into employee behavior and help to identify areas where additional training is needed.
- Data Privacy Awareness Campaigns: These campaigns involve a series of activities, such as quizzes, contests, and presentations, to raise awareness about data privacy. They can be used to engage employees and create a more positive and proactive attitude towards data protection.
Brief Training Module on Data Privacy for Employees
This training module provides a concise overview of essential data privacy concepts for employees, delivered in bullet points to emphasize key takeaways.
- Data Classification: Understand the different levels of data sensitivity (e.g., public, internal, confidential, restricted). Handle each type of data according to its classification level.
- Data Handling: Only access data that is required for your job. Store sensitive data securely. Avoid sharing sensitive information through unsecured channels (e.g., personal email, unencrypted messaging apps).
- Access Control: Use strong passwords and protect your login credentials. Report any unauthorized access attempts immediately.
- Data Minimization: Collect and retain only the data that is necessary for legitimate business purposes. Regularly review and delete data that is no longer needed.
- Data Breach Reporting: Report any suspected data breaches or privacy violations immediately to the designated security or privacy officer.
- Compliance with Regulations: Be aware of relevant data privacy regulations (e.g., GDPR, CCPA). Understand your responsibilities under these regulations.
- Security Awareness: Be vigilant against phishing, social engineering, and other cyber threats. Report suspicious activities promptly.
- Privacy by Design: When developing or using new systems or processes, consider data privacy implications from the outset.
- Employee Responsibilities: You are responsible for protecting sensitive data. Follow all data privacy policies and procedures.
- Continuous Learning: Participate in ongoing data privacy training and stay informed about the latest threats and best practices.
Data Retention and Disposal
Data retention and disposal are critical components of a secure data migration strategy, ensuring compliance with legal and regulatory frameworks while minimizing the risk of data breaches and unauthorized access. Effective data lifecycle management, including clearly defined retention periods and secure disposal methods, is essential for maintaining data privacy and reducing potential liabilities. The following sections detail procedures, legal requirements, and policy recommendations for the responsible handling of data after migration.
Data Retention Procedures and Legal Requirements
Data retention procedures define the duration for which data is stored, the storage location, and the conditions under which data may be accessed or modified. These procedures must comply with various legal requirements, which vary based on jurisdiction, industry, and the type of data.
- Legal and Regulatory Compliance: Several regulations mandate specific data retention periods. For example, financial data often requires retention for several years to comply with accounting standards and tax regulations. Healthcare data is subject to HIPAA regulations in the United States, specifying retention periods for patient records. GDPR and CCPA, among others, Artikel data minimization principles, which affect data retention practices by encouraging organizations to retain only the data necessary for legitimate purposes and only for as long as needed.
- Data Classification and Retention Schedules: Effective data retention starts with accurate data classification. Each data category should have a defined retention schedule based on its sensitivity, regulatory requirements, and business needs. The schedule should specify the retention period, the storage location, and the trigger for disposal (e.g., date, event).
- Data Storage and Accessibility: Data storage solutions must align with retention schedules. Archived data should be stored securely, with appropriate access controls to prevent unauthorized access. Regular audits should verify that retention policies are enforced correctly. The accessibility of data during its retention period should be governed by strict access controls, including role-based access control (RBAC) and multi-factor authentication (MFA).
- Documentation and Audit Trails: Maintaining comprehensive documentation of data retention policies and procedures is crucial. Audit trails must track all data access, modifications, and disposal activities. These audit trails provide evidence of compliance and assist in investigating potential data breaches.
Importance of Secure Data Deletion
Securely deleting data that is no longer needed is paramount to preventing data breaches and unauthorized access. Simple deletion methods, such as deleting files from a hard drive or moving them to the recycle bin, do not guarantee complete data removal. Data remnants can often be recovered using specialized tools.
- Preventing Data Breaches: The primary objective of secure data deletion is to prevent unauthorized access to sensitive information. By ensuring data is irretrievable, the risk of data breaches due to lost or stolen devices, compromised systems, or insider threats is significantly reduced.
- Compliance with Regulations: Many regulations, such as GDPR and CCPA, require the secure deletion of data when it is no longer needed or when a data subject requests its deletion. Failure to comply can result in significant penalties.
- Reducing Liability: Secure data deletion reduces an organization’s legal and financial liability in the event of a data breach. If data is securely deleted, the potential damage from a breach is significantly reduced.
- Data Sanitization Methods: Data sanitization refers to the process of rendering data permanently unrecoverable. Various methods are used, including:
- Data Overwriting: Overwriting data multiple times with random patterns to make it unrecoverable. This is a common method for hard drives.
- Degaussing: Using a strong magnetic field to erase data on magnetic media, such as hard drives and tapes.
- Physical Destruction: Physically destroying storage media, such as shredding hard drives or incinerating tapes.
Data Disposal Policy Template
A data disposal policy Artikels the procedures for securely deleting data. This policy should be comprehensive, detailing the scope, responsibilities, and methods for data disposal. The following is a template for a data disposal policy, incorporating key sections.
1. Policy Statement
This policy defines the procedures for the secure disposal of data across all organizational systems and media. It ensures compliance with legal and regulatory requirements and minimizes the risk of data breaches.
2. Scope
This policy applies to all organizational data, including electronic and physical records, stored on any media (e.g., hard drives, servers, tapes, cloud storage, paper documents). It encompasses all employees, contractors, and third-party vendors who handle organizational data.
3. Responsibilities
- Data Owners: Responsible for classifying data and determining retention periods based on data sensitivity, legal requirements, and business needs.
- IT Department: Responsible for implementing and maintaining data disposal procedures, ensuring secure data destruction methods are used, and providing training on data disposal policies.
- Employees: Responsible for following data disposal procedures and reporting any suspected policy violations.
4. Data Retention Schedules
Develop and maintain data retention schedules for each data category. These schedules must specify the retention period, storage location, and trigger for disposal. The schedules should be reviewed and updated periodically to reflect changes in legal and business requirements.
5. Secure Data Destruction Methods
Implement approved data destruction methods based on the type of media and the sensitivity of the data.
- Electronic Data: Use data overwriting, degaussing, or physical destruction methods for hard drives, SSDs, and other electronic media. Use data wiping software that adheres to industry standards like NIST 800-88.
- Physical Data: Shred paper documents using cross-cut shredders to render data unreadable. Incinerate or physically destroy other physical media like tapes and CDs.
6. Verification and Documentation
- Verification: Verify the successful completion of data disposal using appropriate methods. For electronic media, verification can include running verification software to confirm that the data has been overwritten. For physical destruction, ensure the media has been rendered unusable.
- Documentation: Maintain detailed records of all data disposal activities, including the type of data, the media used, the disposal method, the date, and the personnel involved. This documentation serves as proof of compliance and aids in audits.
7. Policy Enforcement and Review
- Enforcement: Enforce the data disposal policy through regular training, audits, and disciplinary actions for policy violations.
- Review: Review and update the data disposal policy at least annually or more frequently if there are changes in legal requirements, business practices, or technology.
Closing Summary
In conclusion, securing data privacy during migration is not merely a technical exercise; it is a strategic imperative that demands a holistic approach. By integrating meticulous planning, robust security measures, and unwavering compliance, organizations can successfully navigate the complexities of data migration while preserving the confidentiality, integrity, and availability of sensitive information. This guide serves as a foundational resource, empowering organizations to undertake data migrations with confidence and maintain the trust of their stakeholders in an increasingly data-driven world.
FAQ Summary
What is the first step in ensuring data privacy during migration?
The initial step is a comprehensive risk assessment and the definition of the migration scope, which should identify sensitive data, potential threats, and vulnerabilities specific to the migration project.
How often should data migration security protocols be reviewed?
Security protocols should be reviewed and updated regularly, at least annually, or more frequently if there are changes in regulations, technology, or the threat landscape.
What are the key differences between anonymization and pseudonymization?
Anonymization permanently removes identifying information, making it impossible to link data back to an individual. Pseudonymization replaces identifying information with pseudonyms, allowing re-identification only with additional information or a key.
What happens if data privacy regulations are not followed during migration?
Failure to comply with data privacy regulations can result in significant financial penalties, legal action, and reputational damage, depending on the specific regulations violated.
How can user training contribute to data privacy during migration?
User training educates employees on data privacy best practices, making them aware of the risks and their responsibilities in protecting sensitive information throughout the migration process.