Building a scalable API architecture is crucial for modern application development. This guide delves into the essential principles and strategies required to create an API that can handle increasing volumes of requests and evolving user needs. From foundational design principles to advanced techniques like microservices and load balancing, we’ll explore the entire process.
Designing a scalable API requires careful consideration of various factors, including data storage, security, and performance optimization. This document provides a practical and detailed approach to ensure your API can withstand future growth and maintain optimal performance.
Introduction to Scalable API Architecture
A scalable API architecture is a design that allows an Application Programming Interface (API) to handle increasing amounts of requests and data without significant performance degradation. This adaptability is crucial for modern applications, ensuring consistent service quality even as user demand and data volume grow. Key characteristics of such designs include modularity, efficient resource utilization, and redundancy to accommodate peak loads.Scalability is paramount in today’s application development.
Applications frequently experience surges in user activity, driven by marketing campaigns, viral content, or seasonal demand. Without a scalable API, these spikes can lead to slow response times, service disruptions, and ultimately, lost revenue or user dissatisfaction. Therefore, designing an API with scalability in mind is not just a best practice, but a necessity for long-term application success.
Definition of a Scalable API Architecture
A scalable API architecture is a design that anticipates and accommodates future growth in user traffic and data volume without compromising performance. This proactive approach ensures a consistent and reliable user experience even under significant load. Key features include load balancing, caching mechanisms, and modular components, all contributing to the API’s resilience and responsiveness.
Key Characteristics of a Scalable API Design
Scalable API designs exhibit several key characteristics, crucial for handling varying workloads. These include:
- Modularity: Breaking down the API into independent, reusable components allows for easier maintenance, updates, and scaling of individual parts without affecting the entire system. This modularity is essential for adapting to changes in the application’s needs.
- Load Balancing: Distributing incoming requests across multiple servers prevents overloading any single point of failure. This ensures the API remains responsive even during high-traffic periods, ensuring no single server becomes a bottleneck.
- Caching: Storing frequently accessed data in a cache reduces the load on the backend database or service. This optimized data retrieval significantly improves response times for users.
- Redundancy: Having multiple instances of critical components ensures high availability. If one server fails, others can seamlessly take over, minimizing service disruptions.
- Asynchronous Operations: Employing asynchronous operations allows the API to handle tasks without blocking other requests. This crucial aspect is vital for handling a large number of simultaneous requests.
Importance of Scalability in Modern Application Development
Scalability is essential in modern application development for several reasons:
- Meeting Growing Demands: User bases and data volumes increase over time, necessitating an API that can handle these growing needs.
- Ensuring Reliability: Scalability ensures the API continues to function effectively even during peak demand periods.
- Maintaining Performance: A scalable API maintains consistent response times for users, ensuring a positive user experience.
- Facilitating Future Growth: Scalable designs can easily adapt to future changes in the application’s needs or user expectations.
Example of a Non-Scalable API and its Failure Under Load
Consider an API that uses a single database server and a single application server. All requests are funneled through this single point. Under normal load, this architecture functions adequately. However, when the incoming request rate exceeds the server’s capacity, the response times increase dramatically.
| Request Rate | Response Time | Impact |
|---|---|---|
| Low | Fast | Acceptable performance |
| Medium | Moderate | Performance degrades slightly |
| High | Extremely Slow | API becomes unusable, leading to errors, or even service outage |
This single-point-of-failure design results in an API that is not scalable. When user demand spikes, the system collapses under the load. This non-scalable approach often leads to a poor user experience, potentially impacting revenue and user retention.
API Design Principles for Scalability

Designing scalable APIs necessitates a meticulous approach that considers various factors impacting performance and maintainability. This involves understanding and applying core principles of RESTful design, ensuring efficient data retrieval, and preparing for anticipated high volumes of requests. A well-designed API will not only handle current traffic but also adapt to future growth, minimizing the risk of performance bottlenecks and system failures.Effective API design is paramount for supporting future growth and changing demands.
By adhering to these principles, organizations can create APIs that remain robust and responsive as their application scales and user base expands. This ultimately translates into a superior user experience and maintains the integrity of the application’s overall architecture.
RESTful API Design Principles
RESTful API design principles provide a foundation for building scalable APIs. These principles, when meticulously followed, can significantly improve the efficiency and maintainability of the API. Key principles include using standard HTTP methods (GET, POST, PUT, DELETE), employing well-defined resource URLs, and implementing versioning strategies. This allows for easier integration with other systems and promotes consistency across different components.
- Standard HTTP Methods: Employing standard HTTP methods like GET, POST, PUT, and DELETE ensures clear communication and predictable behavior. This simplifies client implementation and improves interoperability.
- Well-Defined Resource URLs: Using clear and consistent resource URLs, following a logical structure, facilitates client access to specific data points. A well-structured URL system makes the API easier to navigate and understand.
- Versioning Strategies: Implementing versioning allows for changes and improvements to the API without breaking existing client applications. This approach prevents conflicts and allows for future evolution.
Stateless Design for Scalability
Stateless design is a critical aspect of API scalability. A stateless API eliminates the need for the server to retain information about past requests from a client. This dramatically improves scalability, as the server doesn’t need to maintain complex state information for each client interaction. This characteristic enables horizontal scaling, where additional servers can be added without affecting the existing system’s state.
“Statelessness allows for horizontal scaling by enabling the addition of more servers without needing to maintain client state information.”
The stateless nature of the API also enhances resilience. If one server fails, another can seamlessly take over without requiring the client to re-establish a session or handle complex state transitions.
Efficient Data Retrieval
Designing APIs for efficient data retrieval is crucial for scalability. APIs should be optimized to retrieve only the necessary data, minimizing the amount of data transferred. This is achieved through proper pagination, filtering, and sorting mechanisms. Efficient data retrieval translates to faster response times and reduced bandwidth consumption.
- Pagination: Implementing pagination allows clients to retrieve data in manageable chunks, avoiding large downloads that could impact performance. This strategy helps handle large datasets without overloading the server or the client.
- Filtering: Filtering mechanisms enable clients to specify criteria for data retrieval, ensuring that only relevant information is returned. This approach is particularly useful for reducing the amount of data transferred.
- Sorting: Sorting mechanisms enable clients to retrieve data in a specific order, allowing for customized views and reducing the time needed to find specific items.
Handling High Volumes of Requests
Handling high volumes of requests requires careful planning and implementation of strategies for load balancing, caching, and asynchronous processing. Load balancing distributes the incoming traffic across multiple servers, preventing any single server from becoming overloaded. Caching frequently accessed data reduces the load on the backend and improves response times. Asynchronous processing offloads time-consuming tasks, allowing the API to respond quickly to requests.
- Load Balancing: Load balancing distributes incoming requests across multiple servers, preventing any single server from becoming overloaded. This ensures high availability and performance under heavy loads.
- Caching: Caching frequently accessed data reduces the load on the backend and improves response times, as cached data can be served directly from the cache without querying the database.
- Asynchronous Processing: Asynchronous processing offloads time-consuming tasks, allowing the API to respond quickly to requests without waiting for the completion of these tasks.
Microservices Architecture for Scalability

Adopting a microservices architecture is a powerful strategy for building scalable APIs. This approach breaks down a monolithic application into smaller, independent services, each focused on a specific business function. This modularity significantly enhances the agility and scalability of the entire system.This modularity allows teams to develop, deploy, and scale individual services independently, adapting to changing demands without impacting the entire system.
By separating concerns and responsibilities, the system becomes more resilient and easier to maintain. This flexibility allows for faster deployment cycles, enabling quicker responses to market needs and customer demands.
Breaking Down a Large API
Decoupling a large API into microservices involves identifying distinct business functions within the existing API. This often involves analyzing the existing API endpoints and their dependencies to determine logical groupings of related functionalities. For instance, an e-commerce API might be broken down into services for product catalog management, order processing, user accounts, and payment processing. Each service can then be developed, tested, and deployed independently.
This approach fosters team autonomy and encourages faster development cycles.
Designing APIs for Inter-Service Communication
Defining clear communication protocols between microservices is crucial for a smooth workflow. RESTful APIs are commonly used for inter-service communication, enabling services to interact in a standardized and well-defined manner. These APIs need to be meticulously designed to ensure compatibility, reliability, and security.A key aspect of this design is the use of well-structured requests and responses, including appropriate HTTP methods (GET, POST, PUT, DELETE) and status codes.
Furthermore, employing standard formats like JSON for data exchange facilitates seamless communication and integration across services. For instance, a product catalog service might expose an API endpoint to retrieve product details, which is then consumed by an order processing service. These APIs should adhere to specific guidelines to ensure proper data handling and maintain consistency throughout the system.
Utilizing Message Queues
Employing message queues for inter-service communication offers several advantages, particularly when dealing with asynchronous operations. Message queues act as intermediary channels, allowing services to communicate without direct coupling. This decoupling enables services to operate independently, even if other services are temporarily unavailable or experiencing high load.Message queues also facilitate asynchronous communication, allowing services to send messages without waiting for an immediate response.
This is particularly valuable for operations like order processing, where updating inventory or sending notifications to customers can be performed asynchronously without impacting the core order processing workflow. A common example includes a service sending a message to a queue when a new order is placed. A separate service then processes the message from the queue to update the inventory or generate notifications.
Example of Microservice Communication
Consider an example where an order is placed. The order processing service receives the order data and publishes a message to a queue. A separate service then consumes this message from the queue to update the inventory, send a confirmation email, and trigger payment processing. This decoupling allows the order processing service to continue processing other orders without waiting for the completion of inventory updates or email notifications.
These services interact through well-defined APIs and message queues, ensuring flexibility and scalability.
Data Storage and Retrieval Strategies
Designing a scalable API requires careful consideration of how data is stored and retrieved. Efficient data management is crucial for performance, availability, and overall API health. This section explores various database technologies, schema designs, query optimization techniques, and caching strategies to ensure a robust and performant system.Effective data storage and retrieval strategies directly impact API performance. Choosing the right database technology, optimizing query structures, and implementing caching mechanisms are critical to ensuring high throughput and low latency.
By leveraging these techniques, APIs can handle increasing volumes of data and user requests without compromising responsiveness.
Database Technologies
A variety of database technologies are suitable for scalable APIs, each with its own strengths and weaknesses. Choosing the right technology depends on the specific needs of the API, including data volume, complexity, and required transaction characteristics.
- Relational Databases (SQL): Relational databases, such as PostgreSQL and MySQL, are well-suited for structured data and complex queries. Their ACID properties (Atomicity, Consistency, Isolation, Durability) guarantee data integrity in transactions. They are a reliable choice for applications requiring strong data consistency.
- NoSQL Databases: NoSQL databases, such as MongoDB and Cassandra, excel in handling large volumes of unstructured or semi-structured data. They often provide superior scalability and horizontal scalability compared to relational databases. They are suitable for applications with high read/write loads and rapidly changing data structures.
- Cloud-Based Databases: Cloud providers offer managed database services, simplifying deployment and management. These services often provide built-in scalability and high availability features. AWS RDS, Azure SQL Database, and Google Cloud SQL are examples of these services.
Database Schema Design
The database schema significantly impacts API performance. A well-designed schema can lead to efficient data retrieval, while a poorly designed schema can result in slow queries and reduced scalability.
- Normalization: Normalization reduces data redundancy and improves data integrity. It involves organizing data into tables and establishing relationships between them, minimizing data duplication. A well-normalized schema generally leads to more efficient queries and easier maintenance.
- Denormalization: Denormalization, sometimes necessary, combines related data into a single table to optimize query performance. This approach sacrifices some data integrity for improved query speed, particularly when read operations outweigh write operations.
- Schema Flexibility: Modern APIs often require flexible schemas to accommodate evolving data structures. NoSQL databases are often better suited to this requirement, offering the ability to adapt to changing data models more easily than relational databases.
Query Optimization
Efficient database queries are essential for fast data retrieval. Various techniques can significantly improve query performance.
- Indexing: Indexing specific columns in a table allows the database to quickly locate data matching specific criteria. Well-chosen indexes can dramatically speed up query execution.
- Query Optimization Tools: Database management systems (DBMS) often include query optimization tools that analyze queries and suggest improvements. Utilizing these tools can significantly enhance query efficiency.
- Query Structure: The structure of a query directly impacts performance. Avoid using complex joins and subqueries when simpler alternatives exist. The database can optimize queries with a clear, concise structure.
Caching Strategies
Caching frequently accessed data significantly improves API performance. Data stored in a cache is readily available, reducing the load on the database.
- Data Caching Techniques: Implement caching strategies, such as Redis or Memcached, to store frequently accessed data. These in-memory data stores provide fast retrieval compared to disk-based databases.
- Caching Strategies: Employ caching strategies such as caching responses, query results, or frequently accessed objects to reduce database load. Implement caching expiration policies for data that changes frequently.
- Cache Invalidation: Implement mechanisms to invalidate cached data when the underlying data in the database changes. This ensures that cached data remains accurate.
Load Balancing and API Gateway Design

A critical component of any scalable API architecture is the ability to efficiently distribute incoming traffic across multiple API instances. Load balancing and a robust API gateway are essential for ensuring high availability, performance, and resilience. Properly designed systems can handle fluctuating traffic demands and maintain consistent API response times.
Load Balancers and Traffic Distribution
Load balancers act as intermediaries between clients and backend API servers. They intelligently distribute incoming requests to available servers, preventing overload on any single instance. This distribution ensures optimal resource utilization and prevents any single point of failure. Effective load balancing algorithms are crucial for maintaining high performance and availability. By directing requests across multiple instances, load balancers protect against potential bottlenecks and ensure continuous service delivery.
API Gateway Design
A well-designed API gateway acts as a central entry point for all client requests. This central hub provides several key functionalities, including authentication, authorization, rate limiting, and request transformation. By centralizing these functions, the gateway decouples backend services from direct client interactions, simplifying maintenance and updates. It provides a single point of control for managing access and usage patterns.
This approach also allows for easier implementation of future features and security enhancements.
Rate Limiting Implementation
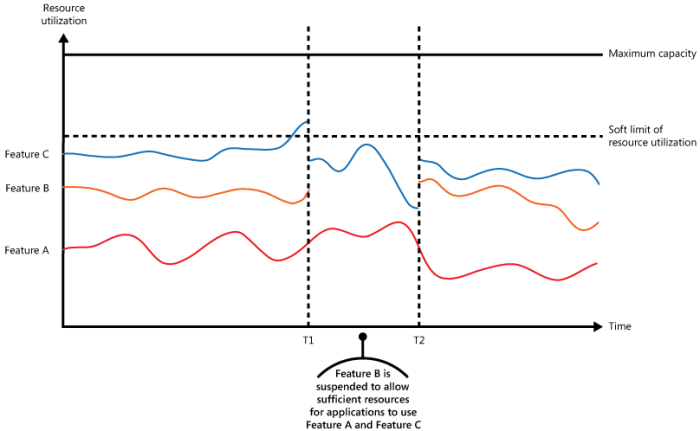
Rate limiting is a crucial mechanism for managing API traffic. It prevents abuse and ensures fair access to the API. Rate limiting mechanisms can be implemented at the API gateway level, enabling administrators to define acceptable request frequencies for various clients or API endpoints. This approach is vital in preventing denial-of-service attacks and ensuring consistent service quality for legitimate users.
Rate limits can be based on various criteria, such as IP address, user ID, or specific API endpoints. Implementing appropriate rate limits can protect against malicious attacks and ensure that the API is accessible to all authorized users.
Load Balancing Algorithms Comparison
Various load balancing algorithms exist, each with its strengths and weaknesses. Choosing the right algorithm depends on specific application requirements and anticipated traffic patterns. A comparison table Artikels common algorithms and their characteristics:
| Algorithm | Description | Strengths | Weaknesses |
|---|---|---|---|
| Round Robin | Distributes requests sequentially to available servers. | Simple to implement, fair distribution. | Doesn’t consider server load, can lead to uneven distribution if some servers are overloaded. |
| Least Connections | Sends requests to the server with the fewest active connections. | Optimizes server load, prevents overload on busy servers. | Requires tracking connection counts, might not be suitable for very high-traffic situations. |
| Weighted Round Robin | Distributes requests proportionally based on server capacity or weight. | Allows prioritizing servers based on their capabilities. | Requires careful weight assignment, might not be as fair as Least Connections if weights are not carefully considered. |
| IP Hashing | Maps client IP addresses to specific servers. | Maintains consistent routing for a client to the same server. | Doesn’t distribute load well if clients are not evenly distributed across servers. |
Different algorithms have different trade-offs. The best choice for a particular application depends on the specific needs, including traffic patterns, server capacity, and desired level of fairness. Consider factors such as expected traffic volume, server responsiveness, and potential overload scenarios when selecting a load balancing algorithm.
API Versioning and Evolution
API versioning is crucial for managing evolving APIs while maintaining backward compatibility. Proper versioning strategies allow developers to introduce new features and functionalities without breaking existing applications that rely on older versions. This section will delve into effective versioning strategies, backward compatibility techniques, and designing APIs for future scalability and change.
Strategies for Managing API Versioning
Effective API versioning is essential for handling evolving APIs. Different strategies cater to various needs, each with its own advantages and disadvantages. The most common strategies involve incorporating version numbers directly into the API endpoint URLs. These methods are often combined with other strategies to ensure proper version handling.
- URL-based versioning: This strategy involves including the API version as part of the URL. For example, `/v1/users` for version 1 and `/v2/users` for version 2. This approach clearly identifies the API version, enabling clients to target specific versions.
- Header-based versioning: This method uses an HTTP header (e.g., `X-API-Version`) to specify the API version. This approach provides more flexibility, as it doesn’t require modifying the URL structure. Clients can use this approach with various versions in parallel, if needed.
- Prefix-based versioning: In this strategy, the API version is embedded as a prefix in the endpoint path, such as `v1/users/profile`. This is less common than URL-based, but maintains clear version separation.
Handling Backward Compatibility When Evolving APIs
Maintaining backward compatibility is essential for maintaining existing client applications. When introducing new features, developers need to ensure that the API remains functional for clients using previous versions. This is particularly critical for long-lived APIs. Techniques like deprecation and gradual API evolution are employed.
- Deprecation: A deprecated API endpoint signifies its eventual removal. This allows developers to transition clients to the new version gradually while supporting older versions. Clear documentation about the deprecation process is vital for informing developers and reducing disruption.
- Gradual evolution: Instead of introducing a complete overhaul, APIs can be evolved incrementally. This means introducing new features while keeping older functionalities intact. This allows clients to adopt new features at their own pace.
Designing APIs for Future Growth and Changes
APIs should be designed to accommodate future growth and changes. This includes considering potential expansions in functionality and scalability needs. Using well-defined interfaces, and adhering to RESTful principles can facilitate these changes.
- Designing for extensibility: APIs should be built with future extensibility in mind. Consider using open standards, and designing components to be easily added or modified without impacting existing functionalities. This can be achieved through careful API design that anticipates potential growth areas.
- Using a well-defined interface: A well-defined interface makes it easier to add new features and functionalities without breaking existing integrations. This involves using clear naming conventions, well-defined parameters, and comprehensive documentation. This enables easier implementation and adaptation to changes.
Comparison of API Versioning Strategies
The table below compares common API versioning strategies, highlighting their strengths and weaknesses.
| Strategy | Description | Pros | Cons |
|---|---|---|---|
| URL-based | Version number embedded in URL | Clear version separation, easy identification | URL structure can become complex with multiple versions |
| Header-based | Version number in HTTP header | Flexible, doesn’t require URL modification, can support multiple versions concurrently | Requires clients to parse headers, might not be as immediately obvious as URL-based |
| Prefix-based | Version prefix embedded in endpoint path | Clear version separation, maintains a manageable URL structure | Less flexible than header-based, potentially less obvious than URL-based |
Monitoring and Performance Optimization
Effective API monitoring and optimization are crucial for ensuring consistent performance, high availability, and a positive user experience. Robust monitoring systems allow proactive identification of potential bottlenecks, enabling timely adjustments to maintain optimal API responsiveness. This proactive approach is vital for preventing service disruptions and ensuring the API remains a reliable source of data for its consumers.
API Performance Monitoring Techniques
Monitoring API performance involves a multi-faceted approach. Key techniques include continuous monitoring of response times, error rates, and request volume. Tools and technologies, such as application performance monitoring (APM) platforms, provide detailed insights into the internal workings of the API, identifying performance bottlenecks within the application’s code and infrastructure. These tools allow for real-time observation and analysis of API interactions.
Identifying Bottlenecks
Identifying performance bottlenecks within an API is essential for targeted optimization. Comprehensive logging and metrics, combined with detailed analysis of API usage patterns, offer insights into areas needing improvement. This analysis helps pinpoint the root causes of performance degradation, whether it stems from database queries, network latency, or inefficient code segments. This approach is pivotal for a comprehensive understanding of the API’s performance characteristics.
Analyzing API Usage Patterns
Analyzing API usage patterns provides valuable information for optimizing performance. Tools that capture and process API usage data can reveal trends, peak usage times, and common request patterns. This data enables informed decisions about resource allocation and infrastructure scaling. For instance, recognizing predictable surges in API traffic during specific times of day allows for proactive adjustments to handle increased load effectively.
Leveraging Logging and Metrics
Logging and metrics are indispensable for understanding and improving API performance. Detailed logs, including request and response times, error messages, and relevant contextual information, facilitate the identification of potential problems. Metrics, such as request throughput, error rates, and average response time, provide quantitative data for performance evaluation and trending analysis. This combined approach provides a comprehensive view of API health and performance.
Strategies for Resolving Performance Issues
Addressing performance issues requires a systematic approach. Once bottlenecks are identified, strategies such as code optimization, database query tuning, or infrastructure scaling can be implemented. For instance, if database queries are a performance bottleneck, optimizing database indexes or rewriting slow queries can significantly improve API performance. Proactive measures, like caching frequently accessed data, can also dramatically improve responsiveness.
Another approach involves load balancing and capacity planning, allowing the API to handle anticipated traffic loads effectively.
Security Considerations for Scalable APIs
Securing scalable APIs is paramount for protecting sensitive data and maintaining user trust. Robust security measures are crucial for preventing unauthorized access, data breaches, and other malicious activities, particularly in microservice architectures where multiple independent services interact. This section Artikels key security best practices for designing and implementing secure APIs.Implementing strong security protocols from the initial design phase is more cost-effective and less disruptive than addressing vulnerabilities later.
A proactive approach prevents security breaches and protects sensitive information throughout the API lifecycle, ensuring data integrity and availability.
Authentication Mechanisms
Effective authentication is the cornerstone of API security. It verifies the identity of users and services attempting to access the API. Implementing robust authentication mechanisms mitigates unauthorized access and protects the integrity of data. Common authentication methods include API keys, OAuth 2.0, and JWT (JSON Web Tokens). Each method offers varying levels of security and control, and the optimal choice depends on the specific API requirements and use case.
Authorization Strategies
Once a user’s identity is authenticated, authorization determines what resources they are permitted to access. Fine-grained authorization controls are essential for limiting access to sensitive data and preventing unauthorized actions. Role-based access control (RBAC) and attribute-based access control (ABAC) are common authorization strategies. RBAC defines roles with associated permissions, while ABAC leverages attributes to dynamically determine access rights.
These strategies ensure that only authorized users can access specific resources, protecting sensitive data and maintaining data integrity.
Input Validation and Sanitization
Preventing malicious input is critical to securing APIs. Input validation and sanitization techniques mitigate the risk of injection attacks, such as SQL injection and cross-site scripting (XSS). By validating input data against predefined rules and sanitizing potentially harmful characters, APIs can effectively prevent attackers from exploiting vulnerabilities. Input validation ensures that only expected data types and formats are processed, reducing the likelihood of unexpected behavior or security breaches.
Data Encryption
Encrypting sensitive data both in transit and at rest is vital to protect against unauthorized access and data breaches. Encryption safeguards confidential information, ensuring data integrity and confidentiality. HTTPS for communication and encryption of data stored in databases are crucial security measures. Using encryption ensures that data remains unreadable to unauthorized parties, protecting confidentiality.
Rate Limiting and Throttling
Rate limiting and throttling mechanisms protect APIs from denial-of-service (DoS) attacks. By limiting the number of requests an API can handle from a single source within a specific timeframe, APIs can prevent overload and maintain availability. Rate limiting and throttling strategies prevent abuse and maintain API performance and stability.
Security Considerations for Microservice APIs
Microservice architectures present unique security challenges. Each service within a microservice ecosystem needs to be secured individually, with consideration given to inter-service communication security. This involves implementing secure communication channels between services, managing authentication and authorization across the entire system, and ensuring that each service’s data is protected appropriately. Centralized authentication and authorization systems can help manage security across multiple microservices.
Using API gateways to manage incoming requests and enforce security policies across the entire system is another crucial aspect.
Comparison of Security Protocols for APIs
| Protocol | Description | Strengths | Weaknesses |
|---|---|---|---|
| HTTPS | Secure protocol for transferring data over the internet. | Provides encryption and authentication. | Requires client-side configuration. |
| OAuth 2.0 | Framework for authorization. | Provides secure authorization for third-party applications. | Requires complex implementation and understanding. |
| JSON Web Token (JWT) | Compact, self-contained way for securely transmitting information. | Lightweight and easy to implement. | Vulnerable to tampering if not properly secured. |
| API Keys | Unique identifier for API clients. | Simple to implement. | Less secure than other methods. |
Case Studies and Examples
Real-world implementations of scalable API architectures offer valuable insights into successful design principles and the impact of various design patterns. Analyzing these case studies provides practical guidance for developers aiming to create robust and performant APIs. Understanding how existing systems handle scalability challenges helps anticipate and address similar issues in new projects.Examining successful implementations allows us to identify common themes and best practices in API design.
This exploration goes beyond theoretical concepts, demonstrating how these principles translate into practical solutions and providing concrete examples of their impact on scalability.
Examples of Scalable API Architectures
Several prominent companies leverage scalable API architectures to power their applications. Netflix, for instance, employs a complex microservices architecture to handle the massive volume of user requests for streaming content. Their system relies on sophisticated load balancing and caching mechanisms to ensure high availability and responsiveness. Similarly, Twitter uses a distributed system with multiple data centers and a robust API gateway to manage the massive influx of tweets and user interactions.
These real-world examples highlight the critical need for efficient data storage and retrieval strategies to support high-volume transactions.
Successful Implementations of API Design Principles
Many successful API implementations demonstrate effective application of key design principles. These principles include clear API documentation, well-defined resource models, and efficient communication protocols. The use of API versioning allows for incremental updates without disrupting existing clients, while appropriate error handling mechanisms contribute to a reliable user experience. Implementing these principles leads to an API that is easy to use, understand, and maintain, facilitating scalability.
Specific Design Patterns and Their Impact on Scalability
Specific design patterns, such as the RESTful API design pattern, can significantly impact API scalability. RESTful APIs, with their emphasis on statelessness and resource-oriented architecture, enable horizontal scaling by distributing requests across multiple servers. The use of caching, another important pattern, can drastically reduce database load and improve response times for frequently accessed data. These design patterns contribute to a scalable architecture by addressing the challenges of handling increasing volumes of requests and data.
Comparison of API Design Examples and Their Performance
| API Design Example | Scalability Approach | Performance Metrics (Hypothetical) |
|---|---|---|
| Netflix Streaming API | Microservices, distributed caching, sophisticated load balancing | High throughput, low latency, excellent availability |
| Twitter API | Distributed system, robust API gateway, multiple data centers | High throughput, low latency, excellent availability |
| E-commerce Platform API | RESTful design, message queues, distributed databases | High throughput, acceptable latency, good availability |
| Social Media Platform API | Microservices, asynchronous communication, caching | High throughput, acceptable latency, good availability |
Performance metrics are hypothetical and may vary based on specific implementation details and usage patterns.
The table above provides a simplified comparison of various API design examples. Actual performance depends on factors such as the specific implementation, load patterns, and chosen technologies. The presented data highlights the general trends in scalability approaches and the associated performance outcomes.
Final Conclusion
In conclusion, designing a scalable API architecture is a multifaceted process encompassing design principles, architectural patterns, and practical implementation strategies. This comprehensive guide has covered the key elements necessary to create a robust and efficient API. By understanding and applying the principles discussed, developers can confidently build APIs capable of handling future growth and user demand.
Top FAQs
What are the key performance indicators (KPIs) for measuring API scalability?
Key performance indicators for measuring API scalability include request latency, throughput, error rates, and resource utilization. Monitoring these metrics helps identify potential bottlenecks and optimize performance.
How do you handle unexpected surges in API traffic?
Strategies for handling unexpected surges include load balancing, caching, and rate limiting. Load balancing distributes traffic across multiple servers, caching reduces database load, and rate limiting prevents abuse and overload.
What are some common pitfalls in designing a scalable API?
Common pitfalls include neglecting proper API versioning, inadequate security measures, and insufficient monitoring. Addressing these issues proactively is critical for a successful scalable API design.
What are the different types of database technologies suitable for scalable APIs?
Various database technologies, such as relational databases (MySQL, PostgreSQL), NoSQL databases (MongoDB, Cassandra), and cloud-based databases, are suitable for scalable APIs. Choosing the right technology depends on the specific needs of the application and data model.