The evolution of web application development has led to the emergence of serverless architecture, a paradigm shift that promises to simplify backend management and optimize resource utilization. Serverless computing allows developers to focus on writing code without the overhead of managing servers, resulting in reduced operational costs and faster deployment cycles. This approach leverages cloud provider services, such as compute functions, storage, and databases, to create scalable and resilient web applications.
This document will provide a comprehensive exploration of how to build a serverless web application backend, covering the key aspects from selecting a cloud provider and designing the architecture to implementing authentication, deployment, and monitoring. We will delve into the essential components, including API gateways, serverless functions, databases, and storage solutions. Furthermore, we will examine the benefits, challenges, and best practices associated with serverless development, providing practical guidance and code examples to enable readers to build efficient and scalable backend systems.
Introduction to Serverless Architecture
Serverless architecture represents a significant shift in how web application backends are designed and deployed. It moves away from the traditional model of managing and provisioning servers, instead focusing on code execution without server management. This approach allows developers to concentrate on writing code and building features, reducing operational overhead and potentially lowering costs.
Core Principles of Serverless Computing
The core principles of serverless computing revolve around the following key concepts:
- Function as a Service (FaaS): This is the fundamental building block of serverless. FaaS allows developers to execute individual functions in response to events. These functions are typically short-lived, stateless, and designed to perform a specific task. Examples include processing data, responding to API requests, or triggering other services.
- Event-Driven Architecture: Serverless architectures are inherently event-driven. Functions are triggered by events, such as HTTP requests, database updates, file uploads, or scheduled tasks. This asynchronous nature allows for scalability and responsiveness.
- Automatic Scaling: Serverless platforms automatically scale the resources allocated to functions based on demand. This means that as the number of requests increases, the platform automatically provisions more resources to handle the load, and conversely, scales down when demand decreases.
- Pay-per-Use Pricing: Serverless providers typically offer pay-per-use pricing models. Users are only charged for the actual compute time and resources consumed by their functions. This can result in significant cost savings compared to traditional server-based models, especially for applications with fluctuating workloads.
- No Server Management: The serverless provider handles all server management tasks, including provisioning, patching, and scaling. Developers do not need to worry about these operational aspects, freeing them to focus on code.
Benefits of Serverless for Web Application Backends
Serverless architecture provides several advantages for building web application backends:
- Reduced Operational Overhead: Developers do not need to manage servers, operating systems, or infrastructure, which simplifies operations and reduces the need for specialized IT staff.
- Scalability and Elasticity: Serverless platforms automatically scale resources based on demand, ensuring that applications can handle fluctuating workloads without manual intervention. This inherent elasticity is a key advantage.
- Cost Efficiency: Pay-per-use pricing models can lead to significant cost savings, especially for applications with variable traffic patterns. Costs are only incurred for the actual compute time and resources used.
- Faster Development Cycles: Developers can focus on writing code and building features, rather than managing infrastructure. This accelerates development cycles and allows for quicker time-to-market.
- Improved Reliability and Availability: Serverless platforms are designed for high availability and fault tolerance. Functions are typically executed across multiple availability zones, ensuring that applications remain available even if one zone experiences an outage.
- Simplified Deployment: Serverless platforms often provide streamlined deployment processes, making it easier to deploy and update applications.
Common Use Cases Where Serverless Architecture Excels
Serverless architecture is well-suited for a variety of web application backend use cases:
- Web and Mobile Backends: Serverless is ideal for building the backend for web and mobile applications, handling API requests, data storage, and user authentication. For example, a social media platform might use serverless functions to process user posts, generate thumbnails, and send notifications.
- API Development: Serverless functions can be used to create and manage APIs, handling requests and responses. This is a common use case, enabling developers to build RESTful APIs quickly and efficiently.
- Data Processing and Transformation: Serverless functions can be triggered by events, such as file uploads or database updates, to process and transform data. For example, a serverless function could be used to resize images uploaded to a cloud storage service.
- Real-time Applications: Serverless can be used to build real-time applications, such as chat applications or live dashboards, using services like WebSockets and serverless functions.
- IoT Backends: Serverless is well-suited for handling data from IoT devices, processing sensor data, and triggering actions. For example, a smart home system might use serverless functions to process data from temperature sensors and control appliances.
- Batch Processing: Serverless functions can be used to perform batch processing tasks, such as generating reports or sending emails, triggered by scheduled events.
Choosing a Cloud Provider
Selecting the right cloud provider is a critical decision when building a serverless backend. This choice impacts cost, scalability, feature availability, and operational complexity. Careful consideration of each provider’s offerings, pricing models, and ecosystem is essential for a successful serverless implementation. The leading providers offer robust serverless services, but their strengths and weaknesses vary, necessitating a thorough evaluation based on specific project requirements.
Identifying Leading Cloud Providers
Several cloud providers have emerged as leaders in the serverless computing space, each offering a comprehensive suite of services designed to facilitate the development and deployment of serverless applications. These providers continually innovate, introducing new features and services to remain competitive. Understanding the core offerings of these providers is the first step in the selection process.
Comparing Serverless Offerings
Each cloud provider offers a range of serverless services, including compute, storage, and database options. These services are often interconnected, enabling developers to build complex applications with minimal infrastructure management. The following table provides a comparative overview of the key serverless services offered by the leading providers:
| Provider | Compute Service | Storage Service | Database Service |
|---|---|---|---|
| AWS | AWS Lambda (Function-as-a-Service), AWS Fargate (Serverless Containers), AWS App Runner (Container Deployment) | Amazon S3 (Object Storage), Amazon EFS (Elastic File System), Amazon EBS (Elastic Block Storage – serverless integration available) | Amazon DynamoDB (NoSQL), Amazon Aurora Serverless (Relational), Amazon RDS Proxy (Database Connection Pooling) |
| Azure | Azure Functions (Function-as-a-Service), Azure Container Instances (Serverless Containers), Azure Web Apps (Web App Hosting) | Azure Blob Storage (Object Storage), Azure Files (File Share), Azure Disk Storage (Block Storage – serverless integration available) | Azure Cosmos DB (NoSQL), Azure SQL Database serverless (Relational), Azure Database for PostgreSQL serverless (Relational) |
| Google Cloud | Cloud Functions (Function-as-a-Service), Cloud Run (Serverless Containers), App Engine (Platform-as-a-Service) | Cloud Storage (Object Storage), Cloud Filestore (File Share), Persistent Disk (Block Storage – serverless integration available) | Cloud Firestore (NoSQL), Cloud SQL (Relational), Cloud Spanner (Globally Distributed, Scalable) |
The choice of compute service depends on the application’s requirements. For example, AWS Lambda, Azure Functions, and Google Cloud Functions are all Function-as-a-Service (FaaS) offerings, allowing developers to execute code without managing servers. Serverless container options, like AWS Fargate, Azure Container Instances, and Cloud Run, offer a different approach, allowing developers to deploy containerized applications without managing the underlying infrastructure.
Storage services vary in their characteristics, with object storage being a common choice for storing large amounts of unstructured data. Database options include both NoSQL and relational databases, each with its own strengths and weaknesses depending on the application’s data model and performance needs.
Detailing Pricing Models
Each cloud provider employs different pricing models for its serverless services. Understanding these models is crucial for estimating costs and optimizing spending. These models typically involve pay-per-use pricing, where users are charged only for the resources they consume. However, the specific metrics used for billing, such as execution time, requests, and storage used, can vary.AWS Lambda’s pricing is based on the number of requests and the duration of the code execution.
The first 1 million requests per month are free, and then a price per million requests applies. Execution time is measured in milliseconds, and the price per millisecond depends on the memory allocated to the function. Amazon S3, the object storage service, charges for storage used, requests made, and data transfer.Azure Functions pricing is based on the number of executions and the resources consumed, such as memory and CPU.
A free tier is available, and then a pay-as-you-go model applies. Azure Blob Storage charges for storage, transactions, and data transfer.Google Cloud Functions pricing is based on the number of invocations, the execution time, and the resources consumed, such as memory and CPU. Google Cloud Storage charges for storage, operations, and network egress. Google offers a free tier with some limits on these services.The pricing models of serverless databases, such as Amazon DynamoDB, Azure Cosmos DB, and Cloud Firestore, are also pay-per-use.
They typically charge for provisioned throughput, storage used, and read/write operations. For example, with DynamoDB, you pay for the read capacity units (RCUs) and write capacity units (WCUs) provisioned for your tables. In Azure Cosmos DB, pricing is based on request units (RUs), storage, and data transfer. In Cloud Firestore, you pay for storage, read/write operations, and network egress.
Backend Component Selection
The selection of backend components is a critical step in designing a serverless web application. This process involves choosing services that align with the application’s functional requirements, performance needs, and cost considerations. The choice of components significantly impacts the scalability, maintainability, and overall efficiency of the application. The following sections detail the architecture for a simple to-do list application, outlining the specific components and their interactions.
Backend Architecture for a To-Do List Application
The architecture for a to-do list application will be designed to handle user authentication, task creation, retrieval, updating, and deletion. The architecture leverages serverless services to achieve scalability, cost-effectiveness, and reduced operational overhead.
- API Gateway: This component acts as the entry point for all client requests. It manages routing, request authentication, and authorization. The API Gateway exposes RESTful APIs for the to-do list application, allowing the frontend to interact with the backend services.
- Compute Functions (e.g., AWS Lambda): These functions execute the business logic of the application. Separate functions will be created for each API endpoint, such as creating a new to-do item, retrieving all items, updating an item, and deleting an item. These functions are triggered by the API Gateway and interact with the database to persist and retrieve data.
- Database (e.g., DynamoDB): A NoSQL database is used to store the to-do list items. DynamoDB is chosen for its scalability, performance, and cost-effectiveness. Each to-do item will be stored as a document, with attributes such as item ID, user ID, task description, due date, and completion status.
- Storage (e.g., S3): This is not strictly necessary for a simple to-do list, but it is included to illustrate the use of storage. If the application were to include file uploads (e.g., images associated with to-do items), S3 would be used to store these files. In this case, it is not used.
The data flow within this architecture is as follows:
- The client (e.g., a web browser) sends an HTTP request to the API Gateway.
- The API Gateway routes the request to the appropriate compute function based on the API endpoint.
- The compute function executes the business logic (e.g., creating, reading, updating, or deleting a to-do item).
- The compute function interacts with the DynamoDB database to read or write data.
- The compute function returns a response to the API Gateway.
- The API Gateway forwards the response to the client.
The following diagram illustrates the data flow.
Diagram Description: The diagram depicts the flow of data through the serverless architecture of the to-do list application. At the top is the client, which is a web browser. It communicates with the API Gateway via HTTP requests. The API Gateway routes the requests to AWS Lambda functions.
These Lambda functions are responsible for the core logic, such as handling requests for adding, viewing, modifying, and deleting tasks. The Lambda functions then interact with the DynamoDB database to store and retrieve the data for the to-do items. The arrows indicate the direction of the data flow. The diagram shows the request and response cycles between the client, API Gateway, Lambda functions, and DynamoDB.
This architecture is designed for high availability, scalability, and cost-effectiveness.
Setting up an API Gateway
API Gateways are crucial components in serverless architectures, acting as the single entry point for client applications to interact with the backend services. They handle tasks like routing requests, authentication, authorization, request transformation, and response formatting. Properly configuring an API Gateway is paramount to ensuring the security, scalability, and manageability of the serverless application. This section will detail the setup and configuration of an API Gateway, providing concrete examples using JSON formats.
Configuring an API Gateway
Configuring an API Gateway involves several key steps, regardless of the cloud provider chosen. These steps ensure proper routing, security, and data transformation.
- Choosing a Cloud Provider’s API Gateway: Selecting the appropriate API Gateway service is the initial step. AWS offers API Gateway, Azure provides Azure API Management, and Google Cloud has Google Cloud API Gateway. Each service offers similar functionalities but may have differences in pricing, feature sets, and integration with other cloud services. The choice should align with the chosen cloud provider and the specific requirements of the application.
- Defining API Endpoints: Endpoints represent the specific URLs that clients use to access backend functionality. They are defined within the API Gateway, specifying the HTTP method (GET, POST, PUT, DELETE, etc.), the URL path (e.g., /users, /products/id), and the integration with the backend service (e.g., a Lambda function, an Azure Function, or a Google Cloud Function).
- Defining Methods: Methods are the HTTP verbs (GET, POST, PUT, DELETE, etc.) that define the type of operation being performed on a resource. Each method is associated with an endpoint and specifies how the API Gateway should handle requests with that method. For example, a GET method might be used to retrieve data, while a POST method might be used to create data.
- Setting up Request/Response Formats: The API Gateway handles the translation between the client’s request format and the backend service’s expected format. This often involves transforming JSON payloads, handling query parameters, and setting headers. The response format is also defined to ensure the client receives the data in a usable format.
- Implementing Authentication and Authorization: API Gateways provide mechanisms for securing the API. This typically involves authenticating users (verifying their identity) and authorizing them (determining their access rights). Authentication can be achieved using API keys, OAuth, JWT (JSON Web Tokens), or other methods. Authorization policies control which users or roles can access specific API endpoints.
- Implementing Monitoring and Logging: Integrating monitoring and logging is essential for tracking API usage, identifying errors, and troubleshooting issues. API Gateways provide tools for logging requests and responses, as well as metrics on performance, latency, and error rates. These insights are crucial for optimizing the API and ensuring its reliability.
Defining API Endpoints, Methods, and Formats
API Gateways rely on a structured approach to manage API interactions. This includes defining endpoints, methods, and the associated request/response formats.
- Endpoint Definition: An endpoint is a specific URL that clients use to access a particular function or resource within the backend. For instance, to retrieve a user’s information, the endpoint might be `/users/userId`. The `userId` is a path parameter, and the API Gateway is responsible for extracting and passing this parameter to the backend service.
- Method Definition: Methods define the HTTP verb used for a particular operation. For example:
- GET: Retrieves data from the backend.
- POST: Creates new data on the backend.
- PUT: Updates existing data on the backend.
- DELETE: Removes data from the backend.
- Request Format: The request format defines the structure of the data sent by the client to the API Gateway. This often involves JSON payloads, query parameters, and headers. The API Gateway may need to transform the request format before forwarding it to the backend service. For instance, if a client sends a request with a JSON payload containing user details, the API Gateway might need to transform this payload to match the format expected by a Lambda function.
- Response Format: The response format defines the structure of the data returned by the API Gateway to the client. This typically involves JSON payloads, HTTP status codes, and headers. The API Gateway may need to transform the response format from the backend service to meet the client’s requirements. For example, a backend service might return data in a specific format, and the API Gateway might need to transform it to a more client-friendly format.
Example: Request and Response Payloads in JSON Format
The use of JSON (JavaScript Object Notation) for request and response payloads is a common practice. This allows for a standardized and easily parsable data exchange between the client and the server.
- Example: GET Request and Response (Retrieving a User)
Assume an API endpoint `/users/userId` with a GET method is used to retrieve user information.
- Request (No payload for GET): The client sends a GET request to `/users/123`. The `123` is the `userId` parameter.
- Response (JSON Payload): The API Gateway receives the response from the backend (e.g., a Lambda function) and returns the user data in JSON format:
"userId": 123, "username": "johndoe", "email": "[email protected]"
- Example: POST Request and Response (Creating a User)
Assume an API endpoint `/users` with a POST method is used to create a new user.
- Request (JSON Payload): The client sends a POST request to `/users` with a JSON payload containing the user details:
"username": "janedoe", "email": "[email protected]" - Response (JSON Payload and HTTP Status Code): The API Gateway receives the response from the backend (e.g., a Lambda function) and returns a success status code (e.g., 201 Created) along with a JSON payload containing the newly created user’s information:
"userId": 456, "username": "janedoe", "email": "[email protected]"
- Request (JSON Payload): The client sends a POST request to `/users` with a JSON payload containing the user details:
- Example: PUT Request and Response (Updating a User)
Assume an API endpoint `/users/userId` with a PUT method is used to update an existing user.
- Request (JSON Payload): The client sends a PUT request to `/users/456` with a JSON payload containing the updated user details:
"username": "jane.doe.updated", "email": "[email protected]" - Response (JSON Payload and HTTP Status Code): The API Gateway receives the response from the backend (e.g., a Lambda function) and returns a success status code (e.g., 200 OK) along with a JSON payload containing the updated user’s information:
"userId": 456, "username": "jane.doe.updated", "email": "[email protected]"
- Request (JSON Payload): The client sends a PUT request to `/users/456` with a JSON payload containing the updated user details:
- Example: DELETE Request and Response (Deleting a User)
Assume an API endpoint `/users/userId` with a DELETE method is used to delete a user.
- Request (No Payload): The client sends a DELETE request to `/users/456`.
- Response (HTTP Status Code): The API Gateway receives the response from the backend (e.g., a Lambda function) and returns a success status code (e.g., 204 No Content) if the user was successfully deleted. No payload is typically returned in this case.
Developing Serverless Functions
Serverless functions are the core building blocks of a serverless backend. They execute specific pieces of code in response to triggers, such as HTTP requests, database updates, or scheduled events. The development process involves writing code, configuring the execution environment, and deploying the functions to a cloud provider. The choice of programming language, handling requests, managing dependencies, and utilizing environment variables are critical aspects of function development.
Programming Language Selection
The choice of programming language for serverless functions depends on several factors, including existing expertise, performance requirements, and the ecosystem of available libraries and frameworks. Cloud providers typically support a range of languages.
- Node.js: Node.js, built on the V8 JavaScript engine, is widely used due to its asynchronous, event-driven architecture, making it well-suited for handling concurrent requests. Its non-blocking I/O operations are advantageous in serverless environments where functions are often invoked in response to multiple events. The npm (Node Package Manager) ecosystem provides access to a vast collection of readily available packages, which accelerate development.
A simple Node.js function might involve processing data from an HTTP request:
“`javascript
exports.handler = async (event) =>
const requestBody = JSON.parse(event.body);
const message = `Hello, $requestBody.name!`;
return
statusCode: 200,
body: JSON.stringify( message: message ),
;
;
“` - Python: Python’s readability and extensive library support make it a popular choice. Python is particularly strong in data science, machine learning, and scientific computing, enabling the rapid development of serverless functions for tasks like data processing and analysis. The `requests` library, for example, simplifies making HTTP requests.
“`python
import json
def handler(event, context):
body = json.loads(event[‘body’])
name = body[‘name’]
message = f”Hello, name!”
return
‘statusCode’: 200,
‘body’: json.dumps(‘message’: message)“`
- Java: Java’s robustness and performance, especially in enterprise environments, make it suitable for serverless applications requiring high throughput and reliability. Frameworks like Spring Boot facilitate the development of Java-based serverless functions. The Java Virtual Machine (JVM) provides excellent runtime optimization.
“`java
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import com.google.gson.Gson;
import java.util.HashMap;
import java.util.Map;public class HelloHandler implements RequestHandler
return response;
“`
- Go: Go’s speed and efficiency make it a strong choice for serverless functions, particularly for tasks requiring high performance and low latency. Its concurrency features, such as goroutines and channels, allow for the efficient handling of multiple requests. Go’s static typing enhances code reliability.
“`go
package mainimport (
“encoding/json”
“fmt”
“github.com/aws/aws-lambda-go/events”
“github.com/aws/aws-lambda-go/lambda”
)type RequestBody struct
Name string `json:”name”`func Handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error)
var requestBody RequestBody
err := json.Unmarshal([]byte(request.Body), &requestBody)
if err != nil
return events.APIGatewayProxyResponseStatusCode: 400, Body: fmt.Sprintf(“Error parsing request body: %v”, err), nilmessage := fmt.Sprintf(“Hello, %s!”, requestBody.Name)
response := events.APIGatewayProxyResponse
StatusCode: 200,
Headers: map[string]string”Content-Type”: “application/json”,
Body: fmt.Sprintf(`”message”: “%s”`, message),return response, nil
func main()
lambda.Start(Handler)“`
Handling Incoming Requests and Data Processing
Serverless functions receive input through various triggers, the most common being HTTP requests. The structure of these requests, including headers, body, and query parameters, needs to be parsed and processed within the function. Data processing involves manipulating the received data, performing calculations, interacting with other services, and generating a response.
- Request Parsing: Functions must parse incoming requests to extract the necessary information. The method used depends on the request’s content type (e.g., JSON, form data).
For example, if the incoming request body is in JSON format, the function must parse the JSON string into a usable data structure. This is done using libraries such as `JSON.parse()` in JavaScript or the `json` module in Python.
- Data Validation: Data validation is critical for ensuring data integrity and security. Functions should validate the data received from requests against predefined rules. This can involve checking data types, required fields, and acceptable ranges.
For example, a function processing user input might validate that an email address conforms to a valid format.
- Business Logic Implementation: This involves the core operations that the function is designed to perform. This may include database interactions, calculations, or calls to other services.
For instance, a function could retrieve user data from a database, perform calculations based on that data, and then return the results in the response.
- Response Generation: The function must construct a response that is returned to the client. This typically involves setting the appropriate HTTP status code and formatting the response body, often in JSON format.
The response structure must conform to the requirements of the API Gateway or trigger that initiated the function.
Environment Variables and Dependencies
Environment variables and dependencies are essential for configuring and extending the functionality of serverless functions.
- Environment Variables: Environment variables provide a mechanism to configure the function’s behavior without modifying the code. They store configuration parameters such as API keys, database connection strings, and feature flags.
Using environment variables allows developers to change the behavior of the function without redeploying the code. For example, a database connection string can be stored in an environment variable, allowing the function to connect to different databases in different environments (development, staging, production).
- Dependency Management: Dependencies are external libraries or packages that the function relies on to perform its tasks. These are managed through package managers such as npm for Node.js, pip for Python, and Maven or Gradle for Java.
For example, a function that interacts with a database would depend on a database driver library. The cloud provider typically handles the deployment and management of these dependencies, allowing the function to access the necessary libraries during runtime.
- Security Considerations: Environment variables are also used to store sensitive information such as API keys and database passwords. It is important to secure these variables, ensuring they are not exposed in the code or in public repositories. Cloud providers offer features like secret management to protect sensitive data.
For example, the AWS Secrets Manager allows you to store and manage secrets securely, and the function can retrieve them during execution.
Database Integration
Serverless applications necessitate robust database integration to store and retrieve data. The selection of the appropriate database technology and the implementation of efficient access strategies are critical for performance, scalability, and cost-effectiveness. This section details the methods for connecting serverless functions to databases, focusing on best practices for database access, security, and CRUD operations.
Methods for Connecting Serverless Functions to Databases
Connecting serverless functions to databases involves several approaches, each with its own advantages and disadvantages depending on the database type and cloud provider. Understanding these methods is crucial for making informed decisions regarding architecture and implementation.
- Direct Database Connections: This method involves establishing a direct connection between the serverless function and the database. For relational databases, this typically involves using a database driver (e.g., JDBC for Java, psycopg2 for Python) within the function code. For NoSQL databases, client libraries provided by the database vendor are used.
- Database Proxies: Database proxies act as intermediaries between serverless functions and the database. They can provide connection pooling, caching, and security features. Examples include AWS RDS Proxy for relational databases and managed database services offered by cloud providers.
- Serverless Database Connectors: Some cloud providers offer serverless connectors that simplify database access. These connectors often handle connection management, security, and scaling automatically. For instance, AWS Lambda layers can include database drivers or client libraries, simplifying deployment and dependency management.
- Event-Driven Architectures: In certain scenarios, a direct connection is not necessary. Data can be written to a database via events. For example, a serverless function might publish messages to a message queue (e.g., AWS SQS, Azure Service Bus), which are then consumed by another service that updates the database.
Best Practices for Database Access
Implementing best practices for database access is crucial for optimizing performance, security, and cost. These practices help mitigate common issues like connection exhaustion and unauthorized access.
- Connection Pooling: Connection pooling is a technique where a pool of database connections is maintained and reused. This reduces the overhead of establishing new connections for each function invocation, significantly improving performance. Libraries like HikariCP (Java) or SQLAlchemy (Python) provide connection pooling capabilities.
- Security Best Practices:
- Least Privilege Principle: Grant serverless functions only the necessary permissions to access the database. Avoid using overly permissive credentials.
- Secrets Management: Store database credentials securely using a secrets management service (e.g., AWS Secrets Manager, Azure Key Vault). Do not hardcode credentials in the function code.
- Input Validation: Validate all user inputs to prevent SQL injection and other security vulnerabilities. Use parameterized queries or prepared statements to safely construct database queries.
- Encryption: Encrypt data both in transit (using TLS/SSL) and at rest (using database-provided encryption features).
- Idempotent Operations: Design functions to be idempotent, meaning they can be executed multiple times without causing unintended side effects. This is particularly important in serverless environments where function invocations can be retried.
- Error Handling and Retries: Implement robust error handling and retry mechanisms to handle transient database errors (e.g., connection timeouts). Use exponential backoff strategies to avoid overwhelming the database.
- Monitoring and Logging: Implement comprehensive monitoring and logging to track database performance, identify errors, and troubleshoot issues. Use metrics to monitor connection pool usage, query execution times, and database resource utilization.
CRUD Operations Code Examples
CRUD (Create, Read, Update, Delete) operations are fundamental to most database interactions. The following code examples demonstrate how to perform these operations on a sample database table using Python and a hypothetical NoSQL database and a relational database.
NoSQL Database (e.g., DynamoDB – AWS) Example:
This example assumes you have configured the necessary AWS credentials and have a DynamoDB table named “users” with a primary key “userId”.
Python Example (using Boto3):
import boto3import jsondynamodb = boto3.resource('dynamodb')table = dynamodb.Table('users')def create_user(user_id, name, email): try: response = table.put_item( Item= 'userId': user_id, 'name': name, 'email': email ) return 'statusCode': 200, 'body': json.dumps('User created successfully!') except Exception as e: return 'statusCode': 500, 'body': json.dumps(f'Error creating user: str(e)') def get_user(user_id): try: response = table.get_item( Key= 'userId': user_id ) if 'Item' in response: return 'statusCode': 200, 'body': json.dumps(response['Item']) else: return 'statusCode': 404, 'body': json.dumps('User not found') except Exception as e: return 'statusCode': 500, 'body': json.dumps(f'Error getting user: str(e)') def update_user(user_id, new_email): try: response = table.update_item( Key= 'userId': user_id , UpdateExpression='SET email = :email', ExpressionAttributeValues= ':email': new_email ) return 'statusCode': 200, 'body': json.dumps('User updated successfully!') except Exception as e: return 'statusCode': 500, 'body': json.dumps(f'Error updating user: str(e)') def delete_user(user_id): try: response = table.delete_item( Key= 'userId': user_id ) return 'statusCode': 200, 'body': json.dumps('User deleted successfully!') except Exception as e: return 'statusCode': 500, 'body': json.dumps(f'Error deleting user: str(e)') Relational Database (e.g., PostgreSQL) Example:
This example assumes you have a PostgreSQL database with a table named “users” with columns “id” (INT, primary key), “name” (VARCHAR), and “email” (VARCHAR).
Python Example (using psycopg2):
import psycopg2import osimport json# Retrieve database credentials from environment variables (e.g., set in Lambda configuration)db_host = os.environ.get('DB_HOST')db_name = os.environ.get('DB_NAME')db_user = os.environ.get('DB_USER')db_password = os.environ.get('DB_PASSWORD')def get_db_connection(): try: conn = psycopg2.connect( host=db_host, database=db_name, user=db_user, password=db_password ) return conn except Exception as e: print(f"Error connecting to database: e") return Nonedef create_user(name, email): conn = get_db_connection() if not conn: return 'statusCode': 500, 'body': json.dumps('Failed to connect to the database') try: with conn.cursor() as cur: cur.execute("INSERT INTO users (name, email) VALUES (%s, %s) RETURNING id;", (name, email)) user_id = cur.fetchone()[0] # Retrieve the generated ID conn.commit() return 'statusCode': 200, 'body': json.dumps('message': 'User created successfully!', 'id': user_id) except Exception as e: conn.rollback() return 'statusCode': 500, 'body': json.dumps(f'Error creating user: str(e)') finally: conn.close()def get_user(user_id): conn = get_db_connection() if not conn: return 'statusCode': 500, 'body': json.dumps('Failed to connect to the database') try: with conn.cursor() as cur: cur.execute("SELECT id, name, email FROM users WHERE id = %s;", (user_id,)) user = cur.fetchone() if user: user_data = 'id': user[0], 'name': user[1], 'email': user[2] return 'statusCode': 200, 'body': json.dumps(user_data) else: return 'statusCode': 404, 'body': json.dumps('User not found') except Exception as e: return 'statusCode': 500, 'body': json.dumps(f'Error getting user: str(e)') finally: conn.close()def update_user(user_id, new_email): conn = get_db_connection() if not conn: return 'statusCode': 500, 'body': json.dumps('Failed to connect to the database') try: with conn.cursor() as cur: cur.execute("UPDATE users SET email = %s WHERE id = %s;", (new_email, user_id)) if cur.rowcount > 0: conn.commit() return 'statusCode': 200, 'body': json.dumps('User updated successfully!') else: return 'statusCode': 404, 'body': json.dumps('User not found') except Exception as e: conn.rollback() return 'statusCode': 500, 'body': json.dumps(f'Error updating user: str(e)') finally: conn.close()def delete_user(user_id): conn = get_db_connection() if not conn: return 'statusCode': 500, 'body': json.dumps('Failed to connect to the database') try: with conn.cursor() as cur: cur.execute("DELETE FROM users WHERE id = %s;", (user_id,)) if cur.rowcount > 0: conn.commit() return 'statusCode': 200, 'body': json.dumps('User deleted successfully!') else: return 'statusCode': 404, 'body': json.dumps('User not found') except Exception as e: conn.rollback() return 'statusCode': 500, 'body': json.dumps(f'Error deleting user: str(e)') finally: conn.close() Storage and File Handling
Serverless applications often need to manage files, such as images, documents, and videos.
Efficient storage and retrieval are crucial for a responsive user experience and data integrity. This section details how to leverage serverless storage services for these purposes, including secure access mechanisms and practical code examples.
Serverless Storage Services and File Operations
Serverless storage services, such as Amazon S3, Google Cloud Storage, and Azure Blob Storage, provide scalable and cost-effective solutions for storing files. These services are designed to handle massive amounts of data and offer high availability and durability.
- Uploading Files: Files can be uploaded to serverless storage using various methods, including direct uploads from the client-side (e.g., a web browser) or through serverless functions. Uploads often involve sending a file to a pre-signed URL or using an API key.
- Downloading Files: Files can be downloaded from serverless storage by providing the appropriate URL. This can be a public URL for publicly accessible files or a pre-signed URL for secure, time-limited access.
- File Organization: Serverless storage services allow for file organization using prefixes or folders. This structure helps manage and categorize files, enhancing retrieval efficiency and application maintainability.
- Metadata Management: Metadata can be associated with files, including information like file type, size, and creation date. This metadata is useful for file management, search, and data analysis.
Generating Pre-Signed URLs for Secure File Access
Pre-signed URLs are a critical feature for secure file access in serverless applications. They provide temporary access to files stored in serverless storage without requiring users to have direct credentials. This approach ensures that sensitive data remains protected.
- Purpose: Pre-signed URLs allow authorized users to access a file for a specified duration. This is achieved by generating a URL that includes the file’s location, access permissions (e.g., read, write), and an expiration timestamp.
- Mechanism: The process involves generating a signature using a secret key associated with the storage service. This signature is included in the URL, verifying the user’s authorization and preventing tampering.
- Benefits: Pre-signed URLs enhance security by limiting access to specific files for a defined time. This is particularly useful for handling sensitive information and preventing unauthorized access.
Code Examples: Uploading and Downloading Files with Serverless Functions
These code examples demonstrate how to upload and download files using serverless functions. The examples assume the use of a cloud provider like AWS, but the principles apply to other providers with minor modifications.
Uploading a File (AWS Lambda with Node.js and S3):
This function receives a file from the client, uploads it to an S3 bucket, and returns the file’s URL.
const AWS = require('aws-sdk');const s3 = new AWS.S3();exports.handler = async (event) => try const bucketName = 'your-bucket-name'; const fileName = event.fileName; // Assuming file name is passed in event const fileContent = Buffer.from(event.fileContent, 'base64'); // Assuming file content is base64 encoded const params = Bucket: bucketName, Key: fileName, Body: fileContent, ContentType: event.contentType, // e.g., 'image/jpeg' ACL: 'public-read' //Optional, for public access ; const uploadResult = await s3.upload(params).promise(); const fileUrl = uploadResult.Location; return statusCode: 200, body: JSON.stringify( fileUrl: fileUrl ), ; catch (error) console.error(error); return statusCode: 500, body: JSON.stringify( message: 'File upload failed' ), ; ;Downloading a File (AWS Lambda with Node.js and S3 – Using Pre-signed URL):
This function generates a pre-signed URL for a file, enabling temporary access for download.
const AWS = require('aws-sdk');const s3 = new AWS.S3();exports.handler = async (event) => try const bucketName = 'your-bucket-name'; const fileName = event.fileName; const params = Bucket: bucketName, Key: fileName, Expires: 60 // URL will expire in 60 seconds ; const url = await s3.getSignedUrlPromise('getObject', params); return statusCode: 200, body: JSON.stringify( downloadUrl: url ), ; catch (error) console.error(error); return statusCode: 500, body: JSON.stringify( message: 'Failed to generate pre-signed URL' ), ; ;Explanation of the Code Examples:
- Dependencies: The code uses the AWS SDK for JavaScript to interact with S3. Ensure the AWS SDK is included in your function’s dependencies.
- Configuration: The bucket name and file name are used to identify the storage location.
- Upload Process: The upload function takes the file content, file name, and content type as inputs. It uploads the file to the specified S3 bucket and returns the file’s public URL.
- Pre-signed URL Generation: The download function generates a pre-signed URL with a specified expiration time. This URL grants temporary access to the file.
- Error Handling: Both functions include error handling to provide informative responses.
Authentication and Authorization
Securing a serverless backend is paramount. Authentication verifies the identity of a user, while authorization determines what resources a user is permitted to access. This layered approach ensures data integrity and protects sensitive information. A robust authentication and authorization system is essential for building trustworthy and scalable serverless applications.
Designing a Secure Authentication System
A secure authentication system is built upon several key principles. These principles work together to protect user credentials and prevent unauthorized access to resources. Careful consideration of these factors is crucial for the overall security posture of the serverless backend.
- Password Storage: Never store passwords in plain text. Employ strong hashing algorithms, such as bcrypt or Argon2, with salting. Salting involves adding a unique, random string to each password before hashing. This prevents attackers from using precomputed rainbow tables to crack passwords. For instance, a password “password123” with a salt “u982jfd” would be hashed to a unique string that is then stored in the database.
This protects against dictionary attacks and brute-force attacks.
- Multi-Factor Authentication (MFA): Implement MFA wherever possible. This adds an extra layer of security by requiring users to provide a second form of verification, such as a code from an authenticator app or a one-time password (OTP) sent to their email or phone. This significantly reduces the risk of account compromise, even if the primary password is stolen.
- Regular Security Audits: Conduct regular security audits and penetration testing to identify and address vulnerabilities in the authentication system. This includes reviewing code, checking for common security flaws (e.g., SQL injection, cross-site scripting), and assessing the overall security configuration.
- Rate Limiting: Implement rate limiting to restrict the number of login attempts from a single IP address or user account within a specific timeframe. This mitigates brute-force attacks by slowing down the attacker’s ability to guess passwords. For example, limit login attempts to 5 per minute.
- Input Validation: Validate all user inputs to prevent common security vulnerabilities. This includes sanitizing inputs to prevent cross-site scripting (XSS) attacks and ensuring that data conforms to expected formats to prevent injection attacks.
Implementing User Registration, Login, and Token-Based Authentication (JWT)
Implementing user registration, login, and token-based authentication involves several key steps. The process ensures a secure and streamlined user experience. This approach is well-suited for serverless architectures due to its stateless nature.
- User Registration:
- Collect user credentials (username, email, password).
- Validate the input data. Ensure data conforms to requirements such as minimum password length, email format, and uniqueness of username/email.
- Hash the password using a strong hashing algorithm with a salt.
- Store the user’s information (username, email, hashed password, salt) in a database.
- Optionally, send a verification email to confirm the user’s email address.
- User Login:
- Receive user credentials (username/email, password).
- Retrieve the user’s information (hashed password and salt) from the database based on the username or email.
- Hash the entered password using the retrieved salt and compare it with the stored hashed password.
- If the passwords match, generate a JSON Web Token (JWT).
- Return the JWT to the client.
- Token-Based Authentication (JWT):
- The client includes the JWT in the “Authorization” header of subsequent requests (e.g., “Authorization: Bearer <token>”).
- The server verifies the JWT’s signature and checks its validity (e.g., expiration).
- If the JWT is valid, the server extracts the user’s identity (e.g., user ID) from the token’s payload.
- The server uses the user’s identity to authorize access to requested resources.
JWT Structure: A JWT typically consists of three parts: a header, a payload, and a signature, separated by periods (.). The header contains metadata about the token (e.g., the algorithm used). The payload contains claims (e.g., user ID, roles, expiration time). The signature verifies the integrity of the token.
Discussing the Importance of Authorization and Access Control
Authorization, distinct from authentication, dictates what actions a user can perform and what resources they can access. It is crucial for data security and maintaining the integrity of the application. Implementing robust authorization mechanisms is critical for a well-designed serverless backend.
- Role-Based Access Control (RBAC): Assign users to roles (e.g., “admin,” “editor,” “viewer”) and grant permissions to roles. This simplifies access management and ensures that users only have the necessary privileges.
- Attribute-Based Access Control (ABAC): Define access control rules based on attributes of the user, the resource, and the environment. This provides fine-grained control and flexibility. For instance, an ABAC rule might grant access to a document if the user’s department matches the document’s department attribute.
- Least Privilege Principle: Grant users only the minimum necessary permissions to perform their tasks. This limits the potential damage if an account is compromised.
- Access Control Lists (ACLs): Associate permissions with specific resources. This is common for managing file access, where each file can have its own set of permissions.
- Regular Auditing and Monitoring: Implement logging and monitoring to track access to resources and identify potential security breaches or unauthorized activity. Regularly review logs and audit trails to ensure the authorization system is functioning as intended.
Deployment and CI/CD
Deploying a serverless backend is a critical phase, transforming the developed code into a live, functional application. This involves packaging the code, configuring cloud resources, and managing the deployment process itself. Continuous integration and continuous deployment (CI/CD) streamlines this, automating builds, tests, and deployments, ensuring faster release cycles and reduced risk. Efficient deployment and CI/CD practices are paramount for maintaining a robust and scalable serverless architecture.
Steps for Deploying a Serverless Backend to the Cloud
The deployment process for a serverless backend involves several key steps. These steps ensure that the application is correctly configured, accessible, and functional within the cloud environment.
- Packaging the Code: The first step is to package the serverless functions, often alongside any required dependencies. This usually involves creating deployment packages or archives, such as ZIP files. These packages contain the code and any libraries needed for the functions to execute correctly in the cloud environment.
- Configuring Cloud Resources: Next, the necessary cloud resources, such as API gateways, databases, and storage buckets, must be configured. This often involves defining the infrastructure configuration within a cloud provider’s console or using infrastructure-as-code tools. Configuration includes setting up access permissions, defining API endpoints, and specifying resource limits.
- Deploying the Application: The application is then deployed to the cloud. This involves uploading the packaged code and configurations to the cloud provider. The cloud provider then provisions and manages the resources, ensuring the serverless functions are ready to handle incoming requests.
- Testing and Validation: After deployment, thorough testing is essential. This includes unit tests, integration tests, and end-to-end tests to verify the functionality and performance of the application. Monitoring tools are then used to validate that the application functions as intended.
- Monitoring and Logging: Finally, comprehensive monitoring and logging are implemented to track the application’s performance and identify any issues. This involves setting up monitoring dashboards, logging application events, and configuring alerts to respond to errors or performance degradations.
Setting Up Continuous Integration and Continuous Deployment (CI/CD) Pipelines
CI/CD pipelines automate the process of building, testing, and deploying code changes. This leads to faster release cycles and reduced manual effort. The setup typically involves defining a series of stages, each performing a specific task.
- Source Code Management: The process begins with a source code repository, such as Git, where the application code is stored. Each code change triggers the CI/CD pipeline.
- Build Stage: The build stage involves compiling the code, if necessary, and packaging it for deployment. This stage may also include dependency resolution and code analysis.
- Test Stage: Automated tests are executed to verify the functionality and quality of the code. This includes unit tests, integration tests, and potentially end-to-end tests. If the tests fail, the pipeline is typically stopped.
- Deployment Stage: Once the tests pass, the code is deployed to a staging or production environment. This involves updating the serverless functions and any associated resources.
- Monitoring and Rollback: After deployment, the application is monitored for performance and errors. If issues are detected, the pipeline can be configured to automatically roll back to a previous, stable version.
Using Infrastructure-as-Code (IaC) Tools for Automated Deployments
Infrastructure-as-Code (IaC) tools allow you to define and manage cloud infrastructure using code. This approach offers significant benefits, including automation, version control, and repeatability. Tools such as Terraform and AWS CloudFormation are widely used for automating deployments in serverless architectures.
Terraform: Terraform is a popular IaC tool that supports multiple cloud providers. It allows you to define infrastructure as code using a declarative language. Terraform automates the creation, modification, and deletion of cloud resources, such as API gateways, Lambda functions, and databases. It uses a state file to track the current infrastructure state, enabling efficient updates and preventing conflicts.
AWS CloudFormation: AWS CloudFormation is a service provided by Amazon Web Services. It allows you to define your infrastructure as code using YAML or JSON templates. CloudFormation manages the creation, updates, and deletion of AWS resources. It provides a single source of truth for your infrastructure, making it easy to manage and replicate. CloudFormation also offers features like change sets, which allow you to preview the changes before they are applied.
Benefits of IaC: IaC tools provide several benefits for serverless deployments:
- Automation: Automate the deployment process, reducing manual effort and the risk of human error.
- Version Control: Track infrastructure changes using version control systems, enabling collaboration and rollback capabilities.
- Repeatability: Replicate infrastructure across different environments (e.g., development, staging, production) consistently.
- Consistency: Ensure that infrastructure configurations are consistent across deployments.
Example: Consider a scenario where a developer needs to deploy a new version of a Lambda function and update the API Gateway configuration. Using IaC, the developer would modify the infrastructure code (e.g., a Terraform configuration file or a CloudFormation template) to reflect the changes. The IaC tool would then automatically create, update, or delete the necessary cloud resources to match the defined configuration.
This approach significantly simplifies the deployment process and reduces the potential for errors.
Monitoring and Logging

Monitoring and logging are crucial components of any serverless application, providing insights into its performance, health, and behavior. Effective monitoring enables proactive identification and resolution of issues, while comprehensive logging aids in debugging and understanding application workflows. Neglecting these aspects can lead to undetected errors, performance bottlenecks, and difficulties in troubleshooting production incidents.
Importance of Monitoring and Logging
Monitoring and logging are essential for maintaining the stability, performance, and security of a serverless backend. These practices provide the necessary visibility into the application’s inner workings, allowing developers and operations teams to quickly identify and address problems.
- Real-time Insights: Monitoring provides real-time visibility into key performance indicators (KPIs) such as latency, error rates, and throughput. This allows for immediate identification of performance degradation or service disruptions.
- Proactive Issue Detection: Setting up alerts based on predefined thresholds allows for proactive identification of potential problems before they impact users. For example, an alert can be triggered if the error rate exceeds a certain percentage.
- Faster Troubleshooting: Detailed logs provide a rich source of information for troubleshooting issues. They enable developers to trace the execution path of requests, identify the root cause of errors, and understand the behavior of the application.
- Performance Optimization: Analyzing monitoring data and logs helps identify performance bottlenecks and areas for optimization. This can involve optimizing function code, scaling resources, or improving database queries.
- Security Auditing: Logs can be used for security auditing, enabling the detection of suspicious activity and the identification of potential security breaches.
Setting up Monitoring Dashboards and Alerting Systems
Monitoring dashboards and alerting systems are critical for gaining actionable insights into the performance and health of a serverless application. The choice of tools and the configuration of dashboards and alerts should align with the specific requirements of the application and the chosen cloud provider.
- Choosing a Monitoring Tool: Select a monitoring tool that integrates seamlessly with the chosen cloud provider. Popular choices include AWS CloudWatch, Azure Monitor, and Google Cloud Monitoring. These tools offer a range of features, including metric collection, dashboarding, and alerting. Consider third-party solutions like Datadog or New Relic for more advanced features and cross-cloud compatibility.
- Defining Key Metrics: Identify the key performance indicators (KPIs) that are most relevant to the application. These might include:
- Invocation Count: The number of times a function is executed.
- Duration: The time it takes for a function to complete execution.
- Error Rate: The percentage of function invocations that result in errors.
- Concurrent Executions: The number of function instances running simultaneously.
- Cold Start Latency: The time it takes for a new function instance to start.
- API Gateway Latency: The time it takes for API requests to be processed.
- Creating Monitoring Dashboards: Design dashboards that visualize the key metrics. These dashboards should provide a clear overview of the application’s health and performance. Utilize graphs, charts, and tables to present the data effectively.
- Setting up Alerts: Configure alerts to be triggered when predefined thresholds are exceeded. For example, an alert can be triggered if the error rate exceeds 5% or if the average function duration exceeds a certain time. Notifications can be sent via email, SMS, or other channels. Consider implementing anomaly detection to identify unusual behavior patterns.
- Integrating with CI/CD: Integrate monitoring and alerting setup into the CI/CD pipeline to automate the configuration and ensure consistent monitoring across different environments.
Using Logging Services to Troubleshoot Issues
Logging services are indispensable for debugging and understanding the behavior of serverless applications. They capture detailed information about function executions, API requests, and other events, providing valuable insights into the application’s inner workings. The effective use of logging services allows for faster troubleshooting and identification of the root cause of issues.
- Choosing a Logging Service: Select a logging service that integrates with the chosen cloud provider. Popular options include AWS CloudWatch Logs, Azure Monitor Logs, and Google Cloud Logging.
- Implementing Logging in Functions: Add logging statements to the function code to capture relevant information. Log important events, such as function invocations, input parameters, output values, and any errors that occur. Use structured logging to make it easier to search and analyze the logs.
- Log Levels: Utilize different log levels (e.g., DEBUG, INFO, WARN, ERROR) to categorize log messages based on their severity. This allows for filtering logs based on the level of detail required.
- Log Aggregation and Analysis: Configure the logging service to aggregate logs from all functions and services. Use the service’s search and filtering capabilities to analyze the logs and identify patterns. Consider using log analysis tools to automatically detect anomalies and generate reports.
- Example Log Entries:
AWS CloudWatch Logs (JSON Format):
"timestamp": 1678886400000,
"requestId": "a1b2c3d4-e5f6-7890-1234-567890abcdef",
"level": "INFO",
"message": "Function started",
"functionName": "my-function",
"executionTime": 100,
"memoryUsed": 128Azure Monitor Logs (Kusto Query Language):
FunctionAppLogs
| where FunctionName == "MyFunction"
| where Level == "Error"
| project TimeGenerated, FunctionName, Message, Exception
Google Cloud Logging (JSON Format):
"severity": "ERROR",
"message": "Failed to process request",
"httpRequest":
"requestMethod": "POST",
"requestUrl": "/api/data",
"status": 500
,
"functionName": "processData"
Concluding Remarks
In conclusion, building a serverless web application backend offers a powerful and efficient approach to modern web development. By understanding the core principles, selecting appropriate cloud services, and adopting best practices for design, deployment, and monitoring, developers can create highly scalable, cost-effective, and resilient backend systems. The serverless architecture empowers developers to focus on innovation and user experience, ultimately leading to more agile and successful web applications.
The journey of serverless backend development is one of continuous learning and adaptation, but the rewards in terms of scalability, cost savings, and developer productivity are significant.
FAQ Resource
What are the primary benefits of using a serverless backend?
Serverless backends offer several advantages, including reduced operational costs (pay-per-use), automatic scaling, increased developer productivity (focus on code, not servers), and improved scalability and resilience. This architecture also eliminates the need for server management, reducing operational overhead.
How does serverless handle scaling?
Serverless platforms automatically scale resources based on demand. When the application experiences an increase in traffic, the cloud provider dynamically allocates more resources (e.g., compute functions) to handle the load. Conversely, when the traffic decreases, the resources are scaled down, optimizing resource utilization and cost.
What are the main considerations when choosing a cloud provider for a serverless backend?
Key considerations include the range of serverless services offered (compute, storage, database), pricing models, ease of use, community support, and integration capabilities. It is crucial to evaluate each provider’s offerings to determine the best fit for the specific application requirements and budget.
How can I debug serverless functions?
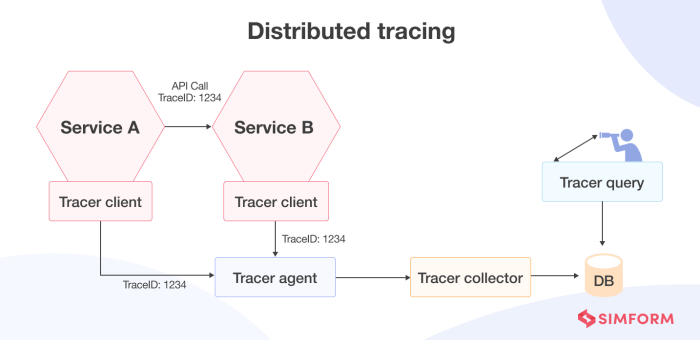
Debugging serverless functions typically involves utilizing logging services (e.g., AWS CloudWatch Logs, Azure Monitor, Google Cloud Logging) to capture function execution logs, including errors, warnings, and informational messages. Debugging tools within the cloud provider’s console or IDE integrations can also be employed. Tracing tools, such as X-Ray or similar services, can help track requests across multiple services.
What are the security best practices for serverless backends?
Security best practices include implementing secure authentication and authorization mechanisms (e.g., JWT, OAuth), regularly updating dependencies, using encryption for sensitive data, employing input validation and sanitization, and monitoring for security vulnerabilities. Following the principle of least privilege is crucial.