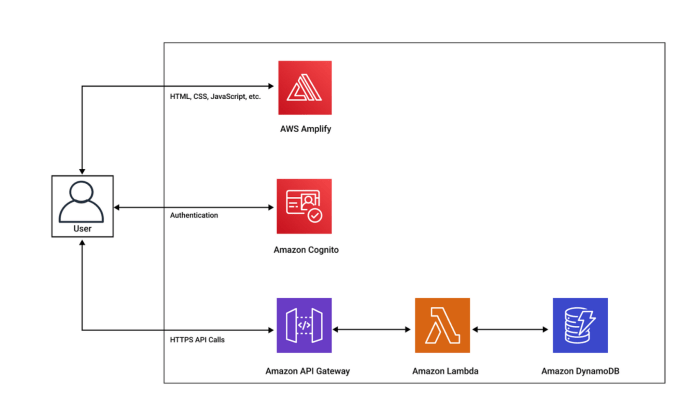
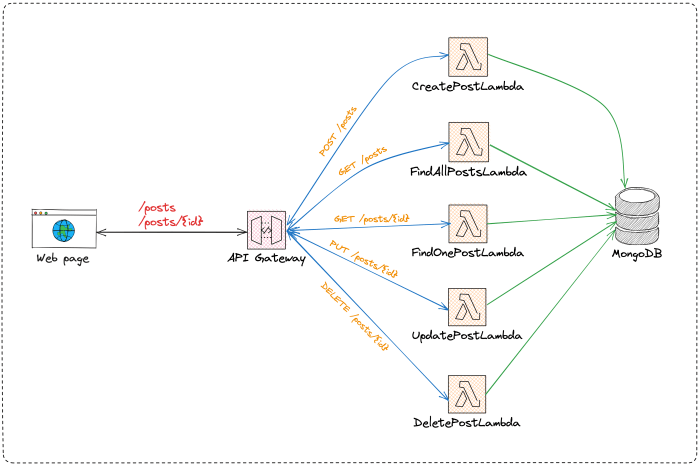
The evolution of cloud computing has ushered in the era of serverless architectures, promising scalability, cost-efficiency, and rapid development cycles. However, the inherent complexity of managing and deploying serverless applications can quickly become a bottleneck without proper automation. This guide delves into the critical aspects of automating serverless deployments, transforming a potentially cumbersome process into a streamlined, efficient, and secure workflow.
This discussion will navigate the landscape of automation tools, Infrastructure as Code (IaC) practices, Continuous Integration/Continuous Deployment (CI/CD) pipelines, version control, monitoring, security, and advanced deployment strategies. Each facet is explored with an analytical lens, providing actionable insights and practical examples to empower developers and operations teams to embrace automation effectively.
Introduction to Serverless Application Deployment Automation
Serverless computing, characterized by its event-driven architecture and automatic scaling, presents unique opportunities and challenges for application deployment. Automating this process is crucial for realizing the full potential of serverless platforms, streamlining development cycles, and ensuring operational efficiency. This introduction will detail the core benefits of automation, highlight the pitfalls of manual deployments, and underscore the vital role of automation within Continuous Integration and Continuous Delivery (CI/CD) pipelines in serverless environments.
Core Benefits of Automating Serverless Application Deployments
Automating serverless application deployments offers several significant advantages over manual processes, primarily centered around increased efficiency, reduced risk, and improved scalability. These benefits directly translate into faster development cycles, enhanced application reliability, and lower operational costs.
- Increased Speed and Efficiency: Automation significantly accelerates the deployment process. Instead of manually configuring and uploading code, automated pipelines can execute these tasks rapidly, allowing developers to iterate faster and release new features more frequently. For example, a manual deployment that might take several hours can be reduced to minutes with an automated system. This is especially true in scenarios involving multiple functions or microservices, where manual intervention would be extremely time-consuming.
- Reduced Errors and Improved Reliability: Manual deployments are prone to human error. Automation eliminates these errors by consistently applying the same configuration and deployment steps every time. This consistency leads to more reliable deployments and reduces the risk of application downtime. Automated systems also often include built-in rollback mechanisms, enabling rapid recovery from deployment failures.
- Enhanced Scalability and Resource Management: Serverless applications are designed to scale automatically. Automation complements this by dynamically provisioning and de-provisioning resources based on demand. Automated deployment tools can configure autoscaling policies, ensuring the application can handle fluctuating workloads without manual intervention. This optimizes resource utilization and cost efficiency.
- Improved Security and Compliance: Automation allows for consistent application of security best practices and compliance requirements. Security configurations, such as access control policies and encryption settings, can be defined once and automatically applied to every deployment. This reduces the risk of misconfigurations and security vulnerabilities. Compliance checks can also be integrated into automated pipelines to ensure that deployments meet regulatory requirements.
- Cost Optimization: Automation can help reduce operational costs by optimizing resource usage. For example, automated deployment systems can automatically scale down resources during periods of low demand, minimizing infrastructure expenses. Furthermore, by reducing the time spent on manual tasks, automation frees up developers to focus on more strategic initiatives.
Common Challenges Faced During Manual Serverless Deployments
Manual serverless deployments introduce a range of challenges that can significantly hinder development velocity, increase operational costs, and compromise application reliability. These challenges stem from the inherent complexity of serverless architectures and the potential for human error in repetitive tasks.
- Time-Consuming and Error-Prone Processes: Manually deploying serverless applications involves several steps, including packaging code, configuring infrastructure, and uploading the application to the cloud provider. Each step is time-consuming and susceptible to human error. For instance, incorrect configuration of environment variables or missing dependencies can lead to deployment failures and delays.
- Configuration Drift and Inconsistency: Without automation, deployments across different environments (e.g., development, staging, production) can become inconsistent. Manual configuration of infrastructure and application settings can lead to “configuration drift,” where environments diverge over time. This inconsistency makes it difficult to reproduce issues, troubleshoot problems, and maintain application stability.
- Difficulty in Scaling and Managing Resources: Manually scaling serverless applications to meet fluctuating demand is challenging. It requires continuous monitoring of resource usage and manual adjustments to capacity. This process is inefficient and can lead to performance bottlenecks or underutilized resources.
- Lack of Version Control and Rollback Capabilities: Manual deployments often lack robust version control and rollback capabilities. Without proper versioning, it is difficult to revert to a previous stable state in case of deployment failures or performance issues. This increases the risk of prolonged downtime and hinders the ability to quickly recover from errors.
- Increased Security Risks: Manual deployments increase the risk of security vulnerabilities. Manual configuration of security settings, such as access control policies and encryption keys, can be error-prone. This can lead to misconfigurations that expose the application to security threats.
Importance of Automation for CI/CD Pipelines in Serverless Architectures
Continuous Integration and Continuous Delivery (CI/CD) pipelines are essential for modern software development, and their importance is amplified in serverless architectures. Automation is the cornerstone of effective CI/CD, enabling rapid, reliable, and repeatable deployments.
- Automated Build and Testing: CI/CD pipelines automate the build and testing phases of the software development lifecycle. This includes compiling code, running unit tests, and performing integration tests. Automation ensures that code changes are validated quickly and frequently, reducing the risk of introducing bugs into production. For example, every code commit can trigger an automated build and test cycle, providing immediate feedback to developers.
- Automated Deployment and Rollback: CI/CD pipelines automate the deployment process, including packaging code, provisioning infrastructure, and deploying the application to the cloud. Automated deployments can be triggered by code changes or scheduled events. Automated rollback mechanisms allow for rapid recovery from deployment failures, minimizing downtime.
- Infrastructure as Code (IaC): IaC allows infrastructure to be defined and managed using code, just like application code. This enables automated provisioning and configuration of cloud resources. IaC tools, such as Terraform or AWS CloudFormation, are integrated into CI/CD pipelines to ensure that infrastructure is consistently provisioned and configured across all environments.
- Continuous Monitoring and Feedback Loops: CI/CD pipelines integrate continuous monitoring and feedback loops. Automated monitoring tools track application performance, error rates, and other key metrics. This data is used to identify and address issues quickly. Feedback loops enable developers to continuously improve the application based on real-world usage.
- Faster Release Cycles and Reduced Time to Market: By automating the entire software development lifecycle, CI/CD pipelines enable faster release cycles and reduce the time to market for new features and bug fixes. This agility is crucial for staying competitive in today’s fast-paced environment. For instance, companies can release updates several times a day instead of weeks or months, as the CI/CD pipeline automates the entire process.
Choosing the Right Automation Tools

Selecting the appropriate automation tools is crucial for the efficient and reliable deployment of serverless applications. The choice directly impacts development speed, operational costs, and the overall maintainability of the application. Careful consideration of project requirements and the capabilities of available tools is paramount for a successful serverless implementation.
Identifying and Comparing Automation Tools
Several automation tools cater to serverless application deployments, each with its strengths and weaknesses. Understanding these differences is vital for making an informed decision. These tools streamline the deployment process, manage infrastructure, and provide features that facilitate the development lifecycle.
- AWS Serverless Application Model (SAM): SAM is an open-source framework provided by AWS for building serverless applications. It simplifies the definition of serverless resources using a declarative YAML or JSON template format. SAM is tightly integrated with AWS services, offering a seamless deployment experience within the AWS ecosystem.
- Serverless Framework: This is a vendor-agnostic, open-source framework that supports multiple cloud providers, including AWS, Azure, and Google Cloud Platform. It uses a YAML configuration file to define and deploy serverless functions, APIs, and other resources. The Serverless Framework aims to provide a consistent deployment experience across different cloud providers.
- Terraform: Terraform is an infrastructure-as-code (IaC) tool developed by HashiCorp. It allows users to define and manage infrastructure resources across multiple cloud providers using a declarative configuration language (HCL). While not specifically designed for serverless, Terraform can be used to provision and manage the underlying infrastructure required by serverless applications.
Criteria for Selecting the Best Tool
Choosing the optimal automation tool necessitates evaluating several key criteria. These factors significantly influence the tool’s suitability for a particular project and impact the overall development process. Careful consideration of these aspects is essential for maximizing efficiency and minimizing potential challenges.
- Ease of Use: The learning curve and usability of the tool are critical. A simpler tool allows developers to quickly grasp and implement the deployment process. User-friendliness promotes faster development cycles and reduces the likelihood of errors.
- Cost: The total cost of ownership, including licensing fees (if applicable), resource consumption, and operational overhead, should be assessed. Open-source tools often have lower upfront costs but may require more in-house expertise. Managed services can simplify operations but may have higher associated costs.
- Supported Features: The tool’s capabilities, such as CI/CD integration, monitoring, debugging, and support for various serverless services, should align with project requirements. Comprehensive feature sets enhance productivity and simplify application management.
- Vendor Lock-in: The degree to which the tool ties the project to a specific cloud provider or platform. Vendor-agnostic tools offer greater flexibility and portability, while vendor-specific tools may provide tighter integration and optimized performance within a particular ecosystem.
Comparative Analysis of Popular Automation Tools
The following table provides a comparative analysis of AWS SAM, Serverless Framework, and Terraform, highlighting their pros and cons. This comparison aids in making informed decisions based on specific project needs and priorities.
| Tool | Pros | Cons | Considerations |
|---|---|---|---|
| AWS SAM |
|
| Ideal for projects exclusively using AWS services. Offers a streamlined deployment experience within the AWS ecosystem. Well-suited for teams already familiar with AWS. |
| Serverless Framework |
|
| Best for projects requiring cross-cloud compatibility or those that want to avoid vendor lock-in. Provides flexibility in selecting cloud providers. Suitable for teams seeking portability. |
| Terraform |
|
| Best suited for projects needing comprehensive infrastructure management, including serverless components. Offers greater control over infrastructure provisioning. Suitable for experienced infrastructure engineers. |
Infrastructure as Code (IaC) for Serverless
Infrastructure as Code (IaC) is a fundamental practice in modern software development, offering significant advantages in terms of automation, consistency, and reproducibility. When applied to serverless applications, IaC allows developers to define and manage all the necessary cloud resources through code, streamlining the deployment process and improving overall efficiency. This approach eliminates manual configuration, reduces the potential for human error, and enables version control of infrastructure, ensuring a reliable and repeatable deployment pipeline.
Applying IaC Principles to Serverless Deployments
IaC principles are directly applicable to serverless architectures. Instead of manually configuring resources like functions, API gateways, and databases through a cloud provider’s console, IaC allows for their definition within declarative configuration files. These files, written in formats like YAML or JSON, describe the desired state of the infrastructure. Automation tools then interpret these files and provision the necessary resources, ensuring that the infrastructure matches the specified configuration.
This process promotes consistency, as the same configuration can be used to deploy serverless applications across multiple environments (e.g., development, staging, production). Furthermore, IaC facilitates infrastructure versioning, allowing for tracking changes, rolling back to previous states, and collaborating effectively on infrastructure management. The use of IaC dramatically reduces the risk of configuration drift, where infrastructure deviates from the intended state due to manual changes or inconsistencies.
Writing IaC Templates for Serverless Resources
Writing IaC templates involves defining serverless resources and their configurations within a structured format, typically using YAML or JSON. These templates serve as blueprints for deploying and managing the infrastructure. The structure of these templates often varies depending on the chosen IaC tool, such as AWS CloudFormation, Terraform, or Serverless Framework. Regardless of the tool, the templates generally include sections to define the serverless function (e.g., the function’s code, runtime environment, memory allocation), API gateway (e.g., API endpoints, authentication mechanisms), and any supporting resources (e.g., databases, storage buckets).The template language allows specifying dependencies between resources, ensuring that resources are created in the correct order.
For example, the API gateway might depend on the serverless function, meaning the function must be created before the API gateway can be configured to invoke it. Parameters and variables are commonly used to make templates reusable and adaptable to different environments. For example, a parameter could define the function’s memory size, allowing for different sizes in development and production environments.
When creating templates, it is essential to adhere to the specific syntax and structure of the chosen IaC tool. Careful planning and modularization of templates can improve maintainability and readability.
Code Example: Deploying a Simple Serverless Function and API Gateway
The following example, written in YAML using AWS CloudFormation, demonstrates the deployment of a simple serverless function (written in Python) and an API Gateway endpoint. This example focuses on the core components of a basic serverless application: a function to execute code and an API Gateway to expose the function as an HTTP endpoint.“`yamlAWSTemplateFormatVersion: ‘2010-09-09’Transform: AWS::Serverless-2016-10-31Description: > Simple Serverless Function with API GatewayResources: HelloWorldFunction: Type: AWS::Serverless::Function Properties: FunctionName: HelloWorldFunction Handler: hello_world.handler Runtime: python3.9 CodeUri: ./src/ MemorySize: 128 Timeout: 10 Events: HelloWorldApi: Type: Api Properties: Path: /hello Method: getOutputs: HelloWorldApiEndpoint: Description: “API Gateway endpoint URL for Hello World function” Value: !Sub “https://$ServerlessRestApi.execute-api.$AWS::Region.amazonaws.com/Prod/hello”“`The YAML code illustrates the following:* `AWSTemplateFormatVersion`: Specifies the version of the CloudFormation template format.
`Transform
AWS::Serverless-2016-10-31`: This line utilizes the AWS Serverless Application Model (SAM) transform, which simplifies the definition of serverless resources.
`Resources`
This section defines the resources to be created.
`HelloWorldFunction`
Defines a serverless function.
`FunctionName`
Specifies the name of the function.
`Handler`
Specifies the entry point for the function (file name and function name).
`Runtime`
Specifies the runtime environment (Python 3.9 in this case).
`CodeUri`
Specifies the location of the function’s code (a directory named `src` in this example, which would contain the `hello_world.py` file).
`MemorySize`
Specifies the memory allocated to the function (128 MB).
`Timeout`
Specifies the function’s execution timeout (10 seconds).
`Events`
Defines the events that trigger the function.
`HelloWorldApi`
Defines an API Gateway event.
`Type`
Specifies the event type as `Api`.
`Properties`
Defines the API Gateway properties.
`Path`
Specifies the API endpoint path (`/hello`).
`Method`
Specifies the HTTP method (`GET`).
`Outputs`
This section defines the outputs of the template.
`HelloWorldApiEndpoint`
Defines an output that provides the URL of the API Gateway endpoint. The `!Sub` intrinsic function is used to construct the URL using CloudFormation variables.This template, when deployed using CloudFormation, would create a Lambda function that returns a “Hello World” message and an API Gateway endpoint that triggers this function when accessed via a GET request to `/hello`. The `CodeUri` property directs CloudFormation to the location of the function’s code, enabling the automatic deployment of the function’s code along with the infrastructure.
This example provides a basic foundation for deploying more complex serverless applications, showcasing the power of IaC in automating the provisioning and management of serverless resources.
CI/CD Pipelines for Serverless Applications
Implementing Continuous Integration and Continuous Deployment (CI/CD) pipelines is crucial for efficiently and reliably deploying serverless applications. These pipelines automate the build, test, and deployment processes, reducing manual intervention, minimizing errors, and accelerating the release cycle. This approach ensures that code changes are integrated frequently, tested thoroughly, and deployed quickly, enabling faster feedback loops and more agile development practices.
Steps for Setting Up a CI/CD Pipeline
Setting up a CI/CD pipeline involves several key steps, from code commit to deployment. Each step is designed to automate a specific part of the software development lifecycle, ensuring quality and consistency. The pipeline is typically triggered by a code commit to a version control system.
- Code Commit: Developers commit code changes to a version control system like Git. This triggers the CI/CD pipeline.
- Build: The build phase involves compiling the code, resolving dependencies, and packaging the application. For serverless applications, this often includes packaging the code and any necessary configuration files.
- Automated Testing: This is a critical phase that includes various types of testing to ensure code quality and functionality. Different testing strategies are applied, including unit tests, integration tests, and end-to-end tests.
- Deployment: Once the tests pass, the application is deployed to the serverless platform. This typically involves updating the function code, configuration, and any related infrastructure resources.
- Monitoring and Feedback: After deployment, the application is monitored for performance and errors. Feedback from monitoring tools helps identify issues and improve the application.
Integrating Automated Testing into the CI/CD Pipeline
Automated testing is a cornerstone of a robust CI/CD pipeline. It ensures that code changes do not introduce regressions and that the application functions as expected. Integrating different levels of testing is crucial for comprehensive validation.
- Unit Tests: These tests verify the functionality of individual components or functions in isolation. They are typically fast to execute and provide quick feedback on code changes.
Example: Testing a serverless function that processes user input. The unit tests would verify the function’s ability to handle different input scenarios (valid, invalid, edge cases) and produce the correct output.
- Integration Tests: These tests verify the interaction between different components of the application. They ensure that different parts of the system work together correctly.
Example: Testing a serverless function that interacts with a database. Integration tests would verify that the function can successfully connect to the database, read and write data, and handle database errors.
- End-to-End (E2E) Tests: These tests simulate user interactions with the entire application, from the user interface to the backend services. They validate the overall functionality of the application.
Example: Testing a web application that uses serverless functions for authentication and data retrieval. E2E tests would simulate a user logging in, browsing the application, and verifying that data is displayed correctly.
Organizing the Steps of a CI/CD Pipeline
Organizing the steps of a CI/CD pipeline effectively is crucial for its efficiency and reliability. Each stage should be clearly defined and automated, with clear triggers and outputs. The pipeline should be designed to provide rapid feedback and enable fast deployments.
- Code Commit: As described above, this initiates the pipeline when changes are pushed to the repository.
- Build Phase: This includes the following actions:
- Downloading dependencies.
- Compiling the code.
- Packaging the application artifacts.
- Test Phase: This includes the following actions:
- Running unit tests.
- Running integration tests.
- Running end-to-end tests.
- Generating test reports.
- Deployment Phase: This includes the following actions:
- Deploying the application code to the serverless platform (e.g., AWS Lambda, Azure Functions, Google Cloud Functions).
- Updating configuration and infrastructure resources.
- Performing post-deployment checks and validation.
Version Control and Rollbacks
Version control and automated rollbacks are critical components of a robust serverless deployment strategy. They ensure that deployments are traceable, reversible, and resilient to failures, ultimately contributing to application stability and developer productivity. Proper implementation minimizes downtime, facilitates rapid recovery, and allows for controlled experimentation.
Importance of Version Control in Serverless Deployments
Version control systems, such as Git, are indispensable for managing serverless application code and infrastructure configurations. They provide a historical record of all changes, enabling collaboration, auditability, and the ability to revert to previous states.
- Code Management: Version control tracks every change to the application code (e.g., functions, triggers, libraries). This allows developers to work concurrently, track bugs, and revert to previous versions if necessary.
- Infrastructure as Code (IaC) Configuration: Serverless deployments heavily rely on IaC tools (e.g., AWS CloudFormation, Terraform). Version control stores and manages the IaC configuration files, ensuring consistency and reproducibility of the infrastructure. This enables developers to track changes to the infrastructure definition and revert to a previous state if needed.
- Collaboration and Auditing: Version control facilitates collaboration among developers by providing a centralized repository for code and configuration. It also enables auditing, allowing for the tracking of who made what changes and when, crucial for security and compliance.
- Disaster Recovery: In case of a deployment failure or a production issue, version control allows for a rapid rollback to a known good state. This minimizes downtime and mitigates the impact of errors.
Methods for Implementing Automated Rollbacks in Case of Deployment Failures
Automated rollbacks are essential for mitigating the impact of deployment failures in serverless applications. Several strategies can be employed to ensure a swift and reliable recovery process.
- Blue/Green Deployments: This strategy involves deploying the new version (blue) alongside the existing version (green). Traffic is gradually shifted from the green environment to the blue environment. If the blue deployment fails, traffic can be quickly routed back to the green environment, minimizing downtime. This approach requires careful planning of resource allocation and traffic management.
- Canary Deployments: A canary deployment involves deploying the new version to a small subset of users (the “canary”) to test it in production. If the canary deployment is successful, the new version is rolled out to all users. If the canary deployment fails, the new version is rolled back. This method minimizes the impact of potential issues by exposing only a small portion of users to the new version.
- Automated Rollback Mechanisms within CI/CD Pipelines: CI/CD pipelines should include automated rollback steps. If a deployment fails (e.g., a function fails to deploy, tests fail), the pipeline should automatically revert to the previous stable version. This can be achieved by using the version control system to revert to the last known good commit and redeploying that version.
- Monitoring and Alerting: Implement robust monitoring and alerting systems to detect deployment failures and performance degradation. Alerts should trigger automated rollback procedures. This proactive approach allows for rapid response and minimizes the impact of issues.
- Idempotent Operations: Ensure that deployment operations are idempotent. This means that running the same deployment script multiple times should have the same effect as running it once. This is crucial for rollbacks, as it ensures that reverting to a previous version can be done safely and reliably.
Process Flow Chart Illustrating the Rollback Procedure for a Failed Serverless Deployment
A process flow chart visually represents the steps involved in rolling back a failed serverless deployment. This helps in understanding the sequence of actions and identifying potential points of failure.
Process Flow Chart Description:
The flowchart illustrates the rollback procedure triggered by a failed serverless deployment. The process begins with a “Deployment Attempt” step. If the deployment succeeds, the process ends. If the deployment fails, the process proceeds to the “Deployment Failure Detected” step. This is followed by “Check for Rollback Strategy” which examines the deployment configuration.
Based on the chosen strategy (e.g., Blue/Green, Canary), the appropriate rollback steps are executed. If a rollback is possible (e.g., traffic redirection to the previous version), the “Rollback Initiated” step is executed. Following a successful rollback, the “Rollback Successful” step is reached, and the process ends. If the rollback fails, the process proceeds to the “Manual Intervention Required” step, where human intervention is necessary to resolve the issue.
Finally, an “Incident Report” is created and the process ends.
Example:
Consider a scenario where a new version of a serverless function fails to deploy due to a code error. The CI/CD pipeline detects the failure. Based on the rollback strategy (e.g., revert to the previous Git commit), the pipeline automatically reverts to the last known good version and redeploys it. Monitoring systems also provide alerts, providing insight into the failure, ensuring that the previous stable version is restored.
Monitoring and Logging in Automated Deployments
Automated serverless deployments, while streamlining the application lifecycle, introduce complexities that necessitate robust monitoring and logging strategies. The ephemeral nature of serverless functions and the distributed architecture demand real-time insights into application behavior, performance, and potential issues. Without effective monitoring and logging, identifying and resolving problems in a timely manner becomes significantly more challenging, potentially impacting application availability and user experience.
Significance of Monitoring and Logging in Automated Serverless Environments
Monitoring and logging are crucial components in automated serverless environments, providing visibility into the application’s operational state and facilitating proactive issue resolution. They are indispensable for maintaining application health and performance.
- Real-time Visibility: Monitoring tools provide real-time data on function invocations, execution times, error rates, and resource utilization. This real-time data allows for immediate identification of performance bottlenecks or errors, enabling rapid response and mitigation.
- Proactive Issue Detection: By analyzing logs and metrics, potential problems can be detected before they impact users. Automated alerts can be configured to notify developers of unusual behavior, such as a sudden increase in error rates or a decrease in function performance.
- Performance Optimization: Monitoring data helps identify areas for optimization, such as inefficient code, resource over-allocation, or slow database queries. Analyzing performance metrics allows for targeted improvements to enhance application speed and efficiency.
- Debugging and Troubleshooting: Detailed logs provide valuable context for debugging and troubleshooting. They include information about function invocations, input parameters, execution paths, and any errors that occurred during execution. This data is critical for quickly diagnosing and resolving issues.
- Compliance and Auditing: Logging is essential for compliance with regulatory requirements and for auditing application behavior. Logs provide a record of all actions performed by the application, allowing for verification of data integrity and adherence to security policies.
Integrating Monitoring Tools into the Deployment Pipeline
Integrating monitoring tools into the deployment pipeline automates the setup and configuration of monitoring resources, ensuring consistent monitoring across all deployments. This integration simplifies the monitoring process and reduces the risk of human error.
- Infrastructure as Code (IaC): Utilize IaC tools like Terraform or AWS CloudFormation to define and provision monitoring resources, such as CloudWatch dashboards, metrics, and alarms, alongside the serverless application code. This approach ensures that monitoring resources are automatically created and configured as part of the deployment process. For example, a CloudFormation template can define a CloudWatch alarm that triggers when the error rate of a Lambda function exceeds a predefined threshold.
- Deployment Pipeline Integration: Integrate the monitoring tool’s configuration into the CI/CD pipeline. After the application code is deployed, the pipeline can automatically configure the monitoring tools, such as setting up dashboards, defining alerts, and enabling log aggregation.
- Automated Alerting: Configure automated alerts based on predefined thresholds for key metrics, such as error rates, latency, and resource utilization. When these thresholds are exceeded, the monitoring tool automatically sends notifications to the development team, enabling prompt response and issue resolution.
- Log Aggregation and Analysis: Implement log aggregation tools to collect logs from all serverless functions and services into a centralized location. Tools like CloudWatch Logs Insights or third-party solutions like Datadog can be used to analyze logs, identify patterns, and troubleshoot issues.
- Version Control: Store monitoring configurations in version control systems alongside the application code. This allows for tracking changes to monitoring configurations, enabling rollbacks, and ensuring consistency across different environments.
Sample Configuration for Logging using CloudWatch
Configuring effective logging is critical for gaining insights into the behavior of serverless applications. This example illustrates how to configure logging using CloudWatch, demonstrating log levels and destinations.
Consider the following Python code snippet for a Lambda function:
import loggingimport jsonimport os# Configure logginglogger = logging.getLogger()logger.setLevel(logging.INFO)def lambda_handler(event, context): try: # Log the event data logger.info(f"Received event: json.dumps(event)") # Access environment variables environment = os.environ.get('ENVIRONMENT', 'production') logger.debug(f"Environment: environment") # Simulate a business operation result = process_data(event) # Log the result logger.info(f"Processed result: json.dumps(result)") return 'statusCode': 200, 'body': json.dumps(result) except Exception as e: # Log errors logger.error(f"Error: str(e)") return 'statusCode': 500, 'body': json.dumps('error': str(e)) def process_data(event): # Simulate data processing data = event.get('data', ) if not data: raise ValueError("No data provided") return 'processed': True, 'data': data The CloudWatch configuration can be set up via IaC (e.g., AWS CloudFormation or Terraform).
The following snippet shows a simplified CloudFormation template extract to configure the logging destination for the Lambda function’s logs:
Resources: MyLambdaFunction: Type: AWS::Lambda::Function Properties: FunctionName: !Sub "MyLambdaFunction-$AWS::StackName" Runtime: python3.9 Handler: index.lambda_handler Code: ZipFile: | import logging import json import os logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): try: logger.info(f"Received event: json.dumps(event)") environment = os.environ.get('ENVIRONMENT', 'production') logger.debug(f"Environment: environment") result = process_data(event) logger.info(f"Processed result: json.dumps(result)") return 'statusCode': 200, 'body': json.dumps(result) except Exception as e: logger.error(f"Error: str(e)") return 'statusCode': 500, 'body': json.dumps('error': str(e)) def process_data(event): data = event.get('data', ) if not data: raise ValueError("No data provided") return 'processed': True, 'data': data Role: !GetAtt MyLambdaExecutionRole.Arn Environment: Variables: ENVIRONMENT: production TracingConfig: Mode: Active # Enables AWS X-Ray tracing. Useful for distributed tracing. MyLambdaExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: -Effect: Allow Principal: Service: lambda.amazonaws.com Action: sts:AssumeRole Policies: -PolicyName: !Sub "MyLambdaPolicy-$AWS::StackName" PolicyDocument: Version: "2012-10-17" Statement: -Effect: Allow Actions: -logs:CreateLogGroup -logs:CreateLogStream -logs:PutLogEvents -logs:DescribeLogStreams Resource: arn:aws:logs:*:*:log-group:/aws/lambda/* -Effect: Allow Actions: -xray:PutTraceSegments -xray:GetSamplingRules -xray:GetSamplingTargets Resource: "*"
- Log Levels: The example code utilizes different log levels:
logger.info(): Used for general information about the function’s execution, such as the event data received and the result of processing.logger.debug(): Used for detailed information, like the environment variables being used. Useful for development and troubleshooting, but often disabled in production to reduce log volume.logger.error(): Used for logging errors and exceptions that occur during the function’s execution. Includes the error message.
- Log Destinations:
- CloudWatch Logs: All logs are automatically sent to CloudWatch Logs. The Lambda function automatically creates a log group named
/aws/lambda/MyLambdaFunction. The IAM role associated with the Lambda function grants the necessary permissions to write to CloudWatch Logs. - AWS X-Ray (Optional): Enabling Active tracing mode on the Lambda function (as shown in the CloudFormation snippet) sends tracing data to AWS X-Ray. This provides a visual representation of the request flow through different services, which is essential for distributed tracing.
- CloudWatch Logs: All logs are automatically sent to CloudWatch Logs. The Lambda function automatically creates a log group named
- Log Format: The logs will include a timestamp, the log level, and the log message. The log messages are formatted using f-strings for clarity and readability. The JSON.dumps() function is used to serialize the event and result data, making them easy to analyze.
- Analysis and Alerting: CloudWatch Logs Insights can be used to query and analyze the logs. Metrics can be extracted from the logs and used to create CloudWatch alarms to trigger notifications based on specific events or error conditions. For example, an alarm can be configured to trigger if the number of errors exceeds a certain threshold within a given time period.
Security Considerations in Automated Deployments
![How to deploy Serverless Applications in Go using AWS Lambda [Tutorial]](https://wp.ahmadjn.dev/wp-content/uploads/2025/06/011a0c77233eadae9be63fcf131e67e8.jpg "How to deploy Serverless Applications in Go using AWS Lambda [Tutorial]")
Automating serverless deployments, while offering significant advantages in speed and efficiency, introduces new security considerations that must be addressed proactively. The dynamic nature of serverless environments, combined with the inherent complexities of automated processes, necessitates a robust security strategy to protect against potential vulnerabilities. This involves implementing security best practices, identifying and mitigating risks, and integrating security checks throughout the deployment pipeline.
Security Best Practices for Automated Serverless Deployments
Implementing robust security practices is critical to protect serverless applications. These practices should be integrated throughout the entire deployment lifecycle, from code development to infrastructure provisioning and runtime execution.
- Principle of Least Privilege: Grant each function and service only the minimum permissions necessary to perform its tasks. Avoid using overly permissive roles or access keys. Implement role-based access control (RBAC) to define and enforce these permissions. For instance, a function that processes image uploads should only have write access to the designated storage bucket and read access to the input data.
- Secrets Management: Securely store and manage sensitive information, such as API keys, database credentials, and other secrets. Utilize dedicated secrets management services offered by cloud providers (e.g., AWS Secrets Manager, Azure Key Vault, Google Cloud Secret Manager) to encrypt and rotate secrets automatically. Avoid hardcoding secrets directly into the application code or configuration files.
- Input Validation and Sanitization: Implement rigorous input validation and sanitization to prevent common vulnerabilities like cross-site scripting (XSS) and SQL injection. Validate all inputs, including data received from API requests, event triggers, and other sources. Sanitize inputs to remove or neutralize potentially harmful characters or code.
- Regular Security Audits and Penetration Testing: Conduct regular security audits and penetration testing to identify and address vulnerabilities. Automate these processes where possible, integrating them into the CI/CD pipeline. Use security scanners to identify common vulnerabilities and misconfigurations in code and infrastructure.
- Monitoring and Logging: Implement comprehensive monitoring and logging to detect and respond to security incidents. Log all relevant events, including function invocations, API calls, and authentication attempts. Use security information and event management (SIEM) systems to analyze logs and identify suspicious activity.
- Network Security: Secure the network by configuring appropriate firewalls, virtual private clouds (VPCs), and other network security controls. Restrict access to serverless functions and other resources based on IP address, VPC, or other criteria. Consider using API gateways with built-in security features, such as authentication and authorization.
- Code Signing and Integrity Checks: Employ code signing to verify the authenticity and integrity of the deployed code. Ensure that only authorized code is deployed to the production environment. Use integrity checks to detect any unauthorized modifications to the code or infrastructure.
Risks Associated with Automated Deployments and Mitigation Strategies
Automated deployments, while efficient, introduce several potential security risks that require careful consideration and proactive mitigation strategies.
- Configuration Errors: Incorrectly configured infrastructure-as-code (IaC) templates or deployment scripts can introduce security vulnerabilities. For example, a misconfigured security group could expose resources to unauthorized access.
- Mitigation: Implement rigorous testing and validation of IaC templates and deployment scripts. Use linters and static analysis tools to identify configuration errors before deployment. Conduct regular audits of IaC configurations.
- Supply Chain Attacks: Compromised dependencies or third-party libraries can introduce malicious code into the serverless application. This is particularly concerning when automated deployments pull in the latest versions of these dependencies.
- Mitigation: Use a Software Composition Analysis (SCA) tool to identify and manage the use of open-source software (OSS) components in your serverless applications. Regularly update dependencies to the latest secure versions.
Implement dependency pinning to ensure that the same versions of dependencies are used across deployments.
- Mitigation: Use a Software Composition Analysis (SCA) tool to identify and manage the use of open-source software (OSS) components in your serverless applications. Regularly update dependencies to the latest secure versions.
- Unauthorized Access: Automated deployments may inadvertently grant unauthorized access to resources if access controls are not properly configured. For instance, an incorrectly configured IAM role could provide excessive permissions.
- Mitigation: Enforce the principle of least privilege. Regularly review and audit IAM roles and policies. Implement robust access controls and authentication mechanisms.
Use multi-factor authentication (MFA) for all accounts.
- Mitigation: Enforce the principle of least privilege. Regularly review and audit IAM roles and policies. Implement robust access controls and authentication mechanisms.
- Data Breaches: Data breaches can occur if sensitive data is not properly protected during the deployment process or at runtime. For example, unencrypted data stored in a database could be vulnerable to unauthorized access.
- Mitigation: Encrypt all sensitive data at rest and in transit. Use secrets management services to protect credentials and other sensitive information. Implement data loss prevention (DLP) measures.
- Vulnerability Exploitation: Exploits can occur if vulnerabilities in the serverless application or its dependencies are not addressed promptly. Automated deployments can accelerate the deployment of vulnerable code.
- Mitigation: Regularly scan code for vulnerabilities. Implement automated security testing as part of the CI/CD pipeline. Apply security patches promptly.
Security Checks in an Automated Deployment Pipeline
Integrating security checks into an automated deployment pipeline is crucial to ensure the security of serverless applications. These checks should be performed at various stages of the pipeline to identify and address vulnerabilities early in the development lifecycle.
- Static Code Analysis: Analyze the code for potential vulnerabilities, such as code injection flaws, insecure coding practices, and compliance violations. Tools like SonarQube, ESLint, and Bandit can be integrated into the pipeline to automate this process.
- Dependency Scanning: Scan the project dependencies for known vulnerabilities. Tools like Snyk, OWASP Dependency-Check, and Trivy can identify vulnerable libraries and suggest remediation steps.
- Infrastructure as Code (IaC) Security Scanning: Analyze the IaC templates (e.g., CloudFormation, Terraform) for security misconfigurations. Tools like Checkov and tfsec can identify issues such as overly permissive security groups, missing encryption, and improper IAM configurations.
- Secrets Scanning: Scan the code and configuration files for hardcoded secrets, such as API keys and database credentials. Tools like GitLeaks and truffleHog can automate this process.
- Container Image Scanning: Scan container images for vulnerabilities if the serverless application uses containers. Tools like Clair, Anchore Engine, and Docker Bench for Security can identify security flaws.
- Dynamic Application Security Testing (DAST): Perform dynamic security testing to identify runtime vulnerabilities, such as cross-site scripting (XSS) and SQL injection. Tools like OWASP ZAP and Burp Suite can be used in an automated fashion.
- Compliance Checks: Ensure that the application and infrastructure comply with relevant security standards and regulations (e.g., PCI DSS, HIPAA). Tools like AWS Config and Azure Policy can be used to automate compliance checks.
- Penetration Testing: Conduct regular penetration testing to identify and address vulnerabilities. This should be performed both manually and through automated tools.
Deployment Strategies for Serverless Applications
Serverless applications, by their nature, are designed for rapid iteration and scalability. However, the dynamic nature of serverless environments necessitates robust deployment strategies to minimize downtime, manage risk, and ensure a seamless user experience during updates. Choosing the right deployment strategy is critical for mitigating potential issues and optimizing the application’s performance and availability.
Comparing and Contrasting Deployment Strategies
Several deployment strategies are available for serverless applications, each with its own advantages and disadvantages. Selecting the optimal strategy depends on factors such as the application’s complexity, the criticality of downtime, and the desired level of risk tolerance.
- Blue/Green Deployment: This strategy involves maintaining two identical environments: a “blue” environment that serves live traffic and a “green” environment that hosts the new version. During deployment, the green environment is updated. Once testing and validation are complete, traffic is switched from the blue environment to the green environment. This offers a near-zero downtime deployment and allows for immediate rollback to the blue environment if issues arise.
However, it requires double the infrastructure and may incur higher costs.
- Canary Deployment: In a canary deployment, a small subset of users (the “canary”) is initially routed to the new version. This allows for real-world testing of the new version with a limited impact if problems occur. Traffic is gradually increased to the new version as confidence grows, and the canary deployment is fully rolled out. Canary deployments offer a good balance between risk and speed, allowing for early detection of issues without impacting all users.
Implementation complexity is generally higher than blue/green, as it requires precise traffic management and monitoring.
- Rolling Deployment: This strategy involves updating the application across a set of instances sequentially. While each instance is updated, the application continues to serve traffic. This strategy can minimize downtime, but it may result in a period where both the old and new versions are running simultaneously, potentially leading to compatibility issues. Rolling deployments are often simpler to implement than blue/green or canary deployments, but they are less suitable for applications with strict downtime requirements.
- Immutable Deployment: In this approach, each deployment creates a completely new, immutable infrastructure. The previous version is simply discarded. This simplifies rollbacks (by redeploying the previous immutable version) and eliminates configuration drift. However, it can lead to increased infrastructure costs if the infrastructure is not managed efficiently.
Implementing a Canary Deployment Strategy with an Automation Tool
Implementing a canary deployment strategy often involves using an automation tool to manage traffic routing and monitor application health. For instance, AWS Lambda provides native support for canary deployments through its deployment configuration settings, and tools like AWS CodeDeploy or third-party CI/CD solutions can be used.
The process involves several key steps:
- Version Deployment: Deploy the new application version (the “green” or canary version) alongside the existing production version (the “blue” version).
- Traffic Routing Configuration: Configure the traffic routing to send a small percentage of traffic to the new version. This can often be achieved using a weighted routing mechanism provided by the cloud provider (e.g., AWS Lambda’s traffic shifting).
- Monitoring and Metrics Collection: Implement robust monitoring and logging to track key metrics such as error rates, latency, and application performance on both versions.
- Automated Health Checks: Implement automated health checks to continuously assess the performance and stability of the new version.
- Traffic Shifting and Promotion: Based on the health checks and monitoring data, gradually increase the traffic to the new version. If any issues are detected, traffic can be automatically routed back to the original version.
- Full Rollout: Once the new version has been validated and deemed stable, shift all traffic to the new version and decommission the old version.
Example with AWS Lambda and CodeDeploy:
Assume a serverless application is deployed using AWS Lambda. AWS CodeDeploy can be used to manage the canary deployment.
The automation tool, CodeDeploy, is configured to:
- Deploy a new Lambda function version (the “green” version).
- Configure a traffic-shifting strategy (e.g., gradually shifting traffic over a period).
- Monitor CloudWatch metrics (e.g., error rates, invocation duration).
- Automatically rollback to the previous version if metrics exceed defined thresholds.
This setup enables a controlled rollout of the new version, allowing for early detection and mitigation of potential issues.
Designing a Diagram Illustrating the Traffic Flow During a Blue/Green Deployment
A blue/green deployment can be effectively visualized through a diagram illustrating the traffic flow.
Diagram Description:
The diagram depicts a time-based progression of a Blue/Green deployment. The top half represents the Blue environment (current production) and the bottom half the Green environment (new deployment). The central section shows the load balancer and traffic flow.
Initial State (Time 1):
- The “Blue” environment is active and handling 100% of the user traffic.
- The “Green” environment is inactive, potentially undergoing deployment or testing.
- The Load Balancer directs all incoming traffic to the “Blue” environment.
Deployment Phase (Time 2):
- The “Green” environment has been fully deployed with the new application version.
- The “Green” environment is undergoing testing.
- The Load Balancer still directs all traffic to the “Blue” environment.
Traffic Switch (Time 3):
- The Load Balancer is reconfigured to direct 100% of the traffic to the “Green” environment.
- The “Blue” environment is now idle.
Post-Deployment (Time 4):
- The “Green” environment is handling 100% of the user traffic.
- The “Blue” environment is decommissioned or kept as a backup for potential rollback.
Rollback Scenario (if required):
- If issues are detected in the “Green” environment, the Load Balancer can be swiftly reconfigured to switch traffic back to the “Blue” environment, enabling a quick rollback.
Diagram elements:
- Rectangles: Represent the “Blue” and “Green” environments. Each rectangle would contain a visual representation of the serverless application components (e.g., Lambda functions, API Gateway, database).
- Arrows: Indicate the flow of traffic from the load balancer to the environments. The arrows would change direction during the traffic switch.
- Load Balancer: A central element, visualized as a distinct shape, responsible for routing traffic.
- Labels: Clear labels would indicate the traffic percentage handled by each environment (e.g., 100% Blue, 0% Green; 0% Blue, 100% Green).
- Time axis: A horizontal time axis across the top of the diagram helps visualize the deployment phases.
Advanced Automation Techniques
Automating serverless application deployments extends beyond basic CI/CD pipelines. Advanced techniques significantly enhance efficiency, scalability, and security. These methods leverage dynamic resource allocation, automated testing, and secure configuration management to optimize the entire lifecycle of a serverless application. The following sections detail some of these advanced techniques.
Auto-Scaling and Automated Testing Frameworks
Auto-scaling and automated testing are crucial components of a robust serverless deployment strategy. Auto-scaling ensures applications can handle fluctuating workloads, while automated testing validates code changes before they reach production. These two elements work in tandem to provide a resilient and reliable system.Auto-scaling in serverless environments, such as AWS Lambda, is typically handled automatically by the cloud provider. However, configuration is still required.
The scaling behavior is often driven by metrics like the number of concurrent executions, invocation durations, or error rates.Automated testing frameworks are essential for validating code changes. These frameworks provide a structured approach to testing various aspects of the serverless application.
- Load Testing: Simulates high traffic to assess the application’s performance under stress. Tools like JMeter or Locust can be used to generate concurrent requests. This helps to identify bottlenecks and ensure the application can handle peak loads.
- Integration Testing: Verifies the interaction between different serverless functions and external services. This ensures that the application components work together correctly. Testing frameworks like Jest or Mocha can be used for this purpose.
- End-to-End (E2E) Testing: Simulates user interactions with the entire application, including the front-end, back-end, and any external services. Tools like Cypress or Selenium are commonly used for E2E testing. This verifies the overall functionality of the application from a user’s perspective.
Consider the example of an e-commerce serverless application. During a flash sale, the application may experience a sudden surge in traffic. Auto-scaling ensures that the Lambda functions handling product listings and order processing automatically scale up to handle the increased load. Simultaneously, automated tests continuously validate that new code deployments do not introduce errors or performance issues.
Environment Variables and Secrets Management
Environment variables and secrets management are critical for configuring serverless applications securely and efficiently. They allow for separating configuration data from the application code, making deployments more flexible and secure. This separation is particularly important in serverless environments, where the application often runs across multiple instances and in different environments (development, staging, production).Environment variables store configuration settings, such as database connection strings, API keys, and region settings.
Secrets management, on the other hand, is focused on securely storing and managing sensitive data like passwords and access tokens.Using environment variables promotes portability and simplifies configuration. They allow you to configure the application differently based on the environment it is running in without modifying the code.
- Centralized Secret Management: Using a secrets management service, such as AWS Secrets Manager or HashiCorp Vault, provides a secure and centralized way to store and manage secrets. These services offer features like versioning, access control, and automatic rotation of secrets.
- Dynamic Configuration: Environment variables can be updated without redeploying the entire application. This simplifies configuration changes and reduces downtime.
- Security: By keeping sensitive information separate from the code, the risk of accidentally exposing secrets in the code repository is significantly reduced.
A crucial aspect of secrets management is ensuring that secrets are not hardcoded in the application code or configuration files. Instead, they should be retrieved dynamically from a secrets management service during the application’s initialization.Here’s a code snippet demonstrating the use of environment variables in a serverless function written in Node.js:“`javascript// index.jsexports.handler = async (event) => const apiKey = process.env.API_KEY; const databaseUrl = process.env.DATABASE_URL; console.log(`API Key: $apiKey`); console.log(`Database URL: $databaseUrl`); // Your application logic here const response = statusCode: 200, body: JSON.stringify(‘Hello from Lambda!’), ; return response;;“`In this example, `API_KEY` and `DATABASE_URL` are environment variables.
These variables would be set during deployment, potentially using the infrastructure-as-code tool being used. The serverless function retrieves these values using `process.env`. This approach keeps the sensitive configuration details separate from the application code, thus improving security and facilitating configuration across different environments.
Concluding Remarks
In conclusion, the automation of serverless application deployments is not merely a best practice but a fundamental requirement for realizing the full potential of serverless computing. By leveraging the principles of IaC, CI/CD pipelines, robust monitoring, and strategic deployment strategies, organizations can significantly reduce operational overhead, accelerate time-to-market, and enhance the reliability of their serverless applications. This comprehensive approach ensures a future where serverless deployments are not just automated, but also optimized for performance, security, and scalability.
User Queries
What are the primary benefits of automating serverless deployments?
Automation reduces manual errors, accelerates deployment speed, improves consistency, and enables more frequent releases. It also facilitates easier rollbacks and simplifies scaling operations.
What are the key differences between AWS SAM, Serverless Framework, and Terraform for serverless deployments?
AWS SAM is specifically designed for AWS serverless services, offering tight integration and ease of use. The Serverless Framework supports multiple cloud providers and emphasizes a streamlined developer experience. Terraform provides infrastructure-as-code capabilities for a broader range of resources, including serverless, and excels in multi-cloud environments.
How does Infrastructure as Code (IaC) contribute to serverless deployment automation?
IaC allows you to define and manage your infrastructure using code, ensuring consistency, reproducibility, and version control. This approach eliminates manual configuration and enables automated deployments and rollbacks.
What is the role of monitoring and logging in an automated serverless environment?
Monitoring and logging are crucial for identifying issues, tracking performance, and ensuring the health of your serverless applications. They provide insights into application behavior and enable proactive problem-solving within automated deployments.
How can I implement a canary deployment strategy for my serverless applications?
A canary deployment involves gradually rolling out new versions to a small subset of users before a full release. Automation tools like AWS SAM, Serverless Framework, or Terraform can facilitate this by managing traffic routing and version switching, minimizing the impact of potential issues.